本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
用生产变体测试模型
在生产 ML 工作流中,数据科学家和工程师经常尝试以各种方式提高性能,例如使用 SageMaker AI 自动调整模型、通过额外或较新的数据进行训练、改进功能选择、使用更新过的更好实例和提供容器。您可以使用生产变体来比较您的模型、实例和容器,并选择性能最佳的候选变体来响应推理请求。
借助 SageMaker AI 多变体终端节点,您可以通过为每个变体提供流量分配,将端点调用请求分发到多个生产变体,也可以直接为每个请求调用特定变体。在本主题中,我们介绍了两种测试 ML 模型的方法。
指定流量分配以测试模型
要在多个模型之间分配流量以测试这些模型,请在端点配置中为每个生产变体指定权重以指定路由到每个模型的流量百分比。有关信息,请参阅CreateEndpointConfig。下图更详细地说明了它的工作方式。
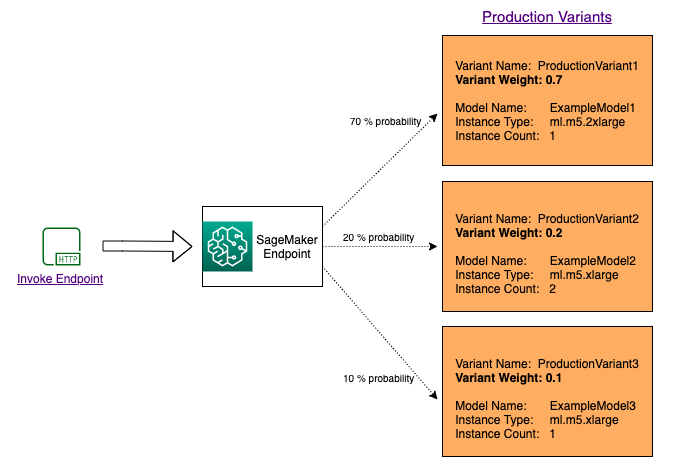
调用特定的变体以测试模型
要通过为每个请求调用特定模型来测试多个模型,请在调用时提供TargetVariant参数值来指定要调用的模型的特定版本。InvokeEndpoint SageMaker AI 确保请求由您指定的生产变体处理。如果您已提供流量分配并指定 TargetVariant 参数值,目标路由将覆盖随机流量分配。下图更详细地说明了它的工作方式。

模型 A/B 测试示例
在新模型和具有生产流量的新模型和旧模型之间进行 A/B 测试可能是新模型验证过程中的有效最后一步。在 A/B 测试中,您可以测试模型的不同变体,并比较每个变体的性能。如果模型的较新版本提供的性能优于以前存在的版本,请在生产中使用模型的新版本替换旧版本。
以下示例显示了如何执行 A/B 模型测试。有关实现此示例的示例笔记本,请参阅 “在生产环境中A/B 测试机器学习模型
步骤 1:创建并部署模型
首先,我们定义模型在 Amazon S3 中的位置。在后续步骤中部署模型时,将使用这些位置:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
接下来,我们使用图像和模型数据创建模型对象。这些模型对象用于在端点上部署生产变体。这些模型是通过不同数据集、不同算法或 ML 框架以及不同超参数训练 ML 模型而开发的:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
现在,我们创建两个生产变体,每个变体具有自己不同的模型和资源要求(实例类型和数量)。这样,您还可以在不同的实例类型上测试模型。
我们将两个变体的 initial_weight 设置为 1。这意味着,50% 的请求发送到 Variant1,其余 50% 的请求发送到 Variant2。两个变体的权重总和为 2,每个变体的权重分配为 1。这意味着每个变体接收 1/2的流量占总流量的50%。
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
最后,我们已经准备好在 SageMaker AI 端点上部署这些生产变体了。
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
步骤 2:调用部署的模型
现在,我们将请求发送到该端点以实时获得推理结果。我们同时使用流量分配和直接定位。
首先,我们使用在上一步中配置的流量分配。每个推理响应包含处理请求的生产变体的名称,因此,我们可以看到发送到两个生产变体的流量大致相等。
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker AI 会Invocations针对亚马逊 CloudWatch中的每个变体发布诸如Latency和之类的指标。有关 A SageMaker I 发出的指标的完整列表,请参阅亚马逊中的亚马逊 A SageMaker I 指标 CloudWatch。让我们查询 CloudWatch 以获取每个变体的调用次数,以显示默认情况下如何在变体之间分配调用:
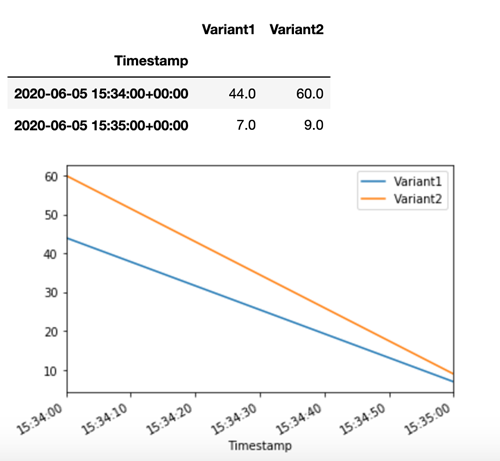
现在,让我们在 invoke_endpoint 调用中将 Variant1 指定为 TargetVariant 以调用特定模型版本。
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
为了确认所有新调用均由处理Variant1,我们可以查询 CloudWatch 以获取每个变体的调用次数。我们看到,对于最新的调用(最新的时间戳),Variant1 按我们指定的方式处理了所有请求。没有针对 Variant2 的调用。

