本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
代码示例:SDK for Python
本节提供了创建和调用使用 SageMaker Clarify 在线可解释性的端点的示例代码。这些代码示例使用 Amazon SDK for Python
表格数据
以下示例使用表格数据和名model_name为的 A SageMaker I 模型。在本示例中,模型容器接受 CSV 格式的数据,并且每个记录都有四个数字特征。在此最低配置中,SHAP 基线数据设置为零,这只是为了演示目的。请参阅 SHAP 可解释性基准,了解如何为 ShapBaseline 选择更合适的值。
按照下面的方式配置端点:
endpoint_config_name = 'tabular_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '0,0,0,0', }, }, }, }, )
使用端点配置创建端点,如下所示:
endpoint_name = 'tabular_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
使用 DescribeEndpoint API 检查端点创建进度,如下所示:
response = sagemaker_client.describe_endpoint( EndpointName=endpoint_name, ) response['EndpointStatus']
在终端节点状态为 InService “” 后,使用测试记录调用终端节点,如下所示:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', )
注意
在上一个代码示例中,对于多模型端点,请在请求中传递一个附加的 TargetModel 参数,指定将哪个模型作为端点目标。
假设响应的状态代码为 200(无错误),并按以下方式加载响应正文:
import codecs import json json.load(codecs.getreader('utf-8')(response['Body']))
端点的默认操作是解释记录。下面显示了所返回的 JSON 对象中的示例输出。
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.0006380207487381" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [-0.00433456] } ] }, { "attributions": [ { "attribution": [-0.005369821] } ] }, { "attributions": [ { "attribution": [0.007917749] } ] }, { "attributions": [ { "attribution": [-0.00261214] } ] } ] ] } }
使用 EnableExplanations 参数启用按需解释功能,如下所示:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', EnableExplanations='[0]>`0.8`', )
注意
在上一个代码示例中,对于多模型端点,请在请求中传递一个附加的 TargetModel 参数,指定将哪个模型作为端点目标。
在本示例中,预测值小于阈值 0.8,因此不解释该记录:
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.6380207487381995" }, "explanations": {} }
使用可视化工具来协助说明所返回的解释。下图显示了如何使用 SHAP 图表来理解每个特征对预测的贡献。图表上的基值(也称为预期值)是训练数据集的平均预测值。将预期值推高的特征显示为红色,将预期值推低的特征显示为蓝色。有关更多信息,请参阅 SHAP 附加力布局
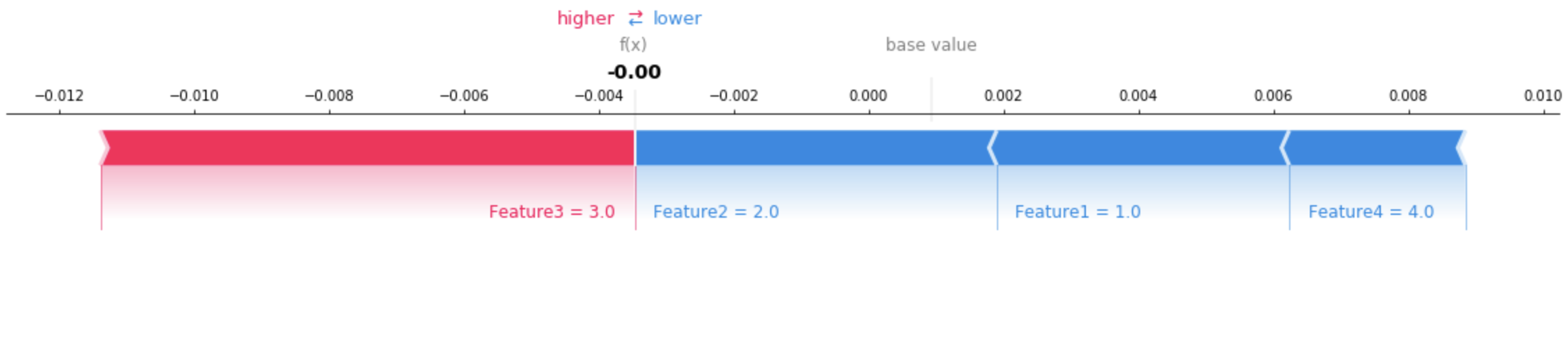
请参阅有关表格数据的完整示例笔记本
文本数据
此部分提供了一个代码示例,用于创建和调用文本数据的在线解释能力端点。本示例代码使用 SDK for Python。
以下示例使用文本数据和名为的 SageMaker AI 模型model_name。在此示例中,模型容器接受 CSV 格式的数据,并且每个记录都是一个字符串。
endpoint_config_name = 'text_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'InferenceConfig': { 'FeatureTypes': ['text'], 'MaxRecordCount': 100, }, 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '"<MASK>"', }, 'TextConfig': { 'Granularity': 'token', 'Language': 'en', }, 'NumberOfSamples': 100, }, }, }, )
-
ShapBaseline:为自然语言处理 (NLP) 处理保留的特殊令牌。 -
FeatureTypes:将特征标识为文本。如果未提供此参数,解释器将尝试推断特征类型。 -
TextConfig:指定文本特征分析的粒度单位和语言。在本示例中,语言为英语,粒度token表示英语文本中的一个单词。 -
NumberOfSamples:用于设置合成数据集的大小上限的限制。 -
MaxRecordCount:请求中可由模型容器处理的最大记录数。设置此参数是为了提供稳定的性能。
使用端点配置创建端点,如下所示:
endpoint_name = 'text_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
在端点状态变为 InService 后,调用该端点。下面的代码示例使用测试记录,如下所示:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='"This is a good product"', )
如果请求成功完成,响应正文将返回一个类似于如下内容的有效 JSON 对象:
{ "version": "1.0", "predictions": { "content_type": "text/csv", "data": "0.9766594\n" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [ -0.007270948666666712 ], "description": { "partial_text": "This", "start_idx": 0 } }, { "attribution": [ -0.018199033666666628 ], "description": { "partial_text": "is", "start_idx": 5 } }, { "attribution": [ 0.01970993241666666 ], "description": { "partial_text": "a", "start_idx": 8 } }, { "attribution": [ 0.1253469515833334 ], "description": { "partial_text": "good", "start_idx": 10 } }, { "attribution": [ 0.03291143366666657 ], "description": { "partial_text": "product", "start_idx": 15 } } ], "feature_type": "text" } ] ] } }
使用可视化工具来协助说明所返回的文本归因。下图显示了如何使用 captum 可视化实用程序来理解每个单词对预测的贡献。色彩饱和度越高,赋予单词的重要性就越高。在本示例中,高饱和度的亮红色表示强烈的负面共享。高饱和度的绿色表示强烈的积极贡献。白色表示单词的贡献是中性的。有关解析和渲染归因的更多信息,请参阅 captum

请参阅有关文本数据的完整示例笔记本