本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Debugger 高级演示和可视化
以下演示将引导您了解使用 Debugger 的高级应用场景和可视化脚本。
主题
使用 Amazon SageMaker 实验和调试器训练和修剪模型
Amazon 应用科学家 Nathalie Rauschmayr 博士 | 时长:49 分 26 秒
了解 Amazon SageMaker 实验和调试器如何简化训练作业的管理。Amazon SageMaker Debugger 提供对训练作业的透明可见性,并将训练指标保存到您的 Amazon S3 存储桶中。 SageMaker 实验使您可以通过 SageMaker Studio 将训练信息作为试用调用,并支持训练作业的可视化。这有助于保持高质量的模型,同时根据重要性排名来减少不太重要的参数。
本视频演示了一种模型修剪技术,该技术使预训练的 ResNet 50 和 AlexNet 模型更轻、更实惠,同时保持模型精度的高标准。
SageMaker AI Estimator 在带有 PyTorch 框架的 Dee Amazon p Learning Containers 中训练 PyTorch 模型库中提供的算法,Debugger 则从训练过程中提取训练指标。
该视频还演示了如何设置调试器自定义规则,以观察修剪后的模型的精度,在精度达到阈值时触发 Amazon CloudWatch 事件和 Amazon Lambda 函数,以及如何自动停止修剪过程以避免冗余迭代。
学习目标如下:
-
学习如何使用 SageMaker AI 来加速 ML 模型训练并提高模型质量。
-
通过自动捕获输入参数、配置和结果,了解如何使用 SageMaker 实验管理训练迭代。
-
了解 Debugger 如何通过自动从卷积神经网络的权重、梯度和激活输出等指标中捕获实时张量数据,使训练过程变得透明。
-
用于 CloudWatch 在调试器发现问题时触发 Lambda。
-
使用 SageMaker 实验和调试器掌握 SageMaker 训练过程。
