本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
模型并行性简介
模型并行性是一种分布式训练方法,在这种方法中,深度学习模型在单个实例或多个实例中的设备之间分区。本简介页面提供了有关模型并行性的高级概述,描述了它如何帮助克服在训练通常非常大的深度学习模型时出现的问题,并举例说明了模型 SageMaker 并行库为帮助管理模型并行策略和内存消耗而提供的内容。
什么是模型并行性?
对于计算机视觉和自然语言处理等复杂的任务,增加深度学习模型(层和参数)的大小可以提高准确性。但是,在单个 GPU 的内存中所能容纳的最大模型大小有限制。在训练 DL 模型时,GPU 内存限制可能会在以下方面成为瓶颈:
-
它们限制了您可以训练的模型的大小,因为模型的内存占用量与参数数量成比例扩展。
-
它们限制训练期间的每个 GPU 的批次大小,从而降低了 GPU 利用率和训练效率。
为了克服与在单个 GPU 上训练模型相关的限制, SageMaker 提供了模型并行库,以帮助在多个计算节点上高效地分发和训练 DL 模型。此外,借助该库,您可以使用设备实现最优化的分布式训练,这些 EFA-supported 设备通过低延迟、高吞吐量和操作系统旁路来增强节点间通信的性能。
在使用模型并行性之前估算内存需求
在使用 SageMaker 模型并行库之前,请考虑以下内容,以了解训练大型 DL 模型的内存需求。
对于使用 AMP (FP16) 和 Adam 优化器的训练作业,每个参数需要的 GPU 内存约为 20 字节,可以将其分解如下:
-
一个 FP16 参数约需要 2 个字节
-
一个 FP16 渐变约需要 2 个字节
-
基于 Adam 优化器的 FP32 优化器状态约需要 8 个字节
-
参数的一个 FP32 副本约需要 4 个字节(
optimizer apply(OA) 操作需要) -
梯度的一个 FP32 副本约需要 4 个字节(OA 操作需要)
即使对于具有100亿个参数的相对较小的DL型号,它也可能需要至少200GB的内存,这比单个GPU上可用的典型GPU内存(例如,带有 40GB/80GB 内存的NVIDIA A100和带 16/32 GB的V100)大得多。请注意,除了模型和优化器状态的内存要求外,还有其他因素也会占用内存,例如在向前传递中生成的激活。所需的内存可能远远超过 200 GB。
对于分布式训练,我们建议您使用 Amazon EC2 P3 和 P4 实例,它们分别配备了 NVIDIA V100 和 A100 Tensor Core GPU。有关 CPU 核心、RAM、附属存储卷和网络带宽等规格的详细信息,请参阅 Amazon EC2 实例类型
即使使用加速计算实例,很明显,具有大约 100 亿个参数(例如 Megatron-LM 和 T5)的模型以及具有数千亿个参数(例如)的更大模型也 GPT-3 无法在每个 GPU 设备中拟合模型副本。
库如何使用模型并行性和内存节省技术
库中包含各种类型的模型并行功能和节省内存的功能,例如优化器状态分片、激活检查点和激活分载。所有这些技术可以结合使用,从而高效地训练由数千亿个参数组成的大型模型。
