本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在中可视化 Amazon SageMaker Debugger 输出张量 TensorBoard
重要
本页面已被弃用,取而代之的是使用 SageMaker Amazon AI TensoBoard,它提供了与 A SageMaker I 域的 SageMaker 培训和访问控制功能集成的全面 TensorBoard 体验。要了解更多信息,请参阅TensorBoard 在亚马逊 A SageMaker I 中。
使用 SageMaker Debugger 创建与兼容的输出张量文件。 TensorBoard加载文件以可视化 TensorBoard 并分析您的 SageMaker 训练作业。调试器会自动生成与兼容的输出张量文件。 TensorBoard对于您为保存输出张量而自定义的任何挂钩配置,Debugger 可以灵活地创建可以导入的标量摘要、分布和直方图。 TensorBoard
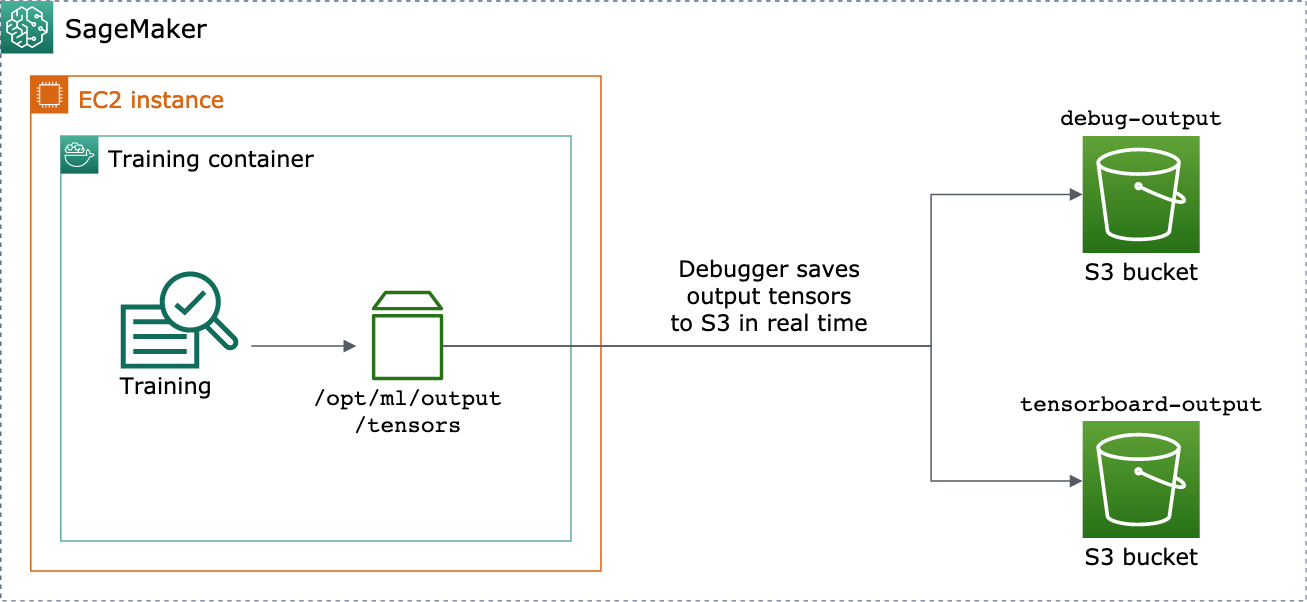
您可以通过将 DebuggerHookConfig 和 TensorBoardOutputConfig 对象传递到 estimator 来启用此功能。
以下过程说明了如何将标量、权重和偏差保存为可视化的完整张量、直方图和分布。 TensorBoardDebugger 将它们保存到训练容器的本地路径(默认路径为 /opt/ml/output/tensors),并同步到通过 Debugger 输出配置对象传递的 Amazon S3 位置。
使用调试 TensorBoard 器保存兼容的输出张量文件
-
使用 Debugger
TensorBoardOutputConfig类设置tensorboard_output_config配置对象以保存 TensorBoard 输出。对于s3_output_path参数,请指定当前 SageMaker AI 会话的默认 S3 存储桶或首选 S3 存储桶。此示例不会添加container_local_output_path参数;相反,它被设置为默认的本地路径/opt/ml/output/tensors。import sagemaker from sagemaker.debugger import TensorBoardOutputConfig bucket = sagemaker.Session().default_bucket() tensorboard_output_config = TensorBoardOutputConfig( s3_output_path='s3://{}'.format(bucket) )有关更多信息,请参阅 Amaz SageMaker on Python 软件开发工具包
中的调试器 TensorBoardOutputConfigAPI。 -
配置 Debugger 钩子并自定义挂钩参数值。例如,以下代码将 Debugger 钩子配置为在训练阶段每 100 步保存一次所有标量输出,在验证阶段每 10 步保存一次所有标量输出,每 500 步保存一次
weights参数(保存张量集合的默认save_interval值为 500),每 10 个全局步骤保存一次bias参数,直到全局步骤数达到 500。from sagemaker.debugger import CollectionConfig, DebuggerHookConfig hook_config = DebuggerHookConfig( hook_parameters={ "train.save_interval": "100", "eval.save_interval": "10" }, collection_configs=[ CollectionConfig("weights"), CollectionConfig( name="biases", parameters={ "save_interval": "10", "end_step": "500", "save_histogram": "True" } ), ] )有关调试器配置 API 的更多信息,请参阅 Amaz on Pyth SageMaker on