你可以从 D SageMaker ebugger I PyTorch terative Model
下图显示了迭代模型修剪过程如何根据激活输出和梯度评估的重要性 AlexNet 等级剪掉 100 个最不重要的滤波器,从而减小的大小。
修剪过程将最初的 5000 万个参数减少到 1800 万个。它还将估计的模型大小从 201 MB 减少到 73 MB。
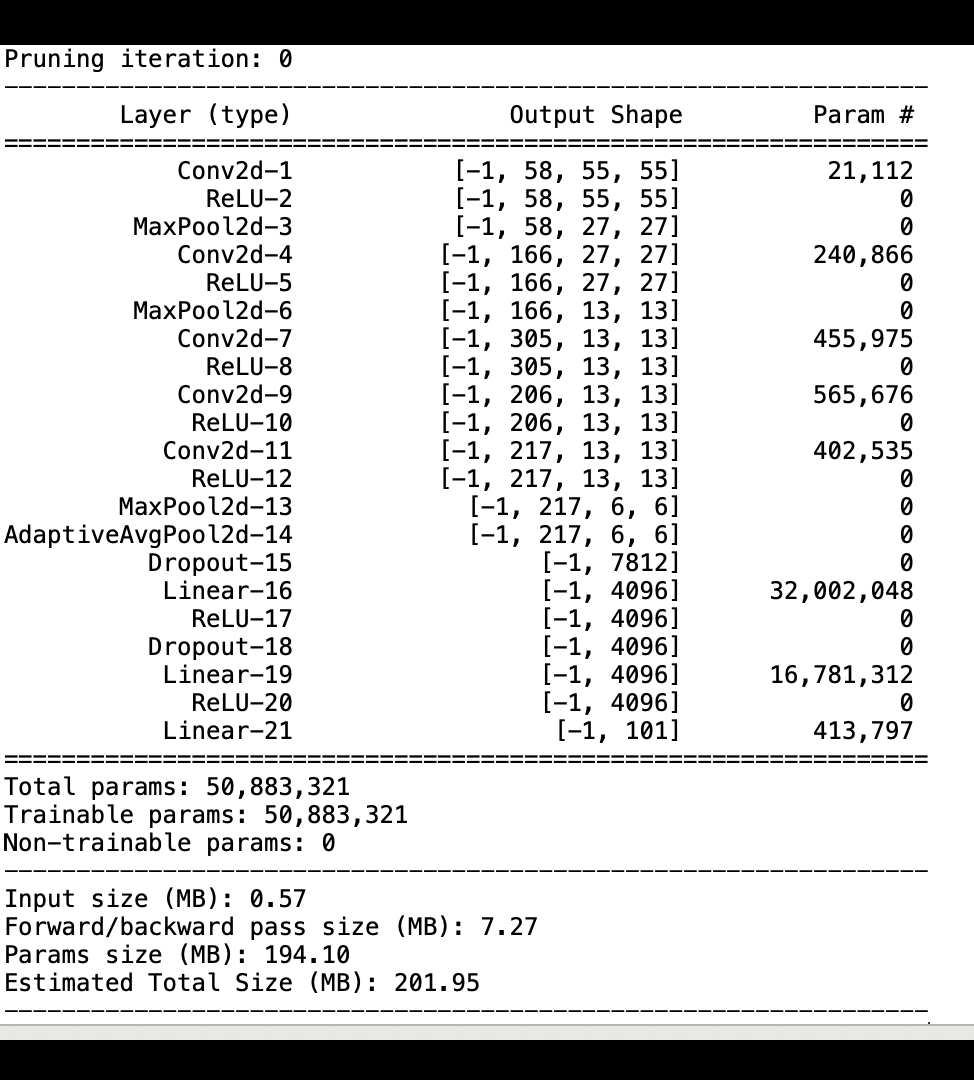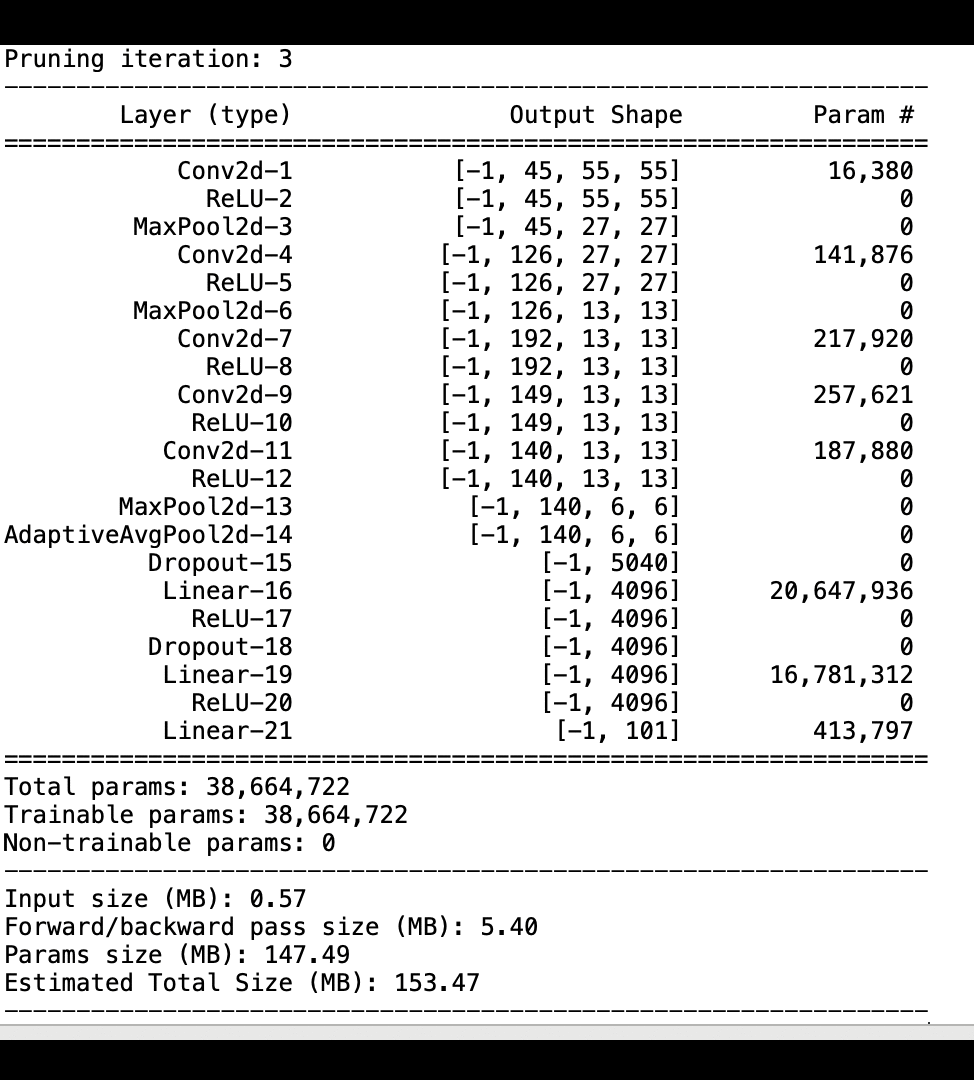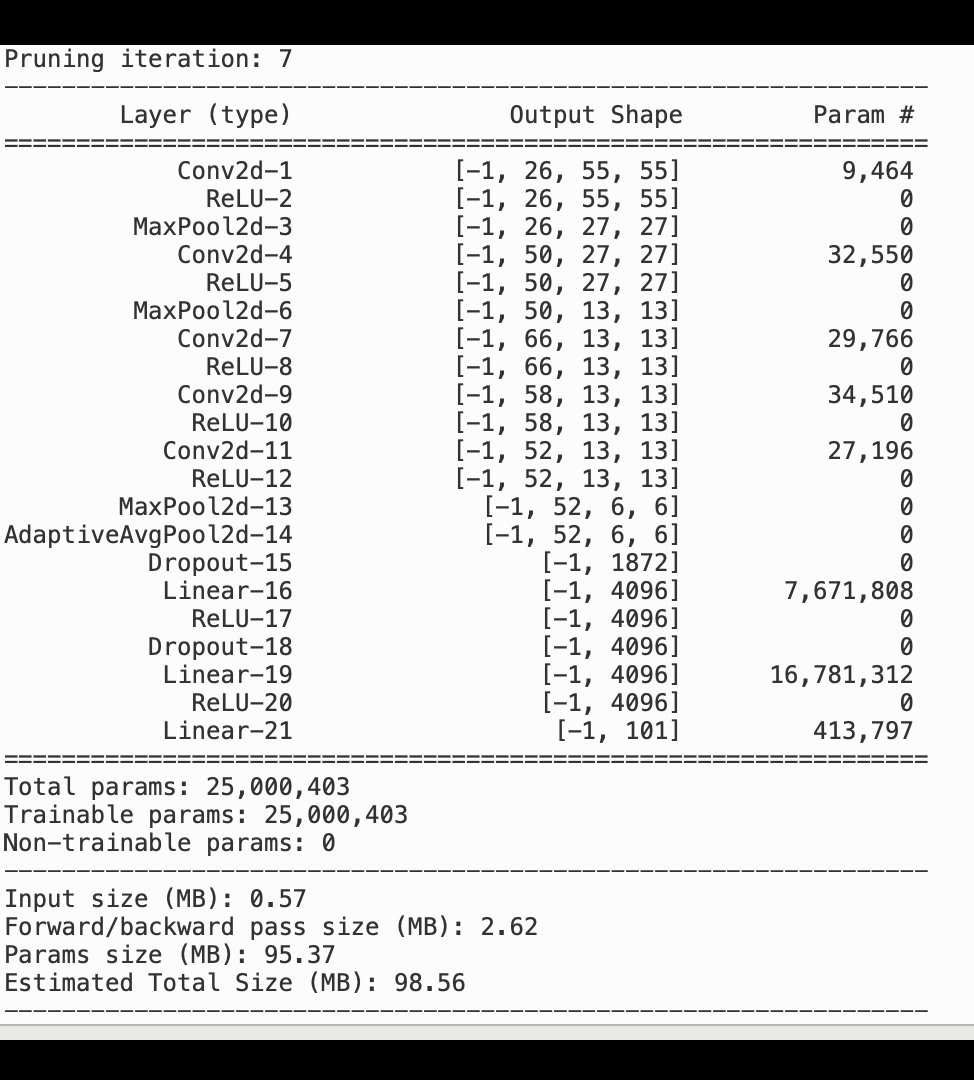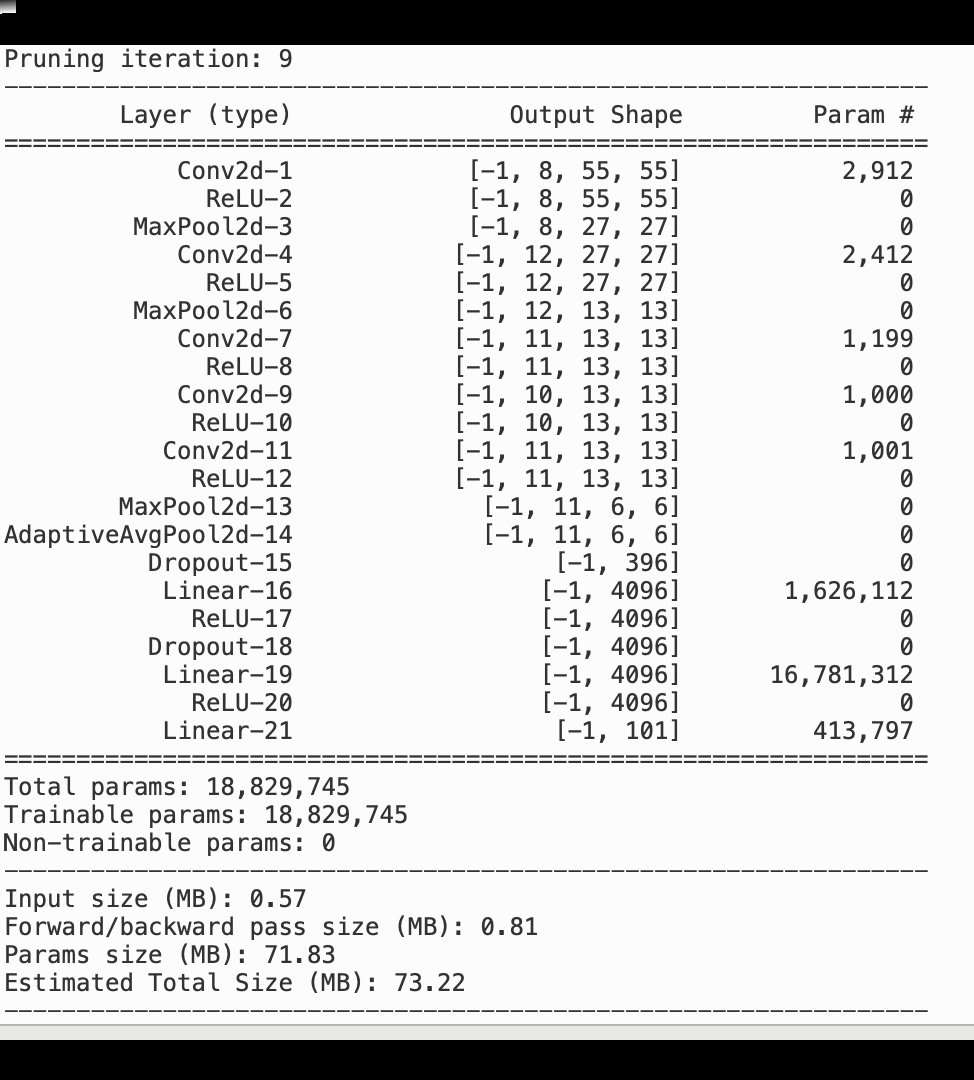
您还需要跟踪模型精度,下图显示了如何绘制模型修剪过程,以便根据 Studio 中的 SageMaker 参数数量可视化模型精度的变化。
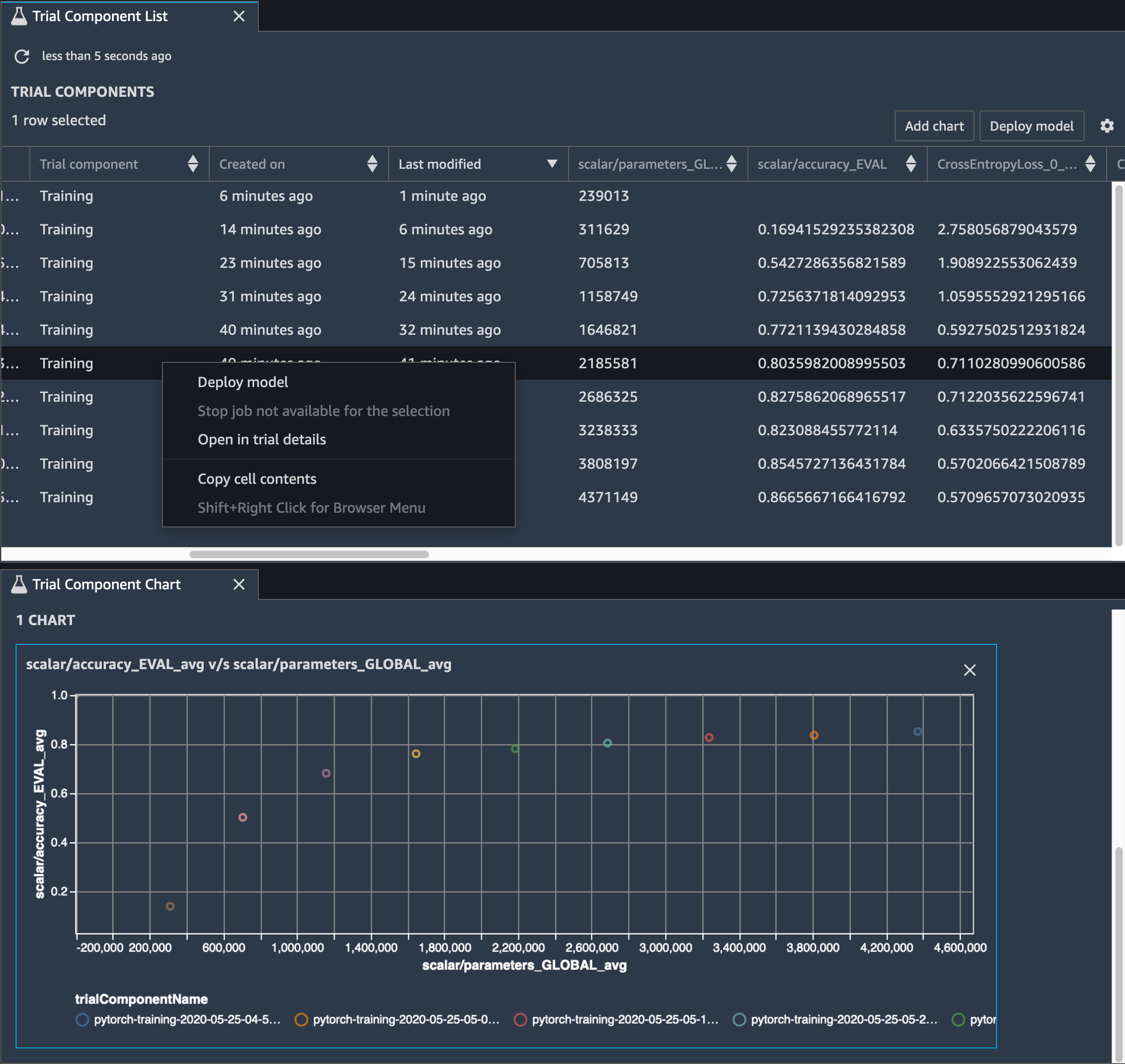