主题
分片数据并行度(可用于) PyTorch
分片数据并行性是一种节省内存的分布式训练技术,它在数据并行组中的各个 GPU 之间拆分模型的状态(模型参数、梯度和优化器状态)。
SageMaker AI 通过实现 M I C 来实现分片数据并行性,MIC 是一个将 c 通信规模化为模型的库,并在博客文章中讨论了巨型模型训练的缩放。Near-linear Amazon
您可以将分片数据并行性作为独立策略应用到模型。此外,如果您使用配备 NVIDIA A100 Tensor Core GPU的最高性能的 GPU 实例 ml.p4d.24xlarge,则可以利用 SMDDP 集合体提供的 AllGather 操作提高训练速度。
要深入研究分片数据并行性并学习如何对其进行设置,或者将分片数据并行性与其他技术(例如张量并行性和 FP16 训练)结合使用,请参阅分片数据并行性。
管道并行度(适用于 PyTorch 和) TensorFlow
管道并行性将一组层或操作在到一组设备之间分区,保留每个操作保持不变。当您为模型分区数 (pipeline_parallel_degree) 指定值时,GPU 的总数 (processes_per_host) 必须可以被模型分区数量整除。要正确设置此项,您必须为 pipeline_parallel_degree 和 processes_per_host 参数指定正确的值。简单的数学运算如下:
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
