本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 R eady-to-use 模型进行预测
R eady-to-use 模型可用于文本、图像和文档数据。每种数据类型都有专为最适合每个用例而设计的 R eady-to-use 模型。使用以下指南来确定可以对输入数据使用哪些 R eady-to-use 模型:
-
文本数据:情绪分析、实体提取、语言检测、个人信息检测
-
图像数据:图像中的对象检测、图像中的文本检测
-
文档数据:费用分析、身份证件分析、文档分析、文档查询
以下屏幕截图显示了 R eady-to-use 模型的登录页面,其中展示了所有不同的解决方案。
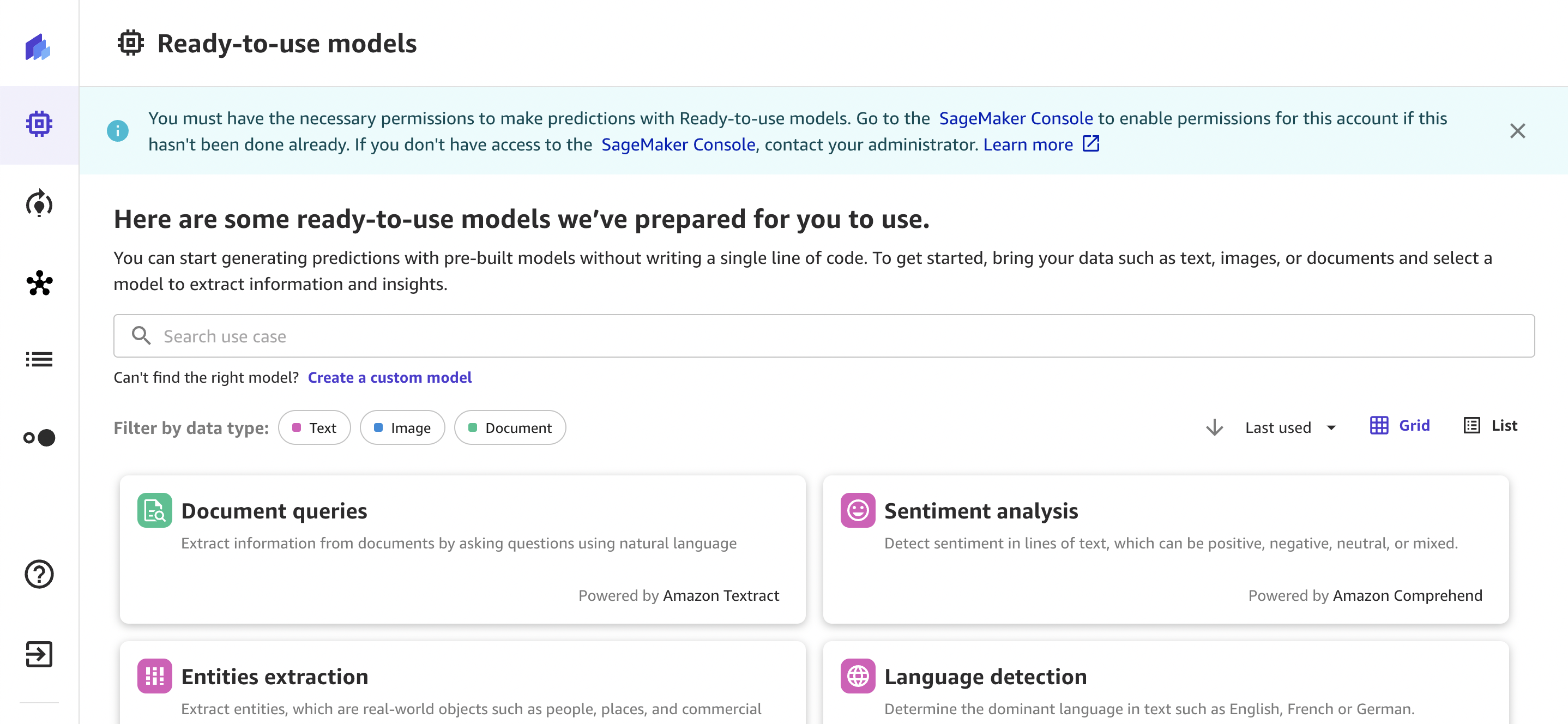
每个 R eady-to-use 模型都支持您的数据集的单一预测和批量预测。单一预测是指您只需进行一次预测。例如,您有一张图像要从中提取文本,或者有一段文本要检测其主要语言。批量预测是指您想对整个数据集进行预测。例如,您可能有一个包含客户评论的 CSV 文件,您想分析其中的客户情绪,或者您可能有想要在其中检测对象的图像文件。
获得数据并确定使用案例后,选择以下工作流之一对数据进行预测。
对文本数据进行预测
以下过程介绍如何对文本数据集进行单一预测和批量预测。您可以将这些过程用于以下 R eady-to-use 模型类型:情感分析、实体提取、语言检测和个人信息检测。
注意
对于情绪分析,您只能使用英语文本。
单一预测
要对接受文本数据的 R eady-to-use 模型进行单一预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择即用型模型。
-
