本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
模型并行性概念
模型并行性是一种分布式训练方法,在这种方法中,深度学习 (DL) 模型被分割到多个 GPU 和实例中。 SageMaker 模型并行库 v2 (SMP v2) 与原生 PyTorch API 和功能兼容。这使您可以方便地调整 PyTorch 完全分片数据并行 (FSDP) 训练脚本以适应 SageMaker训练平台,并利用 SMP v2 提供的性能改进。本介绍页面提供了有关模型并行性的整体概述,并介绍了模型并行性如何帮助解决在训练通常非常大的深度学习 (DL) 模型时出现的问题。它还提供了 SageMaker模型并行库为帮助管理模型并行策略和内存消耗而提供的示例。
什么是模型并行性?
对于计算机视觉和自然语言处理等复杂的任务,增加深度学习模型(层和参数)的大小可以提高准确性。但是,在单个 GPU 的内存中所能容纳的最大模型大小有限制。在训练 DL 模型时,GPU 内存限制可能会在以下方面成为瓶颈:
-
它们限制了您可以训练的模型的大小,因为模型的内存占用量与参数数量成比例扩展。
-
它们限制训练期间的每个 GPU 的批次大小,从而降低了 GPU 利用率和训练效率。
为了克服与在单个 GPU 上训练模型相关的限制, SageMaker AI 提供了模型并行库,以帮助在多个计算节点上高效地分发和训练 DL 模型。此外,借助该库,您可以使用设备实现优化的分布式训练,这些 EFA-supported 设备通过低延迟、高吞吐量和操作系统旁路来增强节点间通信的性能。
在使用模型并行性之前估算内存需求
在使用 SageMaker 模型并行库之前,请考虑以下内容,以了解训练大型 DL 模型的内存需求。
对于使用 float16 (FP16) 或 bfloat16 (BF16) 等自动混合精度和 Adam 优化器的训练作业,每个参数所需的 GPU 内存约为 20 字节,我们可以将其细分如下:
-
一个 FP16 或 BF16 参数约需要 2 个字节
-
一个 FP16 或 BF16 渐变约需要 2 个字节
-
基于 Adam 优化器的 FP32 优化器状态约需要 8 个字节
-
参数的一个 FP32 副本约需要 4 个字节(
optimizer apply(OA) 操作需要) -
梯度的一个 FP32 副本约需要 4 个字节(OA 操作需要)
即使对于具有100亿个参数的相对较小的DL型号,它也可能至少需要200GB的内存,这比单个GPU上可用的典型GPU内存(例如带 40GB/80GB 内存的NVIDIA A100)大得多。除了模型和优化器状态的内存要求外,还有其他因素也会占用内存,例如在向前传递中生成的激活。所需的内存可能远远超过 200 GB。
对于分布式训练,我们建议您使用 Amazon EC2 P4 和 P5 实例,它们分别配备了 NVIDIA A100 和 H100 Tensor Core GPU。有关 CPU 核心、RAM、附属存储卷和网络带宽等规格的详细信息,请参阅 Amazon EC2 实例类型