软件开发工具包中的调试器 CollectionConfig和DebuggerHookConfigAPI。 -
使用传递配置 SageMaker 对象的调试器参数构造一个 AI 估计器。以下示例模板展示了如何创建通用 SageMaker AI 估算器。你可以
Estimator用其他 SageMaker AI 框架的估算器父类estimator和估算器类替换和。此功能的可用的 SageMaker AI 框架估算器有TensorFlowPyTorch、和。MXNetfrom sagemaker.estimatorimportEstimatorestimator =Estimator( ... # Debugger parameters debugger_hook_config=hook_config, tensorboard_output_config=tensorboard_output_config ) estimator.fit()该
estimator.fit()方法启动训练作业,然后 Debugger 将输出张量文件实时写入调试器 S3 输出路径和 S3 输出路径。 TensorBoard 要检索输出路径,请使用以下估算器方法:-
对于 Debugger S3 输出路径,请使用
estimator.latest_job_debugger_artifacts_path()。 -
对于 S TensorBoard 3 输出路径,请使用
estimator.latest_job_tensorboard_artifacts_path()。
-
-
训练完成后,请检查保存的输出张量的名称:
from smdebug.trials import create_trial trial = create_trial(estimator.latest_job_debugger_artifacts_path()) trial.tensor_names() -
检查 Amazon S3 中的 TensorBoard 输出数据:
tensorboard_output_path=estimator.latest_job_tensorboard_artifacts_path() print(tensorboard_output_path) !aws s3 ls {tensorboard_output_path}/ -
将 TensorBoard 输出数据下载到您的笔记本实例。例如,以下 Amazon CLI 命令将 TensorBoard 文件下载到笔记本实例的当前工作目录
/logs/fit下。!aws s3 cp --recursive {tensorboard_output_path}./logs/fit -
将文件目录压缩为 TAR 文件以下载到本地计算机。
!tar -cf logs.tar logs -
将 Tensorboard TAR 文件下载并解压缩到设备上的某个目录中,启动 Jupyter 笔记本服务器,打开一个新的笔记本,然后运行该应用程序。 TensorBoard
!tar -xf logs.tar %load_ext tensorboard %tensorboard --logdir logs/fit
以下动画屏幕截图介绍了步骤 5 至 8。它演示了如何下载 Debugger TensorBoard TAR 文件并将该文件加载到本地设备上的 Jupyter 笔记本中。