在 R eady-to-use 模型页面上,为您的用例选择 R eady-to-use 模型。对于文本数据,应该是以下模型之一:情绪分析、实体提取、语言检测或个人信息检测。
-
在所选 R eady-to-use 模型的运行预测页面上,选择单一预测。
-
在文本字段中,输入您要预测的文本。
-
选择生成预测结果以获取您的预测结果。
在右侧窗格的预测结果中,除了每个结果或标签的置信度分数外,您还会收到对文本的分析。例如,如果您选择语言检测并输入一段法语文本,则法语的置信度分数可能为 95%,而其他语言(例如英语)的置信度分数为 5%。
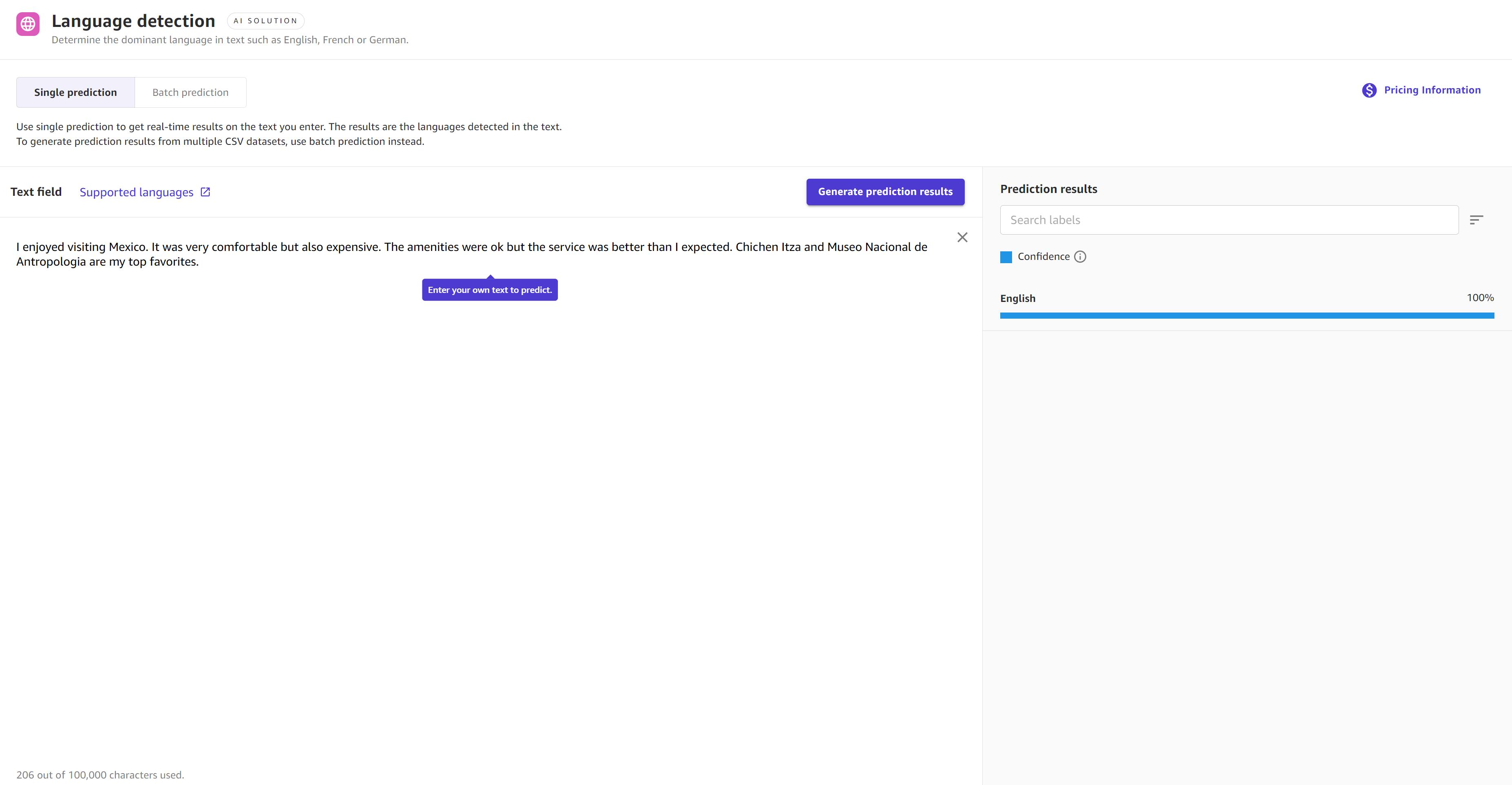
以下屏幕截图显示了使用语言检测进行单一预测的结果,其中模型 100% 确信段落是英语。
批量预测
要对接受文本数据的 R eady-to-use 模型进行批量预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择即用型模型。
-
在 R eady-to-use 模型页面上,为您的用例选择 R eady-to-use 模型。对于文本数据,应该是以下模型之一:情绪分析、实体提取、语言检测或个人信息检测。
-
在所选 R eady-to-use 模型的运行预测页面上,选择 B atch 预测。
-
如果您已经导入了数据集,请选定选择数据集。如果未导入,请选择导入新数据集,然后将引导您完成导入数据工作流。
-
从可用数据集列表中,选择您的数据集并选择生成预测以获取预测。
预测作业运行完毕后,在运行预测页面上,您会看到预测下列出了输出数据集。此数据集包含您的结果,如果您选择更多选项图标 (
![]() ),则可以预览输出数据。然后,您可以选择下载来下载结果。
),则可以预览输出数据。然后,您可以选择下载来下载结果。
对图像数据进行预测