即使使用加速计算实例,具有大约 100 亿个参数(例如 Megatron-LM 和 T5)的模型,以及具有数千亿个参数(例如)的大型模型 GPT-3,也无法在每个 GPU 设备中拟合模型副本。
库如何使用模型并行性和内存节省技术
库中包含各种类型的模型并行功能和节省内存的功能,例如优化器状态分片、激活检查点和激活分载。所有这些技术可以结合使用,从而高效地训练由数千亿个参数组成的大型模型。
分片数据并行性
分片数据并行性是一种节省内存的分布式训练技术,它在数据并行组中的各个 GPU 之间拆分模型的状态(模型参数、梯度和优化器状态)。
SMP v2 通过 FSDP 实现了分片数据并行性,并对其进行了扩展,以实现博客文章中讨论的规模感知型混合分片策略。Near-linear Amazon
您可以将分片数据并行性作为独立策略应用到模型。此外,如果您使用的是配备NVIDIA A100 Tensor Core GPU的最高性能的GPU实例ml.p4de.24xlarge,ml.p4d.24xlarge并且可以利用SageMaker 数据并行度 (SMDDP) 库提供的AllGather操作提高的训练速度。
要深入研究分片数据并行性并学习如何对其进行设置,或者将分片数据并行性与其他技术(例如张量并行和混合精度训练)结合使用,请参阅 混合分片数据并行性。
专家并行性
SMP v2 与 NVIDIA 威震天
MoE 模型是一种转换器模型,由多个专家组成,每个专家都由一个神经网络组成,通常是一个前馈网络 (FFN)。一个称为路由器的网关网络决定将哪些令牌发送给哪些专家。这些专家专门处理输入数据的特定方面,使模型的训练速度更快,计算成本更低,同时达到与其对应的密集模型相同的性能质量。专家并行性是一种并行性技术,用于在 GPU 设备上处理 MoE 模型的专家拆分。
要了解如何使用 SMP v2 训练 MoE 模型,请参阅 专家并行性。
张量并行性
张量并行可跨设备拆分各个层(即 nn.Modules),以并行运行。下图显示了一个最简单的示例,演示 SMP 库如何拆分具有四个层的模型,以实现两路张量并行 ("tensor_parallel_degree": 2)。在下图中,模型并行组、张量并行组和数据并行组的符号分别为 MP_GROUP、TP_GROUP 和 DP_GROUP。每个模型副本的层一分为二,分布到两个 GPU 中。库管理张量分布式模型副本之间的通信。
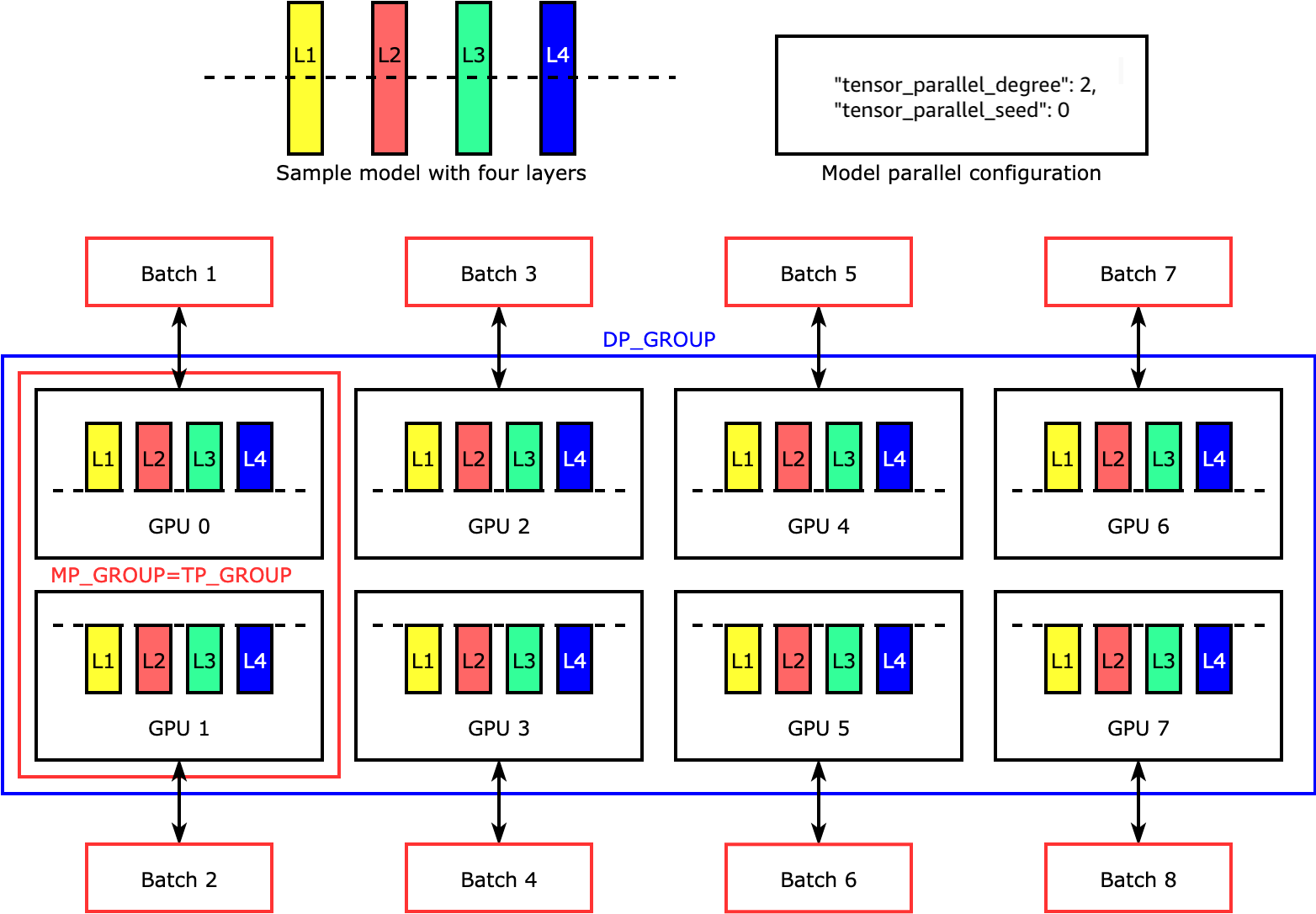
要深入了解张量并行性和其他节省内存的功能 PyTorch,以及如何设置核心功能的组合,请参阅。张量并行性
激活检查点并卸载
为了节省 GPU 内存,库支持激活检查点,以避免在向前传递期间,将用户指定模块的内部激活存储在 GPU 内存中。库会在向后传递期间重新计算这些激活。此外,通过激活卸载,它还能将存储的激活卸载到 CPU 内存中,并在后向传递时将其取回 GPU,从而进一步减少激活内存占用。有关如何使用这些功能的更多信息,请参阅 激活检查点 和 激活分载。
为模型选择合适的技术
有关选择合适技术和配置的更多信息,请参阅 SageMaker 分布式模型并行性最佳实践。