本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SageMaker AI 分布式数据并行库简介
SageMaker AI 分布式数据并行度 (SMDDP) 库是一个集体通信库,可提高分布式数据并行训练的计算性能。SMDDP 库通过提供以下功能来解决关键集体通信操作的通信开销问题。
-
该库
AllReduce针对以下内容进行了优化 Amazon。AllReduce是一项关键操作,用于在分布式数据训练期间每次训练迭代结束时同步各个 GPU 的梯度。 -
该库
AllGather针对以下内容进行了优化 Amazon。AllGather是分片数据并行训练中使用的另一项关键操作,它是 SageMaker AI 模型并行度 (SMP) 库、 DeepSpeed 零冗余优化器 (ZerO) 和完全分片数据并行度 (FSDP) 等热门库提供的内存效率高的数据并行处理技术。 PyTorch -
该库通过充分利用 Amazon 网络基础设施和 Amazon EC2 实例拓扑来执行优化的节点到节点通信。
SMDDP 库可以在扩展训练集群时提高性能,以近乎线性的扩展效率提高训练速度。
注意
SageMaker 人工智能分布式训练库可通过训练平台中的 Amazon 深度学习容器 PyTorch 和 Hugging Face SageMaker 获得。要使用这些库,你必须使用 SageMaker Python SDK 或通过 Python SDK (Boto3) 或 SageMaker API。 Amazon Command Line Interface在整篇文档中,说明和示例侧重于如何在 SageMaker Python SDK 中使用分布式训练库。
SMDDP 集体通信操作针对以下方面进行了优化 Amazon 计算资源和网络基础架构
SMDDP 库提供了针对 Amazon 计算资源AllReduce和网络基础架构进行了优化的AllGather集合操作的实现。
SMDDP AllReduce 集体操作
SMDDP 库实现了 AllReduce 操作与后向传递的最佳重叠,大大提高了 GPU 的利用率。它通过优化 CPU 和 GPU 之间的内核操作,实现了近乎线性的扩展效率和更快的训练速度。该库在 GPU 计算梯度时并行执行 AllReduce,而不会占用额外的 GPU 周期,这使得该库能实现更快的训练。
-
使用 CPU:该库使用 CPU 来
AllReduce梯度,从而卸载了 GPU 的这项任务。 -
提高 GPU 使用率:集群的 GPU 专门用于计算梯度,从而在整个训练过程中提高其利用率。
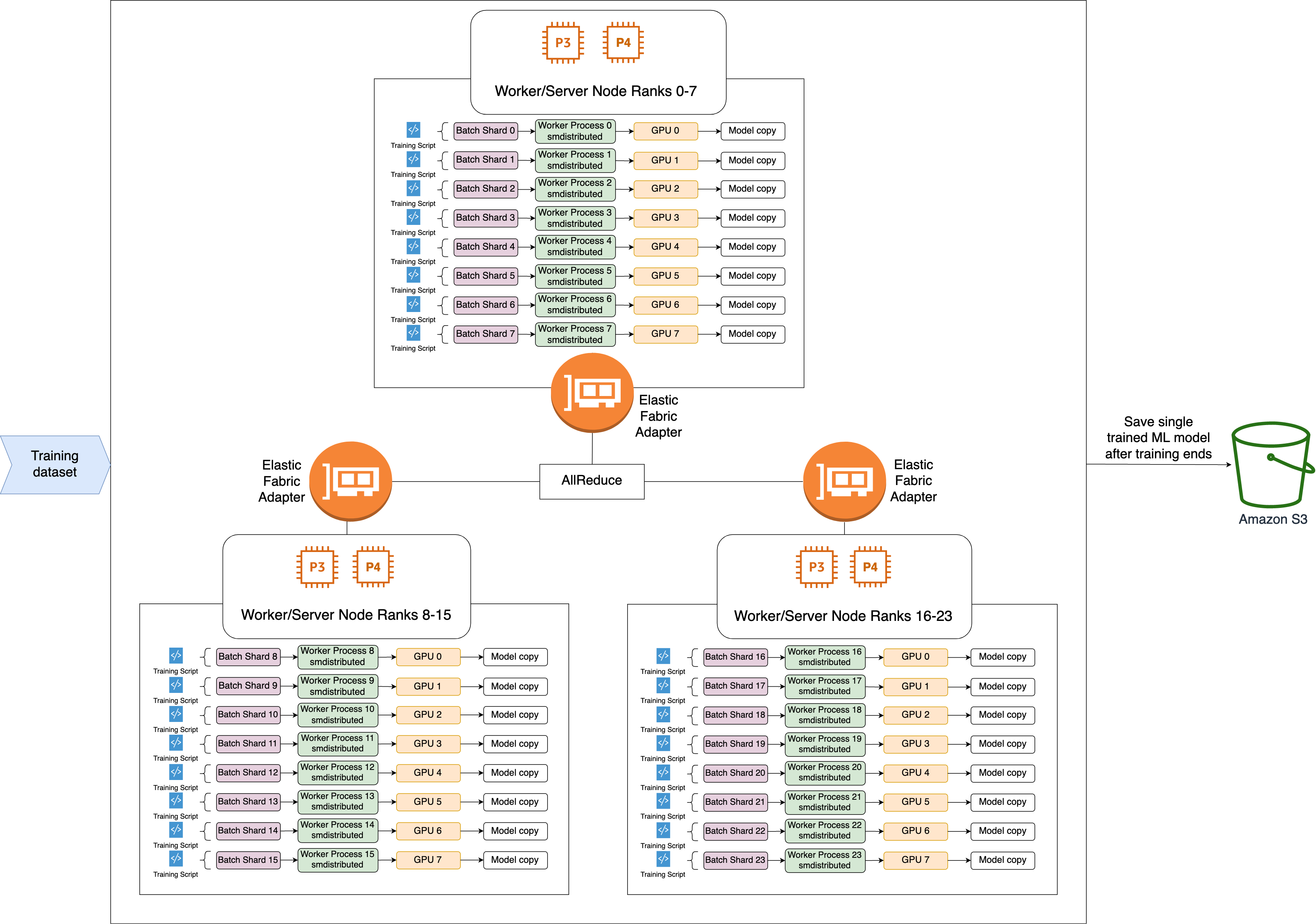
以下是 SMDDP AllReduce 操作的高级工作流程。
-
该库将秩分配给 GPU(工作线程)。
-
每次迭代时,库都会将每个全局批次除以工作线程总数(世界大小),然后将小批次(批次分片)分配给工作线程。
-
全局批次的大小为
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard)。 -
批次分片(小批次)是每次迭代分配给每个 GPU(工作线程)的数据集的子集。
