本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
设置访问数据集的训练作业
创建训练作业时,可指定训练数据集在所选数据存储中的位置以及作业的数据输入模式。亚马逊 SageMaker AI 支持亚马逊简单存储服务 (Amazon S3)、亚马逊弹性文件系统 (亚马逊 EFS) 和适用于 Lustre 的亚马逊 FSx。您可以选择其中一种输入模式来实时流式传输数据集,或者在训练作业开始时下载整个数据集。
注意
您的数据集必须与训练作业位于同一 Amazon Web Services 区域 位置。
SageMaker AI 输入模式和 Amazon 云存储选项
本节概述了存储在 Amazon EFS 和 Amazon FSx for Lustre 中的数据所 SageMaker 支持的文件输入模式。
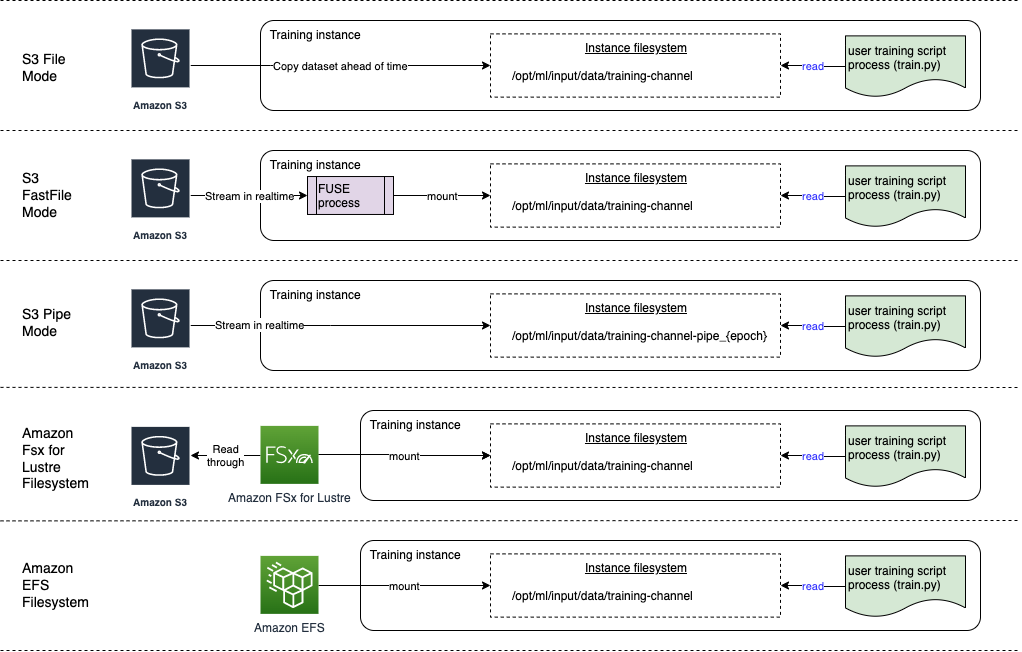
-
文件模式向训练容器显示数据集的文件系统视图。如果您没有明确指定其他两个选项之一,这就是默认输入模式。如果您使用文件模式, SageMaker AI 会将训练数据从存储位置下载到 Docker 容器中的本地目录。训练会在完整数据集下载完毕后开始。在文件模式下,训练实例必须有足够的存储空间来容纳整个数据集。文件模式的下载速度取决于数据集的大小、文件的平均大小和文件数量。您可以通过提供 Amazon S3 前缀、清单文件或增强清单文件来将数据集配置为文件模式。当所有数据集文件都使用通用 S3 前缀寻址时,应使用 S3 前缀。文件模式与 SageMaker AI 本地模式
兼容(在几秒钟内以交互方式启动 SageMaker 训练容器)。对于分布式训练,您可以使用 ShardedByS3Key选项将数据集分成多个实例。 -
快速文件模式允许文件系统访问 Amazon S3 数据来源,同时利用管道模式的性能优势。在训练开始时,快速文件模式标识数据文件但不下载它们。无需等待下载整个数据集即可开始训练。这意味着,在带有所提供的 Amazon S3 前缀的文件较少的情况下,启动训练所需的时间会缩短。
与管道模式相反,快速文件模式适用于随机访问数据。但在按顺序读取数据时,它的性能最好。快速文件模式不支持增强清单文件。
快速文件模式使用 POSIX-compliant 文件系统接口公开 S3 对象,就好像这些文件在训练实例的本地磁盘上可用一样。当您的训练脚本使用数据时,它会根据需要流式传输 S3 内容。这意味着您的数据集不再需要作为一个整体放入训练实例的存储空间,也无需等待数据集下载到训练实例后再开始训练。快速文件模式目前仅支持 S3 前缀(它不支持清单和增强清单)。快速文件模式与 SageMaker AI 本地模式兼容。
注意
使用 Fast File 模式可能会增加 CloudTrail 成本,因为需要额外记录以下内容:
-
Amazon S3 数据事件(如果在中启用 CloudTrail)。
-
Amazon KMS 访问使用密钥加密的 Amazon S3 对象时的解密事件。 Amazon KMS
-
与 Amazon KMS 运营相关的管理事件。
如果您为这些事件类型启用了 CloudTrail 日志记录,请查看您的 CloudTrail 配置和监控成本。
-
-
管道模式直接从 Amazon S3 数据来源流式传输数据。与文件模式相比,流式传输可以缩短启动时间并提高吞吐量。
直接流式传输数据时,您可以减小训练实例使用的 Amazon EBS 卷的大小。管道模式只需要足够的磁盘空间来存储最终模型构件。