根据您提供的两个输入参数,库负责计算模型副本(也称为data_parallel_degree)的数量。
例如,如果您设置 "pipeline_parallel_degree": 2 和 "processes_per_host": 8 以使用具有八个 GPU 工作线程的 ML 实例(例如 ml.p3.16xlarge),则该库会自动跨 GPU 上设置分布式模型和四路数据并行性。下图说明了模型如何分布在八个 GPU 上,实现四路数据并行性和两路管道并行性。每个模型副本(我们将其定义为管道并行组并标注为 PP_GROUP)都在两个 GPU 上分区。模型的每个分区都分配给四个 GPU,其中有四个分区副本位于一个数据并行组中并标注为 DP_GROUP。如果没有张量并行性,管道并行组本质上就是模型并行组。
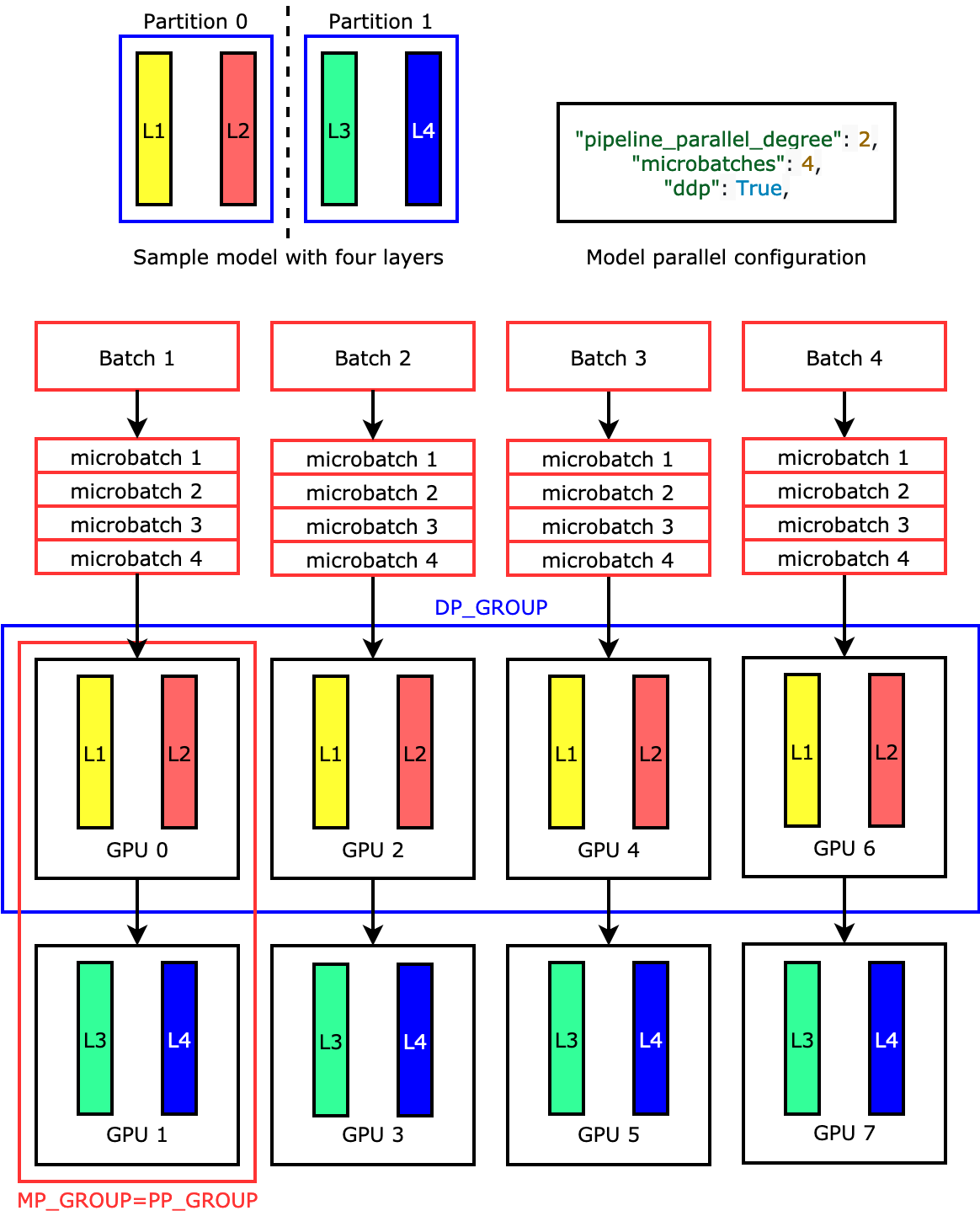
要深入了解管道并行性,请参阅 SageMaker 模型并行度库的核心功能。
要开始使用管道并行度运行模型,请参见使用模型并行库运行 SageMaker 分布式训练 Job。 SageMaker
张量并行度(可用于) PyTorch
张量并行性可跨设备拆分各个层(即 nn.Modules),以并行运行。下图显示了一个最简单的示例,演示库如何拆分具有四个层的模型,以实现两路张量并行性 ("tensor_parallel_degree": 2)。每个模型副本的层一分为二,分布到两个 GPU 中。在此示例中,模型并行配置还包括"pipeline_parallel_degree": 1和"ddp": True(在后台使用 PyTorch DistributedDataParallel 包),因此数据并行度变为八。库管理张量分布式模型副本之间的通信。