步骤 3:评估模型性能
为了了解哪个模型版本的表现更好,让我们评估每个变体的准确性、精度、召回率、F1 分数和在曲线 charactersistic/Area 下运行的接收器。首先,让我们看一下 Variant1 的这些指标:
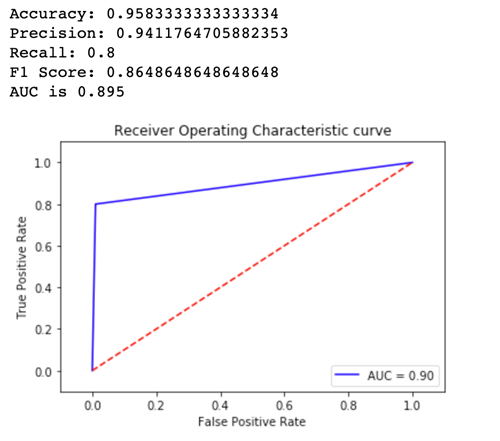
现在,让我们看一下 Variant2 的指标:
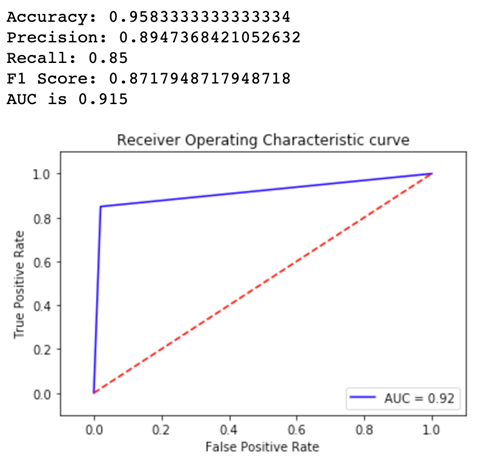
对于我们定义的大多数指标,Variant2 性能更好,因此,这是我们要在生产中使用的变体。
步骤 4:为最佳模型增加流量
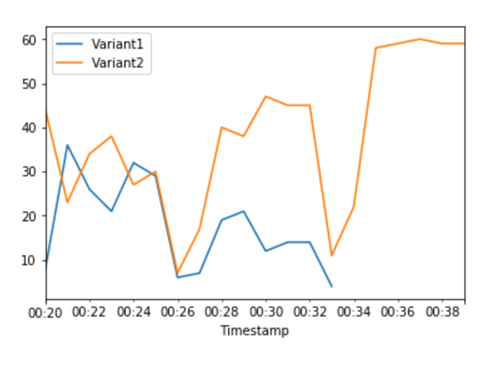
既然我们已确定 Variant2 性能比 Variant1 好,我们将更多流量转移到该变体。我们可以继续使用TargetVariant来调用特定的模型变体,但更简单的方法是通过调用来更新分配给每个变体的权重UpdateEndpointWeightsAndCapacities。这会更改生产变体的流量分配,而无需更新端点。回想一下设置部分,我们设置了变体权重来分割流量 50/50。以下每个变体的总调用次数 CloudWatch 指标向我们展示了每个变体的调用模式:

现在,我们使用为每个变体分配新的权重,将 Variant2 75% 的流量转移到UpdateEndpointWeightsAndCapacities。 SageMaker 现在,AI 向发送了 75% 的推理请求Variant2,其余 25% 的请求发送给。Variant1
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
每个变体的总调用次数 CloudWatch 指标向我们显示的调用次数高于以下变体的调用次数:Variant2Variant1

我们可以继续监控指标,在对某个变体的性能感到满意时,我们可以将 100% 的流量路由到该变体。我们使用 UpdateEndpointWeightsAndCapacities 更新变体的流量分配。的权重设置Variant1为 0,的权重设置Variant2为 1。 SageMaker 现在,AI 将所有推理请求的 100% 发送给。Variant2
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
每个变体的总调用次数 CloudWatch 指标显示,所有推理请求都由Variant2处理,没有推理请求由处理。Variant1
现在,您可以安全地更新端点,并将 Variant1 从端点中删除。您也可以在端点中添加新的变体,并执行步骤 2-4 以继续在生产中测试新模型。