本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
选择输入模式和存储单元
训练作业的最佳数据来源取决于工作负载特征,例如数据集的大小、文件格式、文件的平均大小、训练持续时间、顺序或随机数据加载器读取模式以及模型消耗训练数据的速度。以下最佳实践为您提供了开始使用最合适的输入模式和数据存储服务的指南。
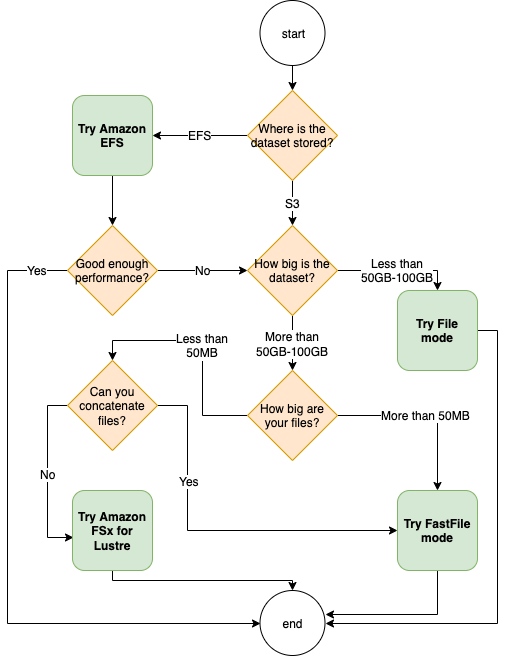
何时使用 Amazon EFS
如果您的数据集存储在 Amazon Elastic File System 中,您可能有使用 Amazon EFS 进行存储的预处理或注释应用程序。您可以运行已配置为数据通道指向 Amazon EFS 文件系统的训练作业。有关更多信息,请参阅使用适用于 Lustre 的 Amazon FSx 和 Amazon EFS 文件系统加快亚马逊 A SageMaker I 训练速度
为小型数据集使用文件模式
如果数据集存储在 Amazon Simple Storage Service 中,并且其总体容量相对较小(例如,小于 50-100 GB),请尝试使用文件模式。下载 50 GB 数据集的开销可能因文件总数而异。例如,如果将数据集分为 100 MB 的分片,则需要大约 5 分钟。该启动开销是否可以接受主要取决于训练作业的总体持续时间,因为更长的训练阶段意味着下载阶段相应地缩小。
对多个小文件进行序列化
如果您的数据集大小较小(小于 50-100 GB)、但由许多小文件组成(每个文件小于 50 MB),则文件模式下的下载开销会增加,因为每个文件都需要从 Amazon Simple Storage Service 单独下载到训练实例卷。为了总体上减少这种开销和数据遍历时间,可以考虑使用文件格式(例如 TFRecord for、for 和 R ecordio f
何时使用快速文件模式
对于文件较大(每个文件超过 50 MB)的较大数据集,第一种选择是尝试使用快速文件模式,该模式比适用于 Lustre 的 FSx 更为直接,因为它不需要创建文件系统或连接到 VPC。快速文件模式非常适合大型文件容器(超过 150 MB),可能还适用于大于 50 MB 的文件。由于快速文件模式提供 POSIX 界面,因此它支持随机读取(读取非顺序字节范围)。但这不是理想的使用案例,您的吞吐量可能会低于顺序读取的吞吐量。不过,如果您有一个相对较大的计算密集型机器学习模型,则快速文件模式可能仍然能够让训练管线的有效带宽达到饱和,而不会导致 IO 瓶颈。您需要进行试验以确定效果。要从文件模式切换到快速文件模式(然后切换回来),只需在使用 SageMaker Python SDK 定义输入通道时添加(或删除)input_mode='FastFile'参数即可:
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')
何时使用适用于 Lustre 的 Amazon FSx
如果您的数据集对于文件模式来说太大,有许多无法轻松序列化的小文件,或者您的数据集使用随机读取访问模式,那么适用于 Lustre 的 FSx 是一个不错的选择。它的文件系统可扩展到每秒数百 GB (GB/s) 的吞吐量和数百万个 IOPS,当你有许多小文件时,这是理想的选择。但请注意,由于延迟加载以及设置和初始化适用于 Lustre 的 FSx 文件系统的开销,可能会出现冷启动问题。
提示
要了解更多信息,请参阅为您的 Amazon SageMaker 训练作业选择最佳数据源