-
-
该库会为每个工作线程启动训练脚本。
-
库在每次迭代结束时,管理来自工作线程的模型权重和梯度的副本。
-
库可同步各工作线程的模型权重和梯度,以聚合成为单个经过训练的模型。
以下架构图显示了该库如何为由 3 个节点组成的集群设置数据并行性的示例。
SMDDP AllGather 集体操作
AllGather 是一种集体操作,每个工作者从一个输入缓冲区开始,然后将所有其他工作者的输入缓冲区串联或聚合成一个输出缓冲区。
注意
SMDDP AllGather 集体操作已在 PyTorch v2.0.1 smdistributed-dataparallel>=2.0.1 及更高版本的 Deep Lear Amazon ning Containers (DLC) 中提供。
AllGather 在分布式训练技术中被大量使用,例如分片数据并行技术,在这种技术中,每个工作者都持有模型的一部分,或者一个分片层。工作线程会在向前和向后传递之前调用 AllGather,以重建分片层。在参数全部收集后,继续向前传递和向后传递。在后向传递过程中,每个工作线程也会调用 ReduceScatter 来收集(减少)梯度并将其分解(分散)为梯度碎片,以更新相应的碎片层。有关这些集体操作在分片数据并行性中的作用的更多详细信息,请参阅 SMP 库关于分片数据并行性的实现、 DeepSpeed文档中的 ZerO
由于每次迭代 AllGather 都会调用诸如此类的集体操作,因此它们是 GPU 通信开销的主要来源。这些集体操作的计算速度越快,训练时间就越短,而且不会对收敛性产生副作用。为此,SMDDP 库提供了针对 P4d 实例AllGather。
SMDDP AllGather 使用以下技术来提高 P4d 实例的计算性能。
-
它通过具有网状拓扑结构的 Elastic Fabric Adapter(EFA)
网络在实例之间(节点间)传输数据。EFA 是一种 Amazon 低延迟、高吞吐量的网络解决方案。节点间网络通信的网状拓扑更适合 EFA 和 Amazon 网络基础设施的特性。与涉及多次数据包跳转的 NCCL 环形或树形拓扑相比,SMDDP 只需一次跳转,从而避免了多次跳转带来的延迟累积。SMDDP 实现了一种网络速率控制算法,可平衡网状拓扑中每个通信对等节点的工作负载,并实现更高的全局网络吞吐量。 -
它采用基于 NVIDIA GPUDirect RDMA 技术(GDRCopy)的低延迟 GPU 内存拷贝库
来协调本地 NVLink 和 EFA 网络流量。GDRCopy 是 NVIDIA 提供的低延迟 GPU 内存复制库,可在 CPU 进程和 GPU CUDA 内核之间提供低延迟通信。利用这项技术,SMDDP 库就能对节点内和节点间的数据移动进行管道化处理。 -
它减少了 GPU 流式多处理器的使用,从而提高了运行模型内核的计算能力。P4d 和 P4de 实例配备了 NVIDIA A100 GPU,每个 GPU 有 108 个流式多处理器。NCCL 最多需要 24 个流式多处理器来运行集体操作,而 SMDDP 使用的流式多处理器不到 9 个。模型计算内核可利用保存的流式多处理器加快计算速度。