本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将管道并行性与张量并行性结合使用时的秩评定机制
此部分解释了模型并行性的秩评定机制如何与张量并行性结合使用。这是从 SageMaker 模型并行度库的核心功能 的秩评定基础知识smp.tp_rank() 用于张量并行秩、smp.pp_rank() 用于管道并行秩,以及 smp.rdp_rank() 用于缩减数据并行秩。对应的通信进程组是张量并行组 (TP_GROUP)、管道并行组 (PP_GROUP) 和缩减数据并行组 (RDP_GROUP)。这些组的定义如下:
-
张量并行组 (
TP_GROUP) 是数据并行组中一个可均匀分割的子集,在其中完成模块的张量并行分布。当管道并行度为 1 时,TP_GROUP与模型并行组 (MP_GROUP) 相同。 -
管道并行组 (
PP_GROUP) 是完成管道并行性的进程组。当张量并行度为 1 时,PP_GROUP与MP_GROUP相同。 -
缩减数据并行组 (
RDP_GROUP) 是一组进程,同时容纳相同的管道并行性分区和相同的张量并行分区,并在它们自身中执行数据并行性。之所以将其称为缩减数据并行组,是因为它是整个数据并行性组DP_GROUP的子集。对于分布在TP_GROUP中的模型参数,梯度allreduce运算仅对缩减数据并行组执行,而对于未分布的参数,梯度allreduce在整个DP_GROUP上进行。 -
模型并行组 (
MP_GROUP) 是指一组共同存储整个模型的进程。它由当前进程的TP_GROUP中,所有秩的PP_GROUP并集组成。当张量并行度为 1 时,MP_GROUP等于PP_GROUP。它也与先前smdistributed版本中的MP_GROUP现有定义一致。请注意,当前TP_GROUP是当前DP_GROUP和当前MP_GROUP的子集。
要详细了解 SageMaker 模型并行度库中的通信流程 API,请参阅 Pyth SageMaker on SDK 文档中的通
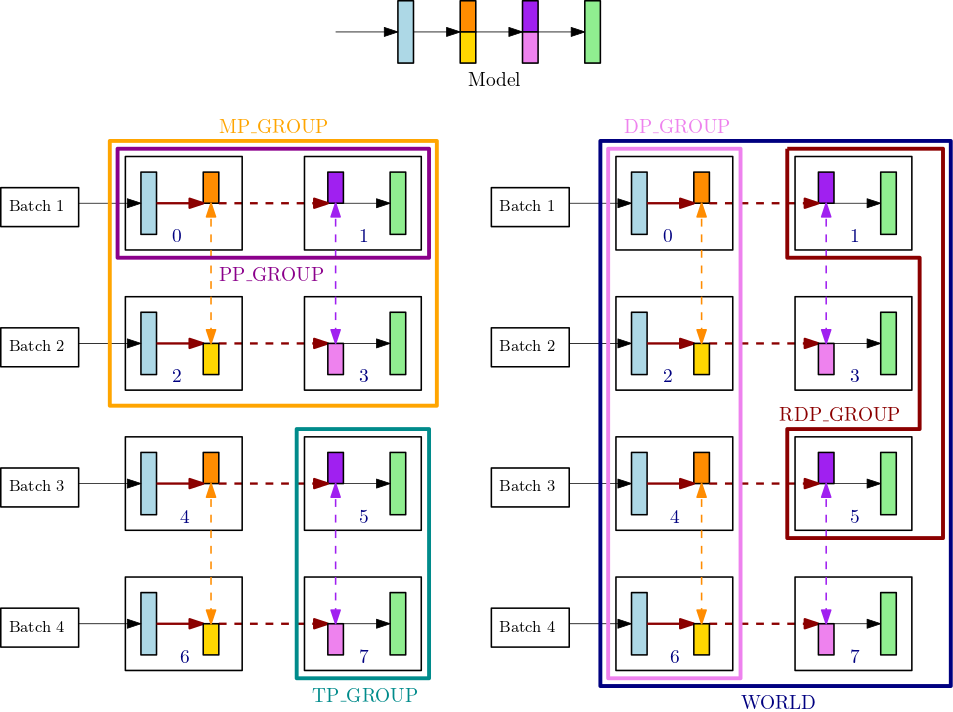
例如,考虑具有 8 个 GPU 的单个节点的进程组,其中张量并行度为 2,管道并行度为 2,数据并行度为 4。上图的顶部居中部分显示了一个包含 4 层的模型的示例。图的左下和右下部分说明了同时使用管道并行性和张量并行性时,分布在 4 个 GPU 上的 4 层模型,其中间两层使用张量并行性。下方的两个图是简单的副本,用于说明不同的组边界线。分区的模型在 GPU 0-3 和 4-7 之间复制以实现数据并行性。左下图显示了MP_GROUP、PP_GROUP 和 TP_GROUP 的定义。右下图显示了在一组相同 GPU 上的 RDP_GROUP、DP_GROUP 和 WORLD。为了实现数据并行性,具有相同颜色的层和层切片的梯度通过 allreduce 分在一起。例如,第一层(浅蓝色)获取 DP_GROUP 上的 allreduce 运算,而第二层中的深橙色切片只能获取其进程的 RDP_GROUP 中的 allreduce 运算。加粗深红色箭头表示张量及其完整 TP_GROUP 的批次。
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
在此示例中,管道并行性跨 GPU 对 (0,1)、(2,3)、(4,5) 和 (6,7) 进行。此外,数据并行性 (allreduce) 跨 GPU 0、2、4、6 进行,并在 GPU 1、3、5、7 上独立进行。张量并行性发生在 DP_GROUP 的子集上,跨 GPU 对 (0,2)、(1,3)、(4,6) 和 (5,7)。