以下过程介绍如何对图像数据集进行单一预测和批量预测。您可以对以下 R eady-to-use 模型类型使用这些程序:物体检测图像和图像中的文本检测。
单一预测
要对接受图像数据的 R eady-to-use 模型进行单一预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择即用型模型。
-
在 R eady-to-use 模型页面上,为您的用例选择 R eady-to-use 模型。对于图像数据,应该是以下模型之一:图像中的对象检测或图像中的文本检测。
-
在所选 R eady-to-use 模型的运行预测页面上,选择单一预测。
-
选择上传图像。
-
系统会提示您选择要从本地计算机上传的图像。从本地文件中选择图像,然后生成预测结果。
在右侧窗格的预测结果中,除了检测到的每个对象或文本的置信度分数外,您还会收到对图像的分析。例如,如果您选择图像中的对象检测,则会收到图像中对象的列表,以及模型对每个对象都被准确检测到的确定程度的置信度分数,例如 93%。
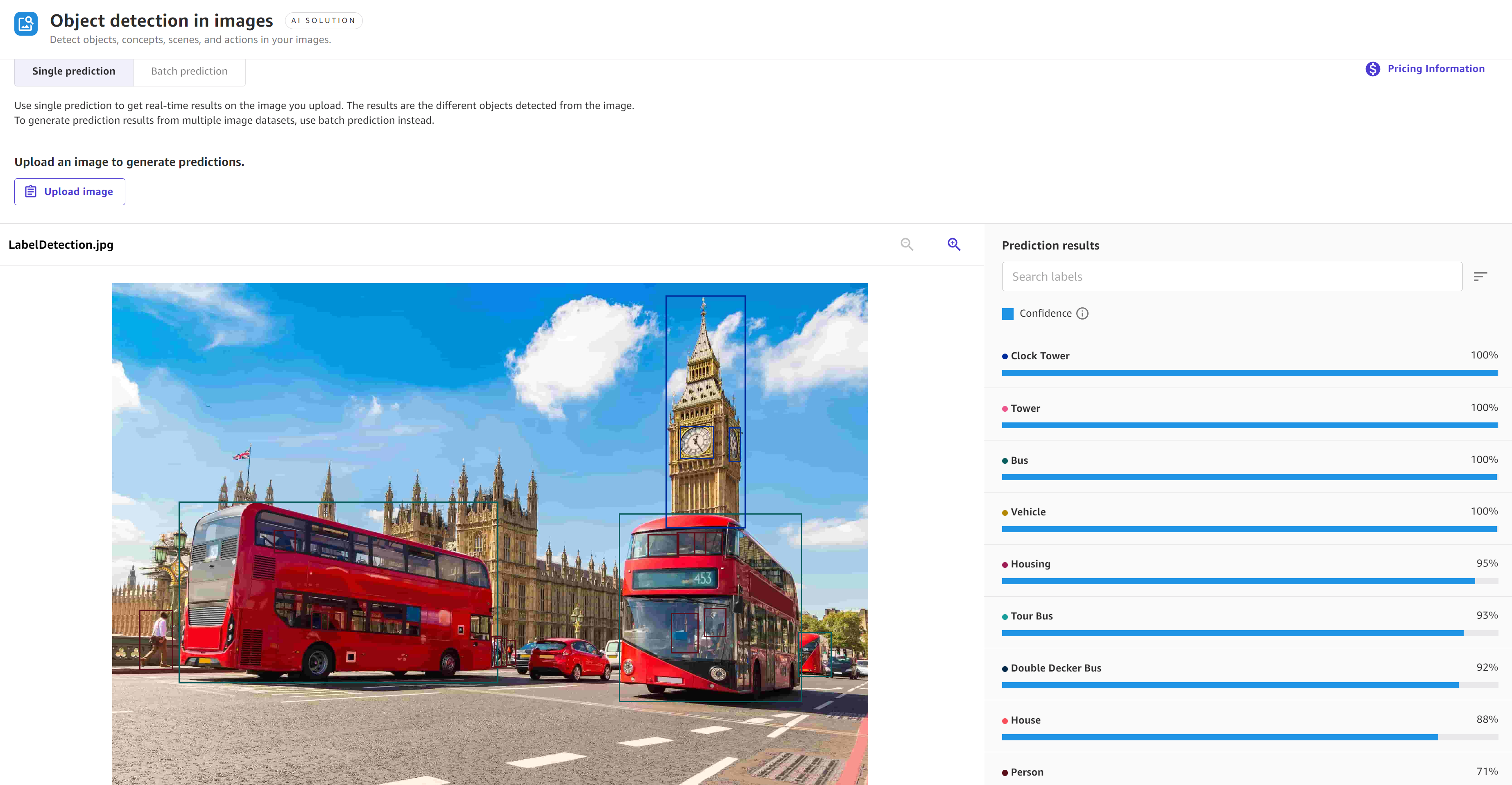
以下屏幕截图显示了使用图像中的对象检测解决方案进行单一预测的结果,其中模型以 100% 的置信度预测出钟楼和公交车等对象。
批量预测
要对接受图像数据的 R eady-to-use 模型进行批量预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择即用型模型。
-
在 R eady-to-use 模型页面上,为您的用例选择 R eady-to-use 模型。对于图像数据,应该是以下模型之一:图像中的对象检测或图像中的文本检测。
-
在所选 R eady-to-use 模型的运行预测页面上,选择 B atch 预测。
-
如果您已经导入了数据集,请选定选择数据集。如果未导入,请选择导入新数据集,然后将引导您完成导入数据工作流。