这是另一种流式处理模式,在很大程度上已被更新、更易于使用的快速文件模式所取代。在管道模式下,以高并发性和吞吐量从 Amazon S3 预取数据,然后流式传输到命名管道中,该管道因其行为也被称为 First-In-First-Out (FIFO) 管道。每个管道只能由一个进程读取。一款特定于 SageMaker AI 的扩展, TensorFlow 可方便地将 Pipe 模式集成到用于流式传输文本、TFRecordio 或 Recordio 文件格式的本机 TensorFlow 数据加载器
中。管道模式还支持对数据进行托管分片和随机排序。 -
Amazon S3 Express On e Zone 是一种高性能的单一可用区存储类别,可以为包括模型训练在内的对延迟最敏感的应用程序提供一致的个位数毫秒数据访问。 SageMaker Amazon S3 Express One Zone 允许客户将其对象存储和计算资源配置在单个 Amazon 可用区中,从而通过提高数据处理速度来优化计算性能和成本。为了进一步提高访问速度并支持每秒数十万个请求,数据存储在新的存储桶类型(Amazon S3 目录存储桶)中。
SageMaker AI 模型训练支持高性能 Amazon S3 Express One Zone 目录存储桶作为文件模式、快速文件模式和管道模式的数据输入位置。要使用 Amazon S3 Express One Zone 存储类,请输入 Amazon S3 Express One Zone 存储类存储桶的位置,而不是 Amazon S3 存储桶的位置。为具有所需访问控制和权限策略的 IAM 角色提供 ARN。有关详细信息,请参阅AmazonSageMakerFullAccesspolicy。您只能使用 Amazon S3 托管密钥 () SSE-S3 通过服务器端加密对目录存储桶中的 A SageMaker I 输出数据进行加密。 Server-side 目前不支持使用 Amazon KMS 密钥加密 (SSE-KMS),以便将 SageMaker AI 输出数据存储在目录存储桶中。有关更多信息,请参阅 Amazon S3 Express One Zone 存储类。
-
适用于 Lustre 的 Amazon FSx – 适用于 Lustre 的 FSx 可以扩展到数百 GB 的吞吐量和数百万 IOPS,所以检索文件时的延迟较低。启动训练作业时, SageMaker AI 将 FSx for Lustre 文件系统挂载到训练实例文件系统,然后启动您的训练脚本。挂载本身是一个相对较快的操作,它不依赖于适用于 Lustre 的 FSx 中存储的数据集的大小。
要访问 FSx for Lustre,您的训练作业必须连接到亚马逊虚拟私有云 (VPC),这需要设置和参与。 DevOps 为避免发生数据传输成本,文件系统使用单个可用区,您需要在运行训练作业时指定一个映射到此可用区 ID 的 VPC 子网。
-
Amazon EFS — 要使用 Amazon EFS 作为数据源,数据在训练之前必须已经存在于 Amazon EFS 中。 SageMaker AI 将指定的 Amazon EFS 文件系统挂载到训练实例,然后启动您的训练脚本。您的训练作业必须连接到 VPC 才能访问 Amazon EFS。
提示
要详细了解如何向 SageMaker AI 估算器指定 VPC 配置,请参阅 AI P SageMaker ython SDK 文档中的使用文件系统作为训练输入
。