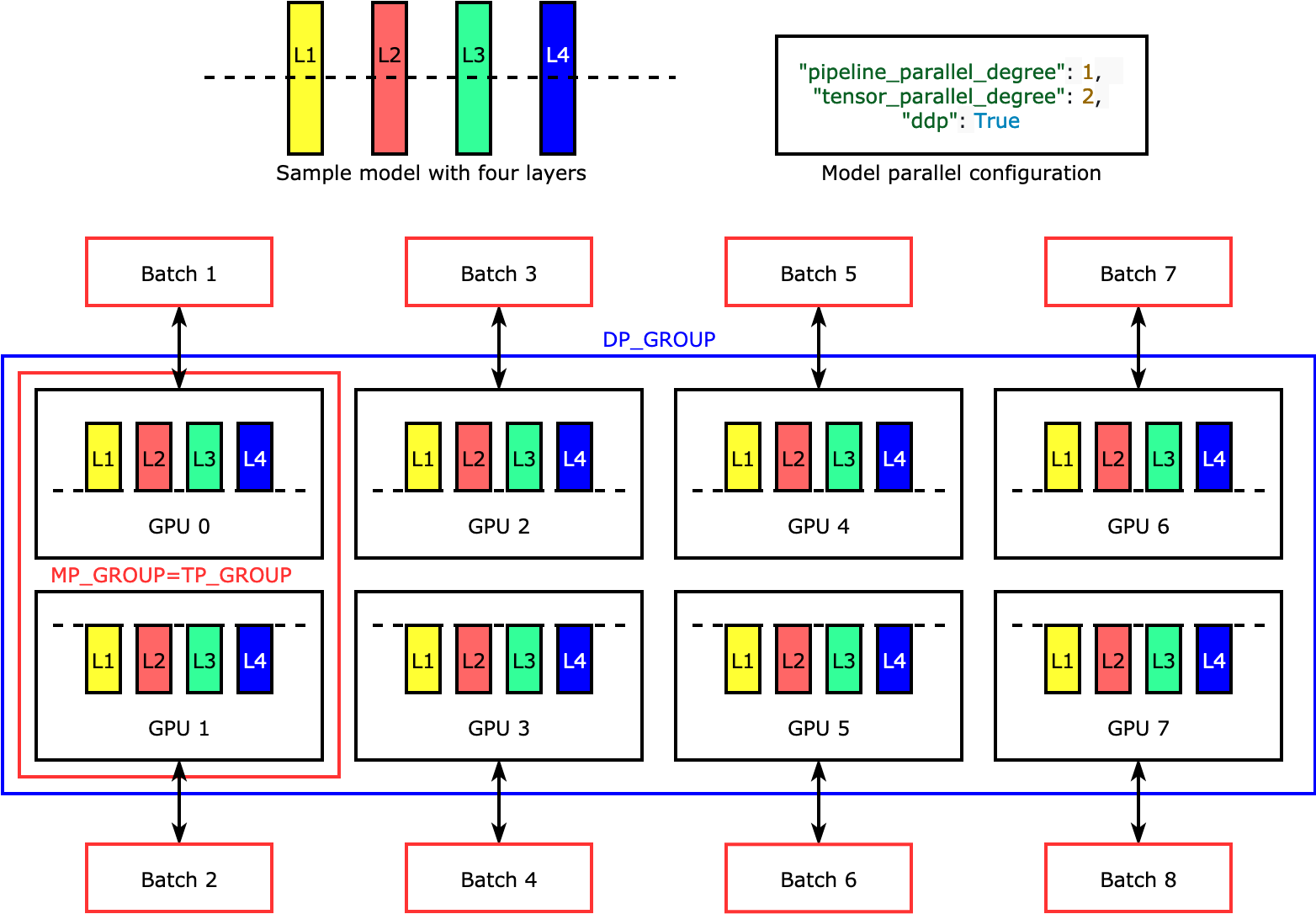
此功能的用处在于,您可以选择特定的层或层的子集来应用张量并行性。要深入了解张量并行性和其他节省内存的功能 PyTorch,以及如何设置流水线和张量并行度的组合,请参阅。张量并行性
优化器状态分片(可用于) PyTorch
要了解库如何执行优化器状态分片,可以考虑包含四个层的简单示例模型。优化状态分片的关键概念是,您无需在所有 GPU 中复制优化器状态。而是跨数据并行秩对优化器状态的单个副本进行分片,不存在跨设备的冗余。例如,GPU 0 存有第一层的优化器状态,下一个 GPU 1 存有 L2 的优化器状态,依此类推。以下动图显示了使用优化器状态分片技术的向后传播。在向后传播结束时,optimizer apply (OA) 操作会占用计算和网络时间来更新优化器状态,all-gather (AG) 操作会占用计算和网络时间来更新模型参数用于下一次迭代。最重要的是,reduce 操作可能与 GPU 0 上的计算重叠,从而带来更高的内存效率和更快的向后传播。在当前实施中,AG 和 OA 操作不与 compute 重叠。在 AG 操作期间,它可能会导致计算延长,因此可能需要权衡取舍。
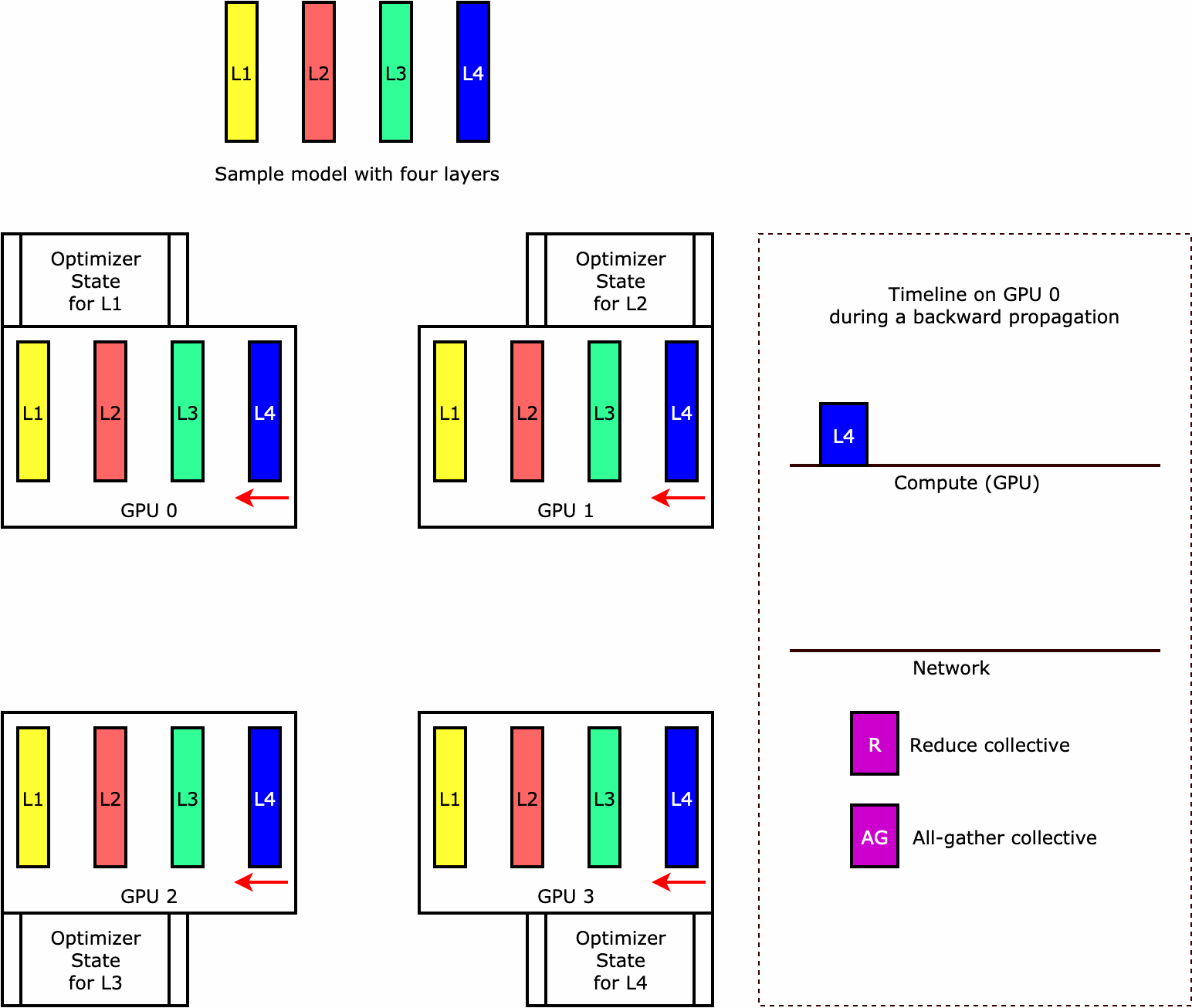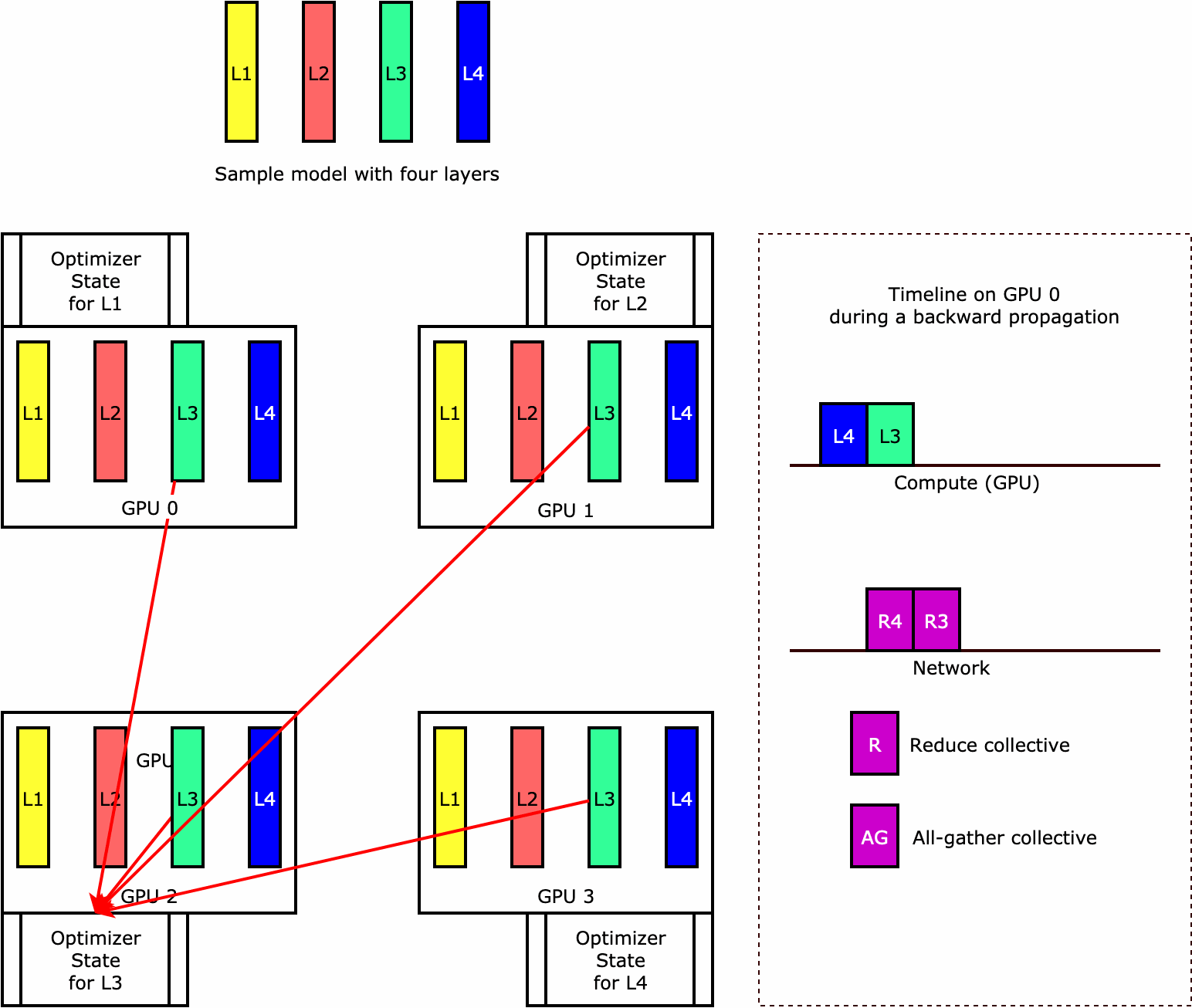