本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
集群修复 GPU 错误
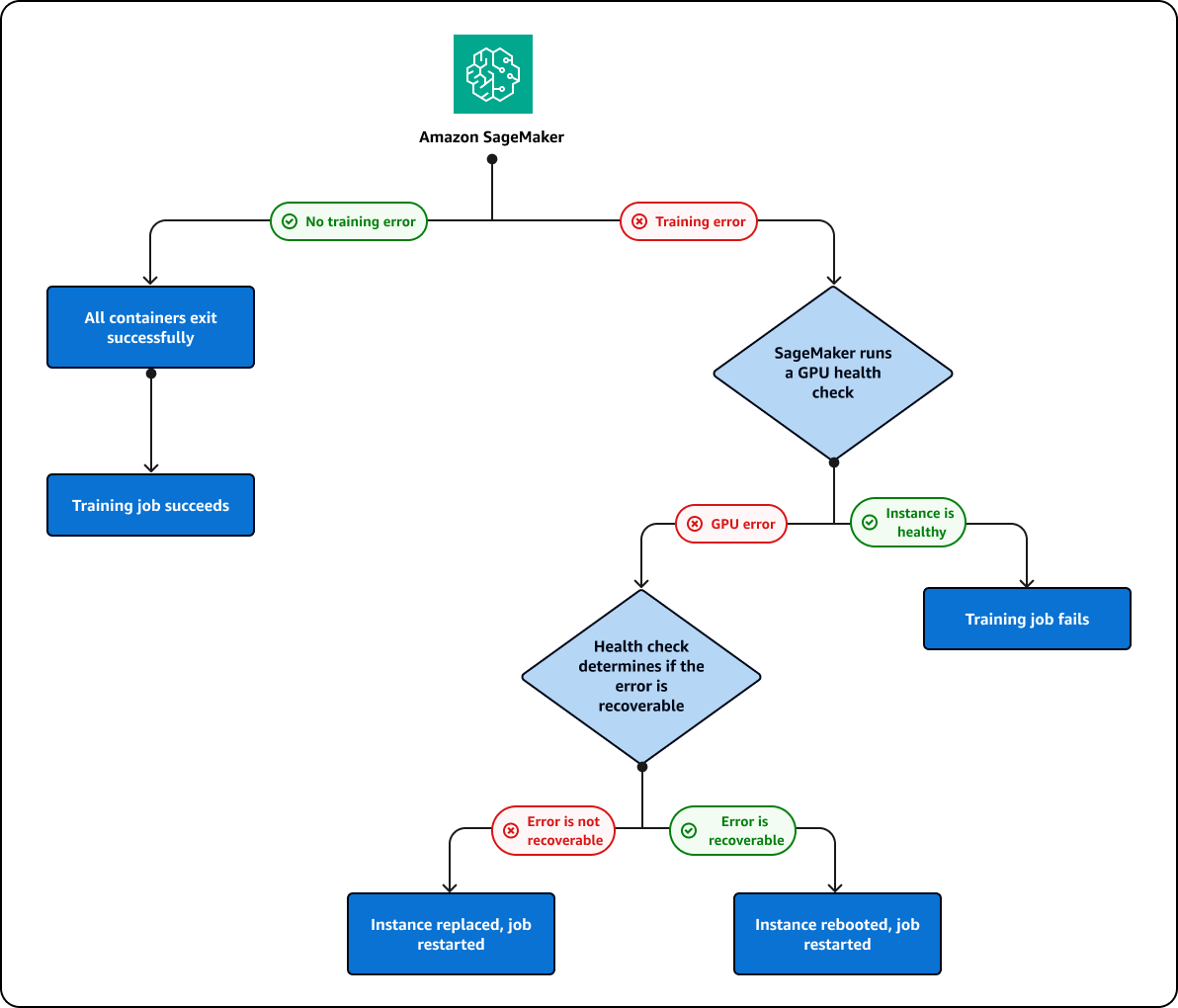
如果您在 GPU 上运行的训练作业失败, SageMaker AI 将运行 GPU 运行状况检查,以查看故障是否与 GPU 问题有关。 SageMaker AI 会根据运行状况检查结果采取以下操作:
如果错误可以恢复,并且可以通过重启实例或重置 GPU 来修复,则 SageMaker AI 将重启该实例。
如果错误无法恢复,并且是由需要更换的 GPU 引起的, SageMaker AI 将替换该实例。
作为 SageMaker AI 集群修复过程的一部分,实例要么被替换,要么重新启动。在此过程中,您将在训练作业状态中看到以下信息:
Repairing training cluster due to hardware failure
SageMaker AI 最多会尝试修复集10群。如果集群修复成功, SageMaker AI 将自动从上一个检查点重新启动训练作业。如果集群修复失败,训练作业也将失败。集群修复过程不收取费用。除非训练作业失败,否则不会启动集群修复。如果检测到暖池集群的 GPU 出现问题,集群将进入修复模式,重启或更换故障实例。修复后,集群仍可用作暖池集群。
下图描述了之前描述的集群和实例修复过程: