本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
因子分解机的工作原理
因子分解机模型的预测任务是估算从特征集 xi 到目标域的函数 ŷ。该域对于回归是实际值,对于分类是二元值。因子分解机模型是有监督的,因此它具有可用的训练数据集 (xi,yj)。该模型呈现的优势是它使用因子分解的参数化方法来捕获两两特征交互。它可以用数学表示,如下所示:
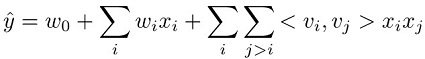
该等式中的三个项分别对应于模型的三个分量:
-
w0 项表示全局偏置。
-
wi 线性项对第 i 个变量的强度进行建模。
-
<vi,vj> 因子分解项对第 i 个和第 j 个变量之间的成对交互进行建模。
全局偏置项和线性项与线性模型中的相同。第三项将两两特征交互建模为每个特征所学习的相应因子的内积。所学因子也可视为每种特征的嵌入向量。例如,在分类任务中,如果一对特征往往更频繁地在积极标记样本中共同发生,则其因子的内积将较大。也就是说,其嵌入向量在余弦相似性方面彼此接近。有关因子分解机模型的更多信息,请参阅因子分解机
对于回归任务,通过尽可能减小模型预测 ŷn 与目标值 yn 之间的平方误差来训练模型。这称为平方损失:
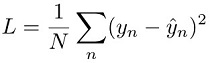
对于分类任务,通过尽可能减少交叉熵损失(也称作日志丢失)来训练模型:
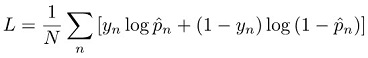
其中:
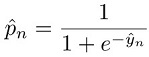
有关分类的损失函数的更多信息,请参阅分类的损失函数