在 SageMaker Studio 中,选择 “实验” 选项卡,从修剪过程中选择 Debugger 保存的张量列表,然后编写 “试用组件列表” 面板。选择所有 10 个迭代,然后选择添加图表以创建试验组件图表。在确定了要部署的模型之后,选择试验组件并选择菜单以执行操作,或者选择部署模型。
注意
要使用以下笔记本示例通过 SageMaker Studio 部署模型,请在train.py脚本的train函数末尾添加一行。
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
使用 SageMaker Debugger 监控卷积自动编码器模型训练
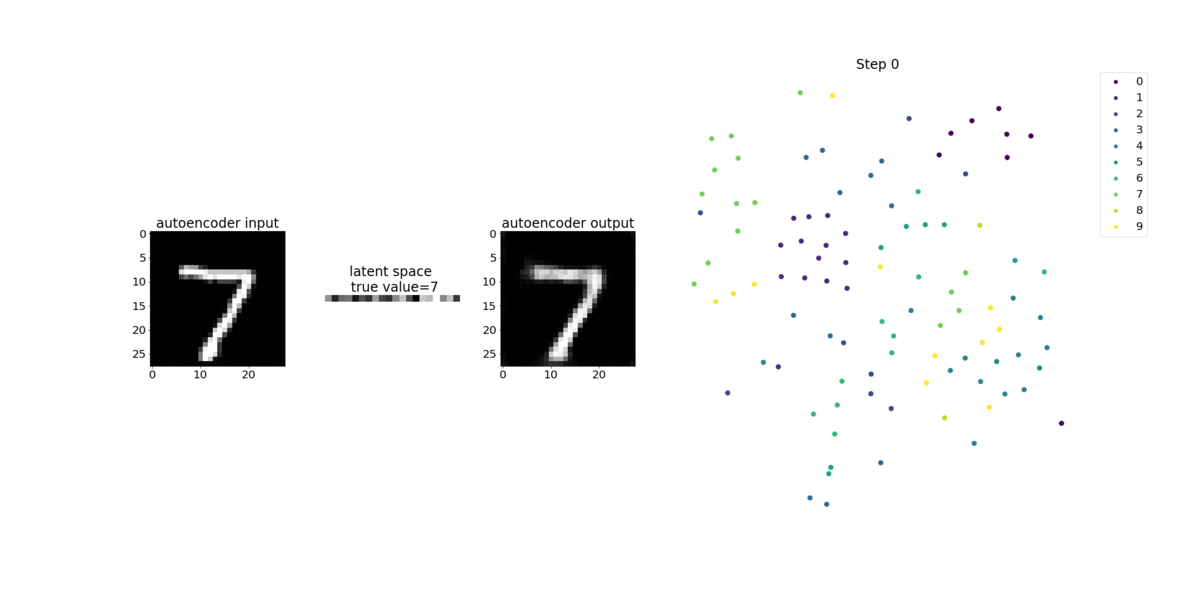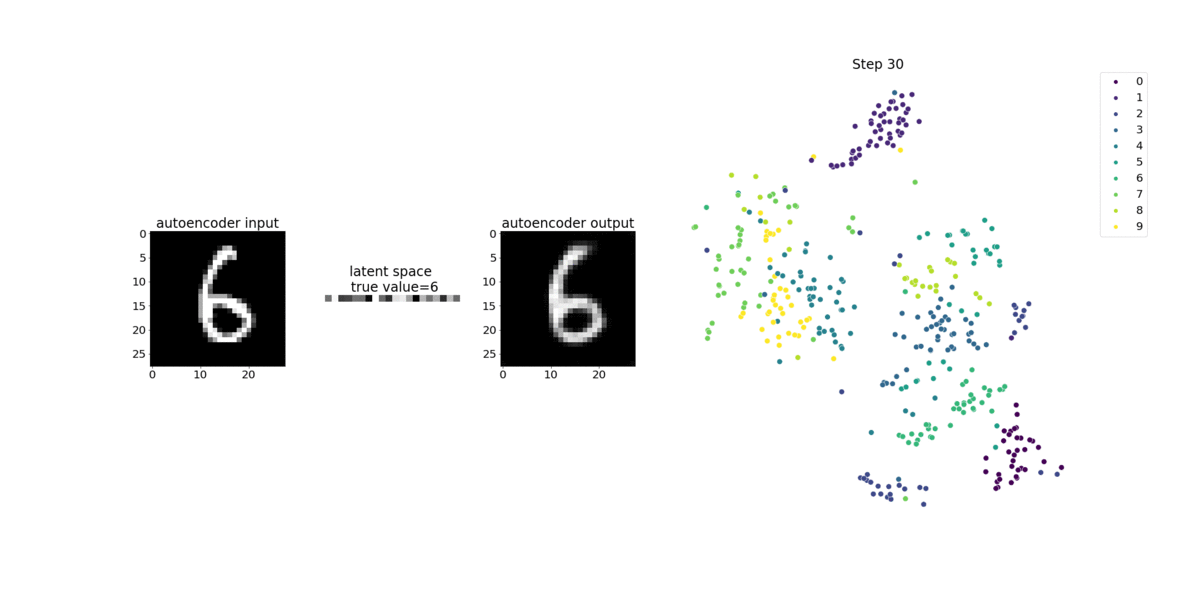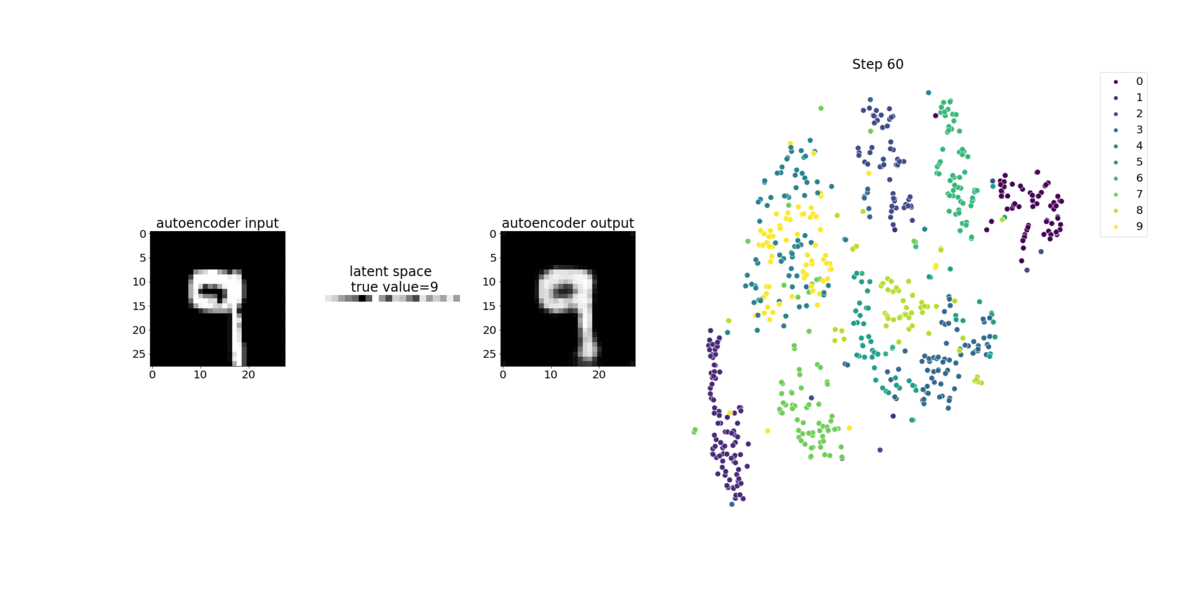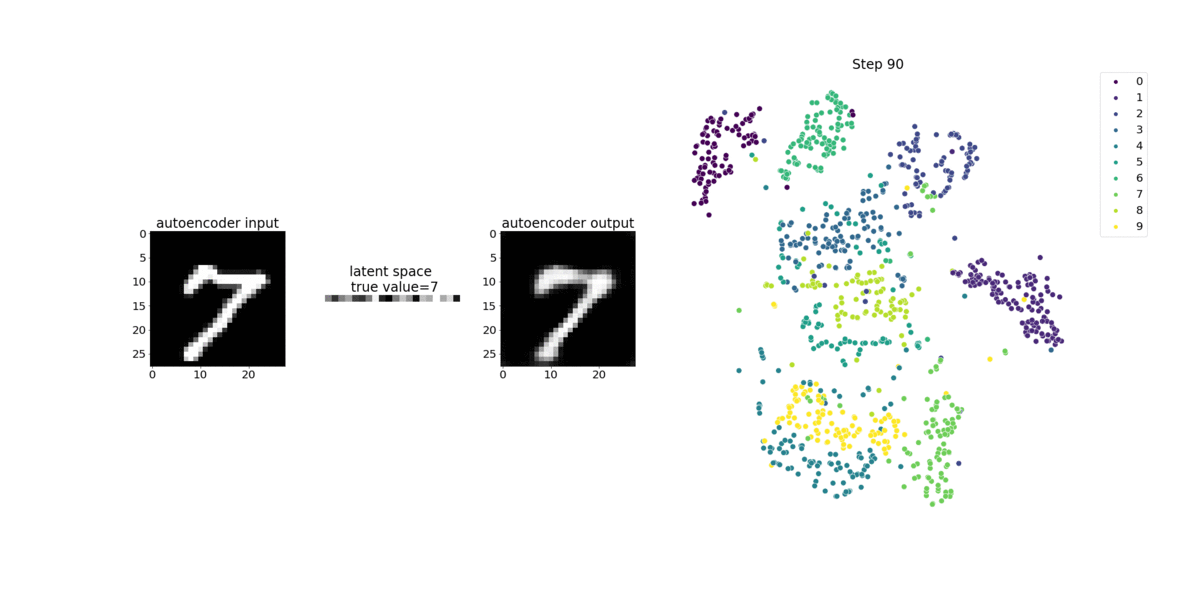
本笔记本演示了 SageMaker Debugger 如何在 MNIST 手写数字图像数据集上可视化来自无监督(或自监督)学习过程的张量。
本笔记本中的训练模型是一个带有 MXNet 框架的卷积自动编码器。卷积自动编码器具有瓶颈形状的卷积神经网络,由编码器部分和解码器部分组成。
此示例中的编码器具有两个卷积层,以生成输入图像的压缩表示(潜在变量)。在这种情况下,编码器从大小(28,28)的原始输入图像中生成大小(1,20)的潜在变量,并显著减少训练数据的大小达 40 倍。
解码器有两个解卷积层,并通过重建输出图像来确保潜在变量保留关键信息。
卷积编码器支持具有较小输入数据大小的聚类算法,并可提升聚类算法(例如 k-means、k-NN 和 t-Distributed Stochastic Neighbor (t-SNE) 嵌入)的性能。
此笔记本示例演示如何使用 Debugger 来可视化潜在变量,如下面的动画所示。它还演示 t-SNE 算法如何将潜在变量分为十个聚类并将它们投影到二维空间中。图像右侧的散点图颜色方案反映了真实值,以显示 BERT 模型和 t-SNE 算法将潜在变量组织到聚类中的程度。
使用 SageMaker 调试器监控 BERT 模型训练中的注意力
来自转换器的双向编码表示 (BERT) 是一种语言表示模型。正如模型名称所反映的那样,BERT 模型建立在用于自然语言处理 (NLP) 的迁移学习和转换器模型之上。
BERT 模型接受了不受监督任务的预训练,例如,预测句子中缺失的单词或预测自然接在前一个句子之后的下一个句子。训练数据包含 33 亿个单词(凭排)的英文文本,如维基百科和电子书籍。对于一个简单的例子,BERT 模型可以高度注意来自主题令牌的适当动词令牌或代词令牌。
预先训练的 BERT 模型可以通过额外的输出层进行微调,以便在 NLP 任务中实现先进的模型训练,例如自动响应问题、文本分类等。
Debugger 从微调过程中收集张量。在 NLP 的上下文下,神经元的权重被称为注意力。
本笔记本演示了如何在斯坦福问答数据集中使用 GluonNLP 模型库中的预训练的 BERT 模型