-
从可用数据集列表中,选择您的数据集并选择生成预测以获取预测。
预测作业运行完毕后,在运行预测页面上,您会看到预测下列出了输出数据集。此数据集包含您的结果,如果您选择更多选项图标 (
![]() ),则可以选择查看预测结果来预览输出数据。然后,您可以选择下载预测并将结果下载为 CSV 或 ZIP 文件。
),则可以选择查看预测结果来预览输出数据。然后,您可以选择下载预测并将结果下载为 CSV 或 ZIP 文件。
对文档数据进行预测
以下过程介绍如何对文档数据集进行单一预测和批量预测。您可以将这些过程用于以下 R eady-to-use 模型类型:费用分析、身份文件分析和文档分析。
注意
对于文档查询,目前仅支持单一预测。
单一预测
要对接受文档数据的 R eady-to-use 模型进行单一预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择即用型模型。
-
在 R eady-to-use 模型页面上,为您的用例选择 R eady-to-use 模型。对于文档数据,应该是以下模型之一:费用分析、身份证件分析或文档分析。
-
在所选 R eady-to-use 模型的运行预测页面上,选择单一预测。
-
如果您的 R eady-to-use 模型是身份证件分析或文档分析,请完成以下操作。如果您正在进行费用分析或文档查询,请跳过此步骤,分别转到步骤 5 或步骤 6。
-
选择上传文档。
-
系统会提示您从本地计算机上传 PDF、JPG 或 PNG 文件。从本地文件中选择文档,然后将生成预测结果。
-
-
如果您的 R eady-to-use 模型是费用分析,请执行以下操作:
-
选择上传发票或收据。
-
系统会提示您从本地计算机上传 PDF、JPG、PNG 或 TIFF 文件。从本地文件中选择文档,然后将生成预测结果。
