本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
GitHub 存储库
要启动训练作业,您需要使用来自两个不同 GitHub存储库的文件:
这些存储库包含用于启动、管理和自定义大语言模型(LLM)训练过程的基本组件。您可以使用存储库中的脚本为 LLM 设置和运行训练作业。
HyperPod 食谱存储库
使用SageMaker HyperPod 食谱
-
main.py:此文件是启动向集群或训练作业提交训练作业的过程的主要入口点。 SageMaker -
launcher_scripts:此目录包含一组常用脚本,旨在简化各种大语言模型(LLM)的训练过程。 -
recipes_collection:此文件夹包含开发人员提供的一系列预定义的 LLM 配方。用户可以将这些配方与其自定义数据结合使用,训练根据其具体要求定制的 LLM 模型。
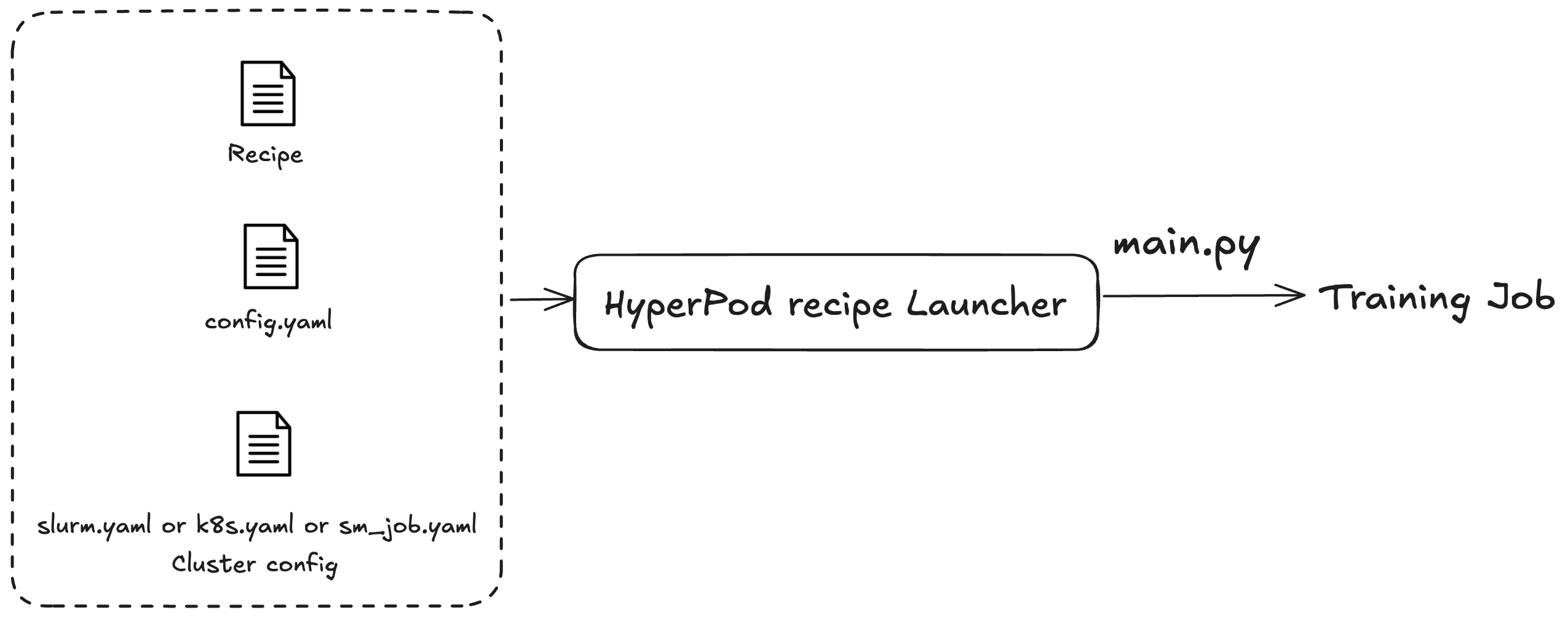
您可以使用 SageMaker HyperPod 配方来启动训练或微调作业。无论您使用哪个集群,作业提交过程都相同。例如,您可以使用同一脚本向 Slurm 或 Kubernetes 集群提交作业。启动程序会根据三个配置文件调度训练作业:
-
常规配置(
config.yaml):包括常用设置,例如训练作业中使用的默认参数或环境变量。 -
集群配置(集群):仅适用于使用集群的训练作业。如果您要向 Kubernetes 集群提交训练作业,则可能需要指定卷、标签或重启策略等信息。对于 Slurm 集群,您可能需要指定 Slurm 作业名称。所有参数都与您所使用的特定集群相关。
-
配方(配方):配方包含训练作业的设置,例如模型类型、分片度或数据集路径。例如,您可以指定 Llama 作为训练模型,并使用模型或数据并行技术 [例如,全分片分布式并行(FSDP)] 跨八台计算机对其进行训练。您还可以为训练作业指定其他检查点频率或路径。
指定配方后,您可以运行启动程序脚本,通过 main.py 入口点根据配置在集群上指定端到端训练作业。对于您使用的每个配方,launch_scripts 文件夹中都有随附的 Shell 脚本。这些示例将指导您提交和启动训练作业。下图说明了 SageMaker HyperPod 配方启动器如何根据上述内容向集群提交训练作业。目前, SageMaker HyperPod 配方启动器建立在 Nvidia Fr NeMo amework Launcher 之上。有关更多信息,请参阅《NeMo 启动器指南》
HyperPod 配方适配器存储库
SageMaker HyperPod 训练适配器是一个训练框架。可使用它管理训练作业的整个生命周期。可使用该适配器将模型的预训练或微调作业分发给多台计算机。该适配器使用不同的并行技术来分发训练作业。它还负责检查点保存功能的实现与管理。有关更多详细信息,请参阅高级设置。
使用SageMaker HyperPod 配方适配器存储库
-
src:此目录包含 Large-scale 语言模型 (LLM) 训练的实现,包括模型并行度、混合精度训练和检查点管理等各种功能。 -
examples:此文件夹提供了一组示例,这些示例演示了如何创建用于训练 LLM 模型的入口点,可用作用户实用指南。