本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
推荐结果
每个 Inference Recommender 作业结果均包括 InstanceType、InitialInstanceCount 和 EnvironmentParameters,它们是已针对您的容器调整的环境变量参数,以减少延迟并提高吞吐量。结果还包括性能和成本指标,例如 MaxInvocations、ModelLatency、CostPerHour、CostPerInference、CpuUtilization、和 MemoryUtilization。
在下表中,我们提供了对这些指标的描述。这些指标有助于您缩小搜索范围,以找到适合您的使用案例的最佳端点配置。例如,如果您的目标是整体性价比,并且重点放在吞吐量上,那么您应专注于 CostPerInference。
| 指标 | 说明 | 使用案例 |
|---|---|---|
|
|
从 SageMaker AI 上看,模型做出响应所花费的时间间隔。此时间间隔包括发送请求以及从模型容器提取响应的本地通信时间,以及在容器中完成推理所用的时间。 单位:毫秒 |
延迟敏感型工作负载,例如广告服务和医疗诊断 |
|
|
一分钟内发送到模型端点的 单位:无 |
Throughput-focused 视频处理或批量推理等工作负载 |
|
|
您的实时端点的每小时估计成本。 单位:美元 |
成本敏感型工作负载,无延迟截止日期 |
|
|
您的实时端点的每次推理估计成本。 单位:美元 |
最大限度地提高整体性价比,以吞吐量为重点 |
|
|
端点实例的每分钟最大调用次数时的预期 CPU 使用率。 单位:百分比 |
通过显示实例的核心 CPU 利用率,了解基准测试期间的实例运行状况 |
|
|
端点实例的每分钟最大调用次数时的预期内存使用率。 单位:百分比 |
通过显示实例的核心内存利用率,了解基准测试期间的实例运行状况 |
在某些情况下,您可能需要探索其他 SageMaker AI 端点调用指标,CPUUtilization例如。每个 Inference Recommender 作业结果均包含负载测试期间启动的端点的名称。即使这些终端节点已被删除,您也可以使用 CloudWatch 来查看这些端点的日志。
下图是您可以查看推荐结果中单个端点的 CloudWatch 指标和图表的示例。此推荐结果来自默认作业。解释推荐结果中的标量值的方法是,这些值基于调用图表第一次开始趋于平稳的时间点。例如,报告的 ModelLatency 值位于平稳期开始的 03:00:31 左右。
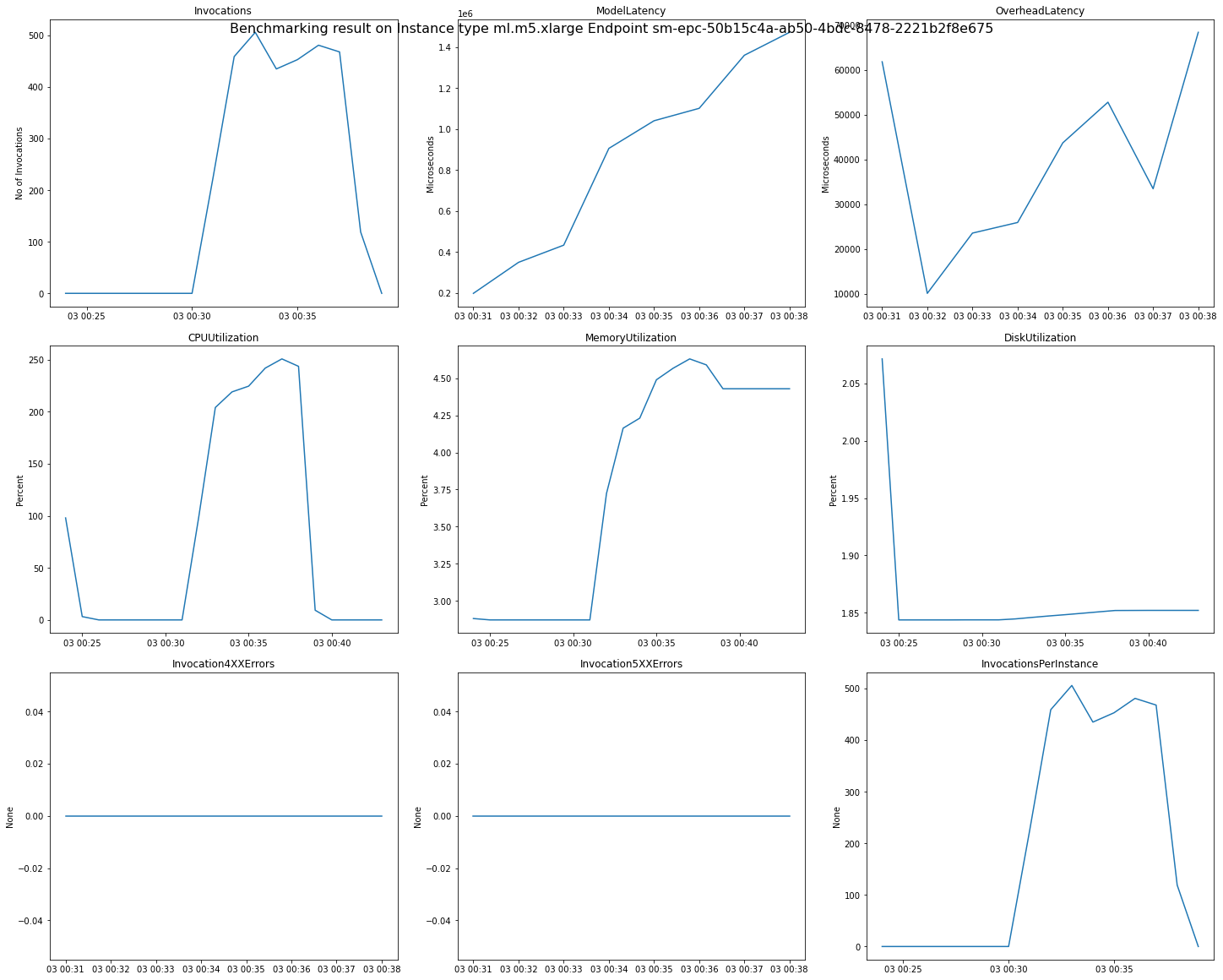
有关上述图表中使用的 CloudWatch 指标的完整描述,请参阅 SageMaker AI 端点调用指标。
您还可以在 /aws/sagemaker/InferenceRecommendationsJobs 命名空间中查看 Inference Recommender 发布的性能指标,如 ClientInvocations 和 NumberOfUsers。有关 Inference Recommender 发布的指标和描述的完整列表,请参阅 SageMaker 推理推荐人作业指标。
有关如何使用适用于 Pyth on 的 SDK ( Amazon Boto3) 浏览终端节点 CloudWatch 指标的示例,请参阅亚马逊 sagemaker-