-
-
如果您的 R eady-to-use 模型是文档查询,请执行以下操作:
-
选择上传文档。
-
系统会提示您从本地计算机上传 PDF 文件。从本地文件中选择文档。PDF 文件长度必须为 1-100 页。
注意
如果您位于亚太地区(首尔)、亚太地区(新加坡)、亚太地区(悉尼)或欧洲地区(法兰克福)这样的区域,则用于文档查询的最大 PDF 大小为 20 页。
-
在右侧窗格中,输入查询以搜索文档中的信息。单个查询中可以包含的字符数介于 1 到 200 之间。您一次最多可以添加 15 个查询。
-
选择提交查询,然后生成包含查询答案的结果。您每次提交查询都需要支付一次费用。
-
在右侧窗格的预测结果中,您将收到对文档的分析。
以下信息描述了每种解决方案的结果:
-
对于费用分析,将结果分为汇总字段(包括收据上的总额等字段)和行项目字段(包括收据上的单个项目等字段)。已识别的字段会在输出的文档图像上突出显示。
-
对于身份证件分析,输出显示了即用型模型识别的字段,例如名字和姓氏、地址或出生日期。已识别的字段会在输出的文档图像上突出显示。
-
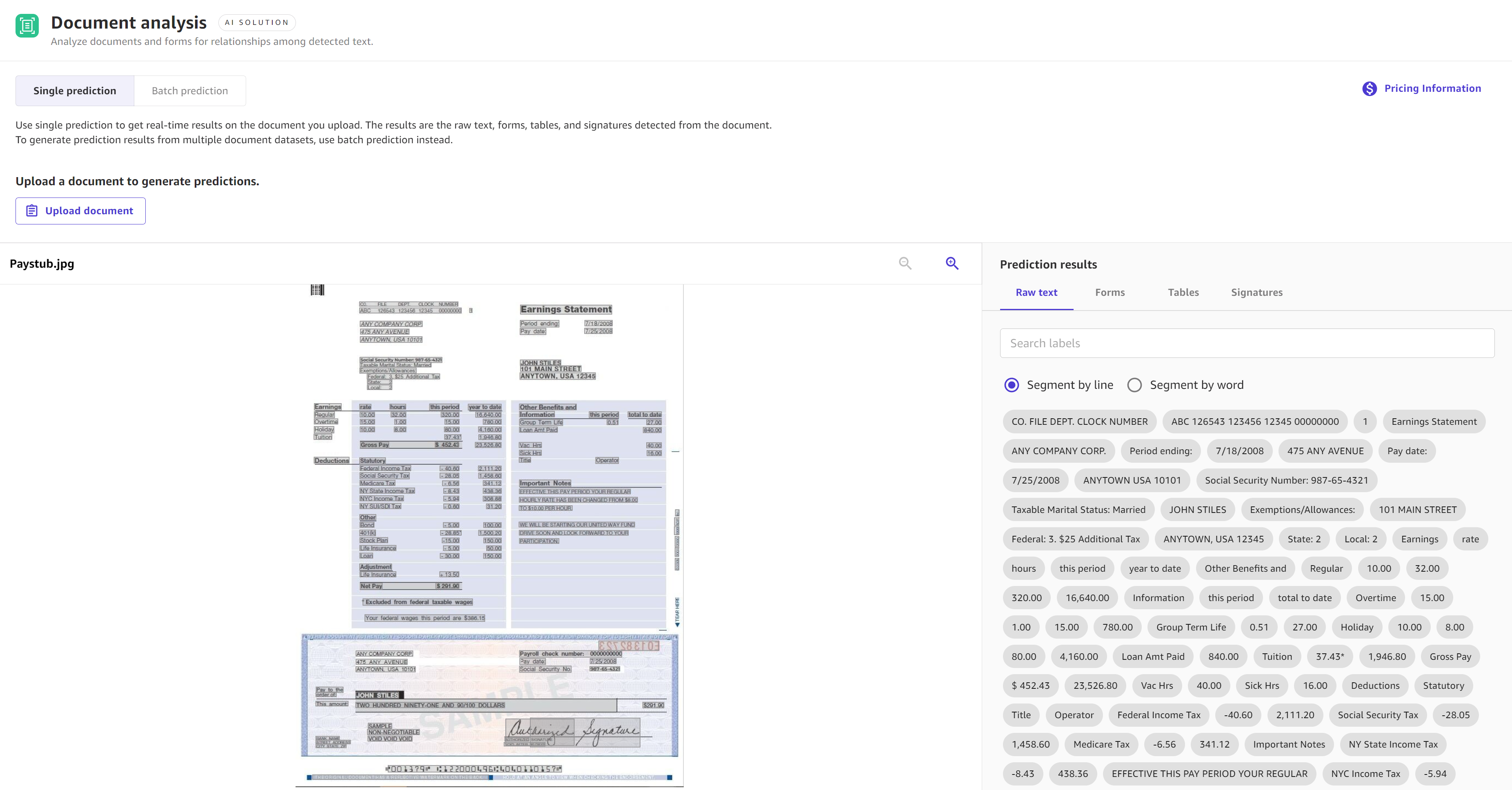
对于文档分析,将结果分为原始文本、表单、表格和签名。原始文本包括所有提取的文本,而表单、表格和签名仅包含属于这些类别的表单信息。例如,表格仅包含从文档中的表格中提取的信息。已识别的字段会在输出的文档图像上突出显示。
-
对于文档查询,Canvas 会返回每个查询的答案。您可以打开可折叠的查询下拉列表来查看结果以及预测的置信度分数。如果 Canvas 在文档中找到多个答案,则每个查询可能有多个结果。
以下屏幕截图显示了使用文档分析解决方案进行单一预测的结果。
批量预测
