本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Clarify 进行在线解释 SageMaker
本指南介绍如何使用 Clarify 配置在线可 SageMaker 解释性。借 SageMaker 助 AI 实时推理端点,您可以实时、持续地分析可解释性。在线可解释性功能适合 A mazon A SageMaker I Machine Learning 工作流程的 “部署到生产环境” 部分。
Clarify 在线解释能力的工作方式
下图描述了用于托管提供可解释性请求的端点的 SageMaker AI 架构。它描绘了端点、模型容器和 Clarify 解释器之间的相互作用。 SageMaker
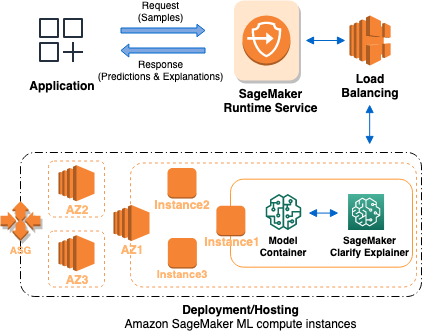
下面介绍 Clarify 在线解释能力的工作原理。应用程序向 A SageMaker I 运行时服务发送 REST-styleInvokeEndpoint请求。该服务将此请求路由到 A SageMaker I 终端节点以获取预测和解释。然后,该服务会收到来自端点的响应。最后,该服务会将响应发送回应用程序。
为了提高终端节点的可用性, SageMaker AI 会自动尝试根据终端节点配置中的实例数量在多个可用区中分配终端节点实例。在端点实例上,根据新的可解释性请求,Clarify 解释 SageMaker 器会调用模型容器进行预测。然后,解释器会计算并返回特征归因。
以下是创建使用 SageMaker Clarify 在线可解释性的端点的四个步骤:
-
使用 API 创建带有 Clari SageMaker fy 解释器配置的
CreateEndpointConfig端点配置。 -
使用 AP@@ I 创建终端节点并向 SageMaker A
CreateEndpointI 提供终端节点配置。该服务会启动 ML 计算实例,并按照配置中的规定部署模型。 -
调用终端节点:终端节点投入使用后,调用 SageMaker AI 运行时 API
InvokeEndpoint向终端节点发送请求。然后,端点返回解释和预测。