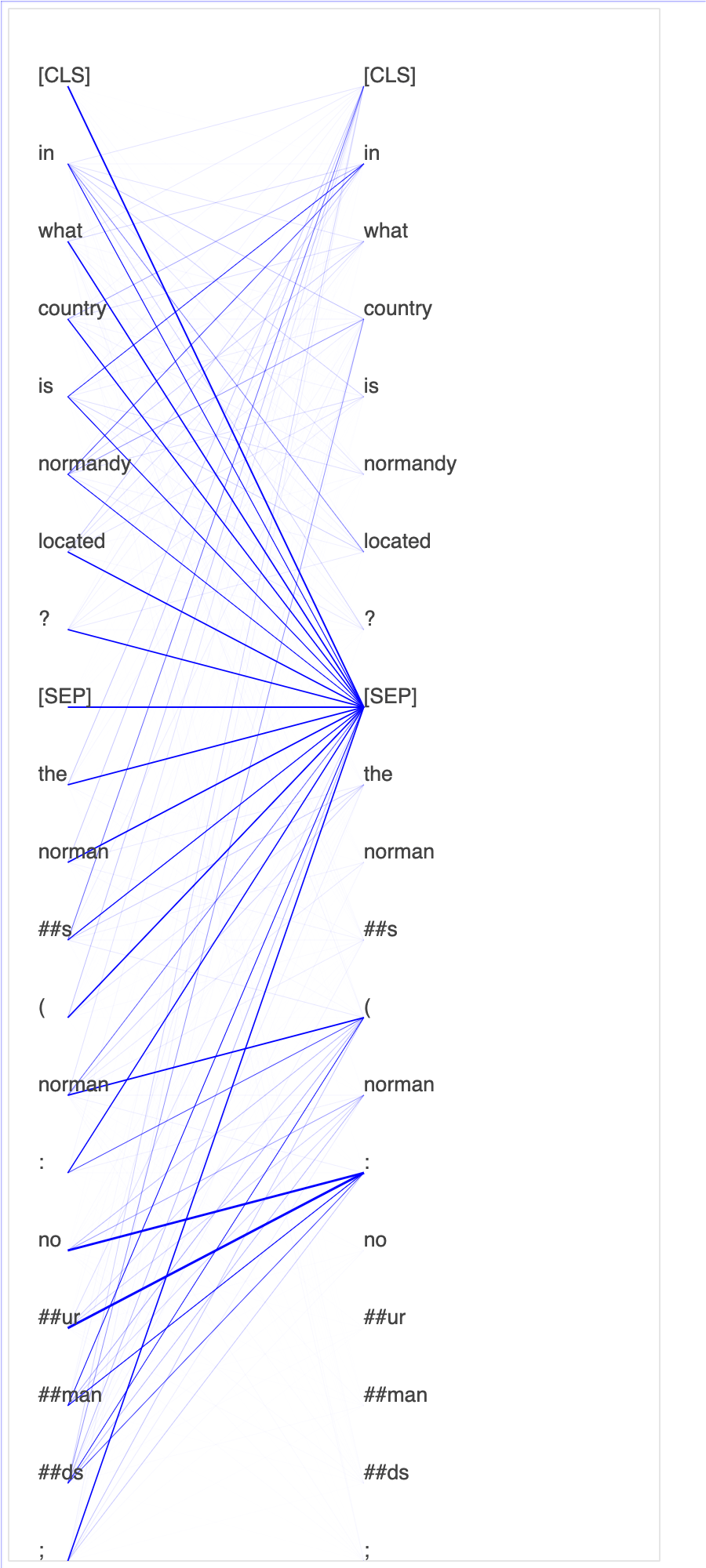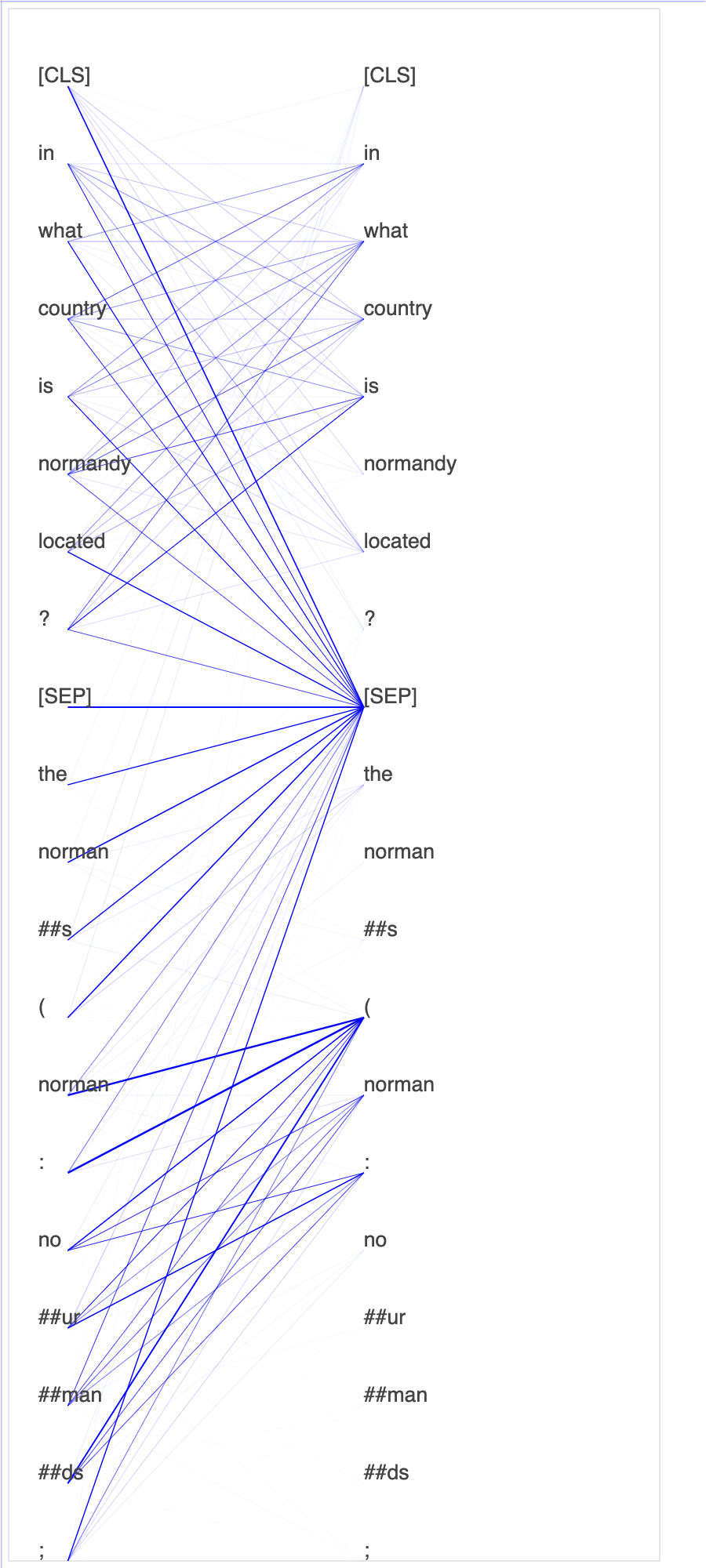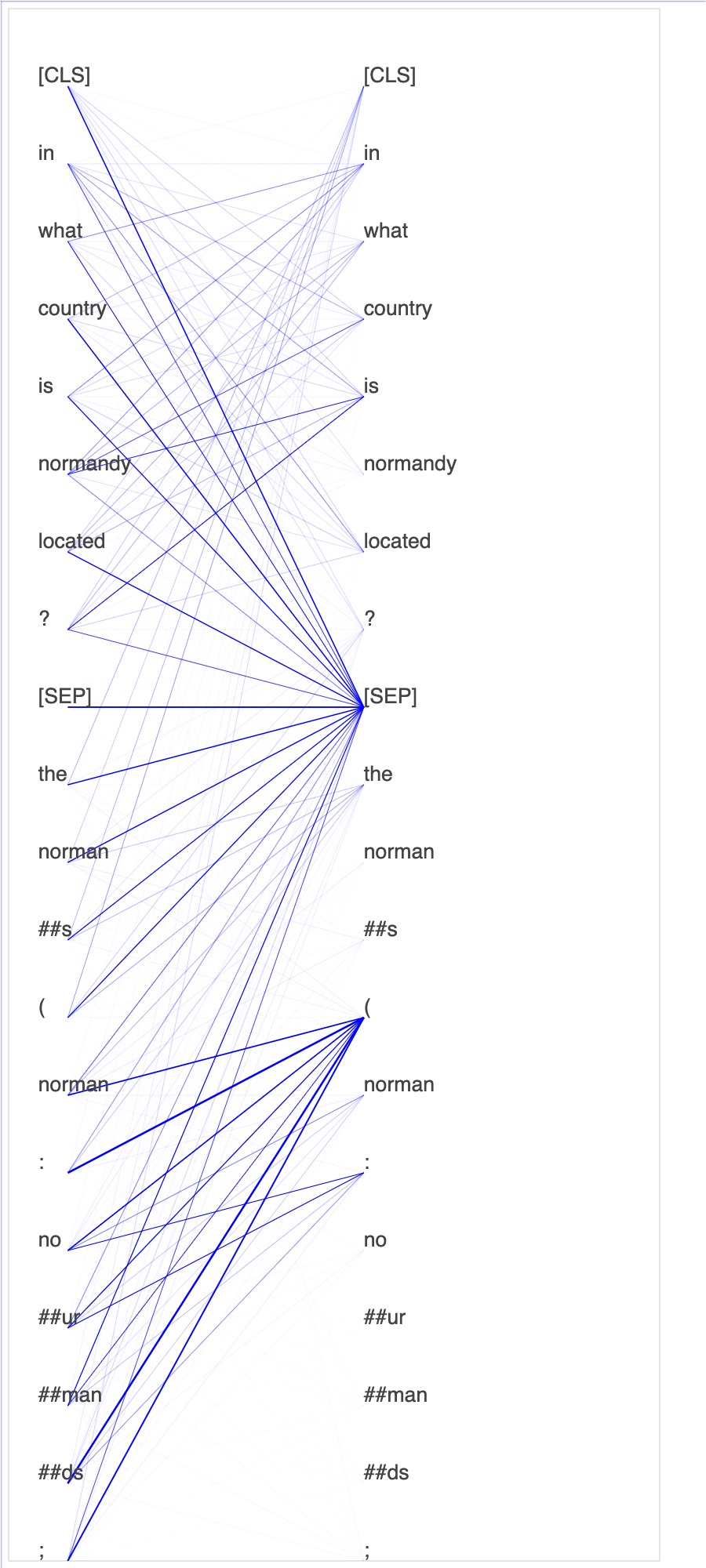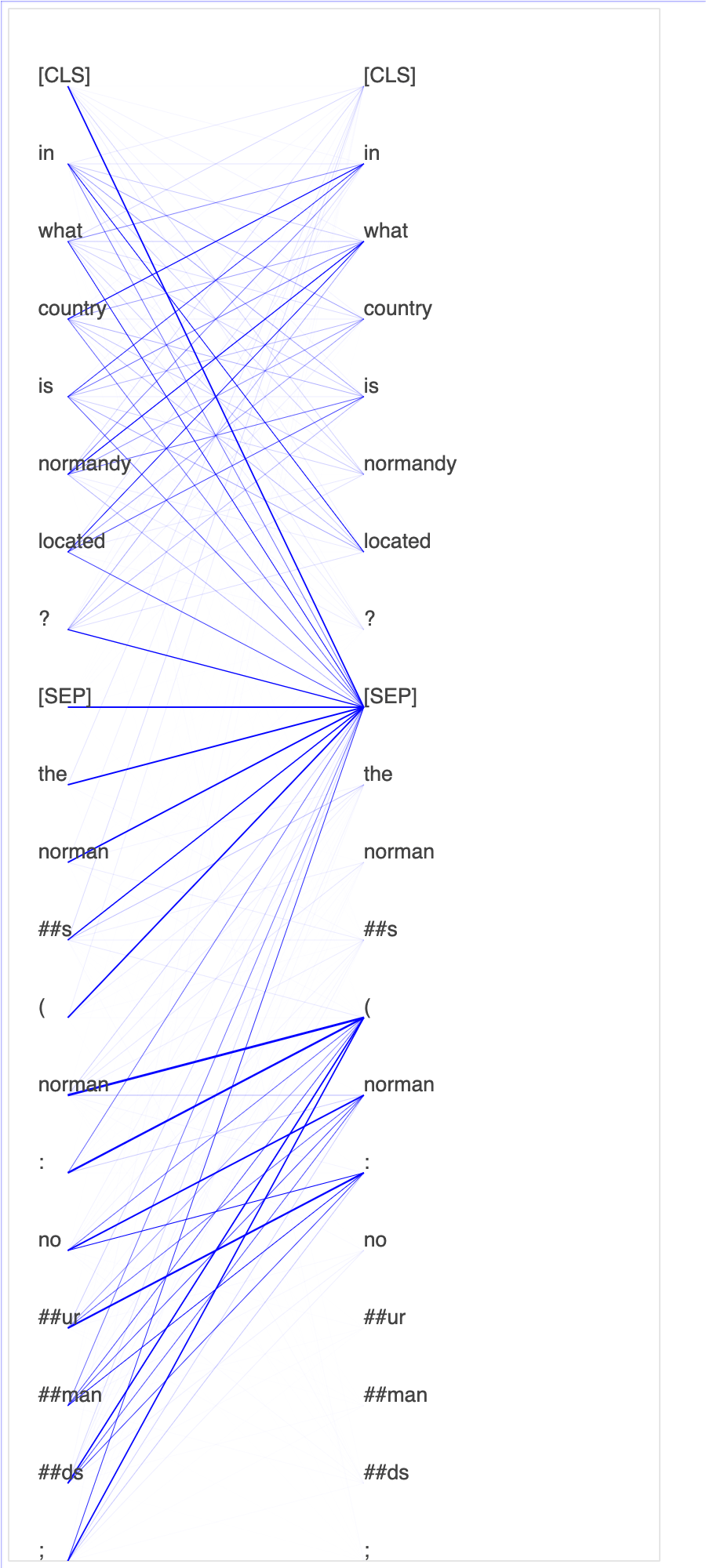
在查询和关键向量中绘制注意力分数和各个神经元有助于识别模型预测不正确的原因。借助 SageMaker AI Debugger,您可以检索张量,并在训练进行时实时绘制注意力头部视图,并了解模型正在学习什么。
下面的动画显示在笔记本示例中提供的训练作业中十次迭代的前 20 个输入标记的注意力分数。
使用 SageMaker 调试器可视化卷积神经网络 (CNN) 中的类激活图
本笔记本演示了如何使用 SageMaker Debugger 绘制用于卷积神经网络 (CNN) 中图像检测和分类的类激活地图。在深度学习中,卷积神经网络(CNN 或 ConvNet)是一类深度神经网络,最常用于分析视觉图像。采用类激活图的应用之一是自动驾驶汽车,此应用需要对图像进行即时检测和分类,如交通标志、道路和障碍物。