要对接受文档数据的 R eady-to-use 模型进行批量预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择即用型模型。
-
在 R eady-to-use 模型页面上,为您的用例选择 R eady-to-use 模型。对于图像数据,应该是以下模型之一:费用分析、身份证件分析或文档分析。
-
在所选 R eady-to-use 模型的运行预测页面上,选择 B atch 预测。
-
如果您已经导入了数据集,请选定选择数据集。如果未导入,请选择导入新数据集,然后将引导您完成导入数据工作流。
-
从可用数据集列表中,选择您的数据集并选择生成预测。如果您的使用案例是文档分析,请继续执行步骤 6。
-
(可选)如果您的使用案例是文档分析,则会出现另一个名为选择要包含在批量预测中的特征的对话框。您可以选择表单、表格和签名,按这些特征对结果进行分组。然后,选择生成预测。
预测作业运行完毕后,在运行预测页面上,您会看到预测下列出了输出数据集。此数据集包含您的结果,如果您选择更多选项图标 (
![]() ),则可以选择查看预测结果来预览文档数据的分析。
),则可以选择查看预测结果来预览文档数据的分析。
以下信息描述了每种解决方案的结果:
-
对于费用分析,将结果分为汇总字段(包括收据上的总额等字段)和行项目字段(包括收据上的单个项目等字段)。已识别的字段会在输出的文档图像上突出显示。
-
对于身份证件分析,输出显示了即用型模型识别的字段,例如名字和姓氏、地址或出生日期。已识别的字段会在输出的文档图像上突出显示。
-
对于文档分析,将结果分为原始文本、表单、表格和签名。原始文本包括所有提取的文本,而表单、表格和签名仅包含属于这些类别的表单信息。例如,表格仅包含从文档中的表格中提取的信息。已识别的字段会在输出的文档图像上突出显示。
预览结果后,您可以选择下载预测并将结果下载为 ZIP 文件。