在本笔记本中, PyTorch ResNet 模型使用德国交通标志数据集进行训练,该数据集
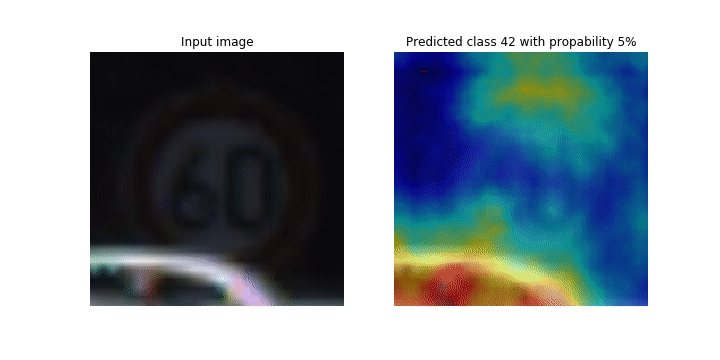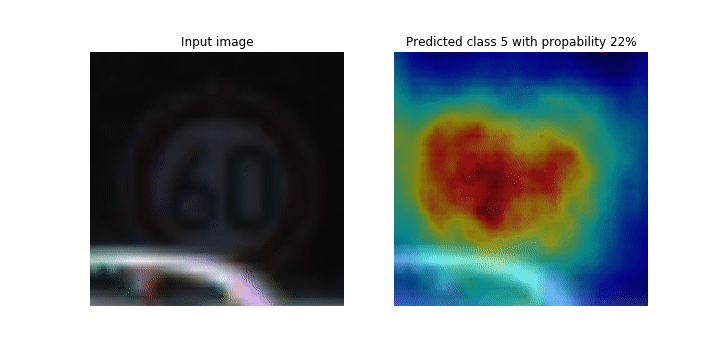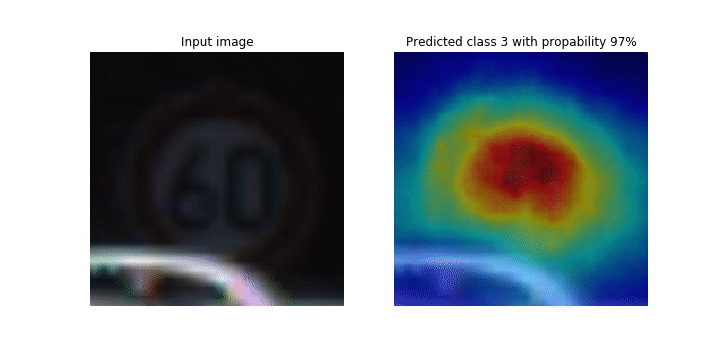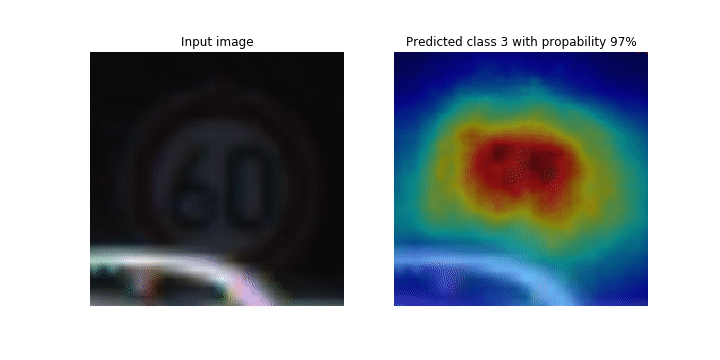
在训练过程中, SageMaker Debugger 会收集张量以实时绘制类激活地图。如动画图像所示,类激活图(也称为显著图)以红色突出显示具有高激活率的区域。
使用 Debugger 捕获的张量,您可以直观查看激活图在模型训练期间的演变。在训练作业开始时,模型首先检测左下角的边缘。随着训练的进行,焦点转移到中心并检测到限速标志,模型成功地将输入图像预测为3级,这是一类限速 60km/h 标志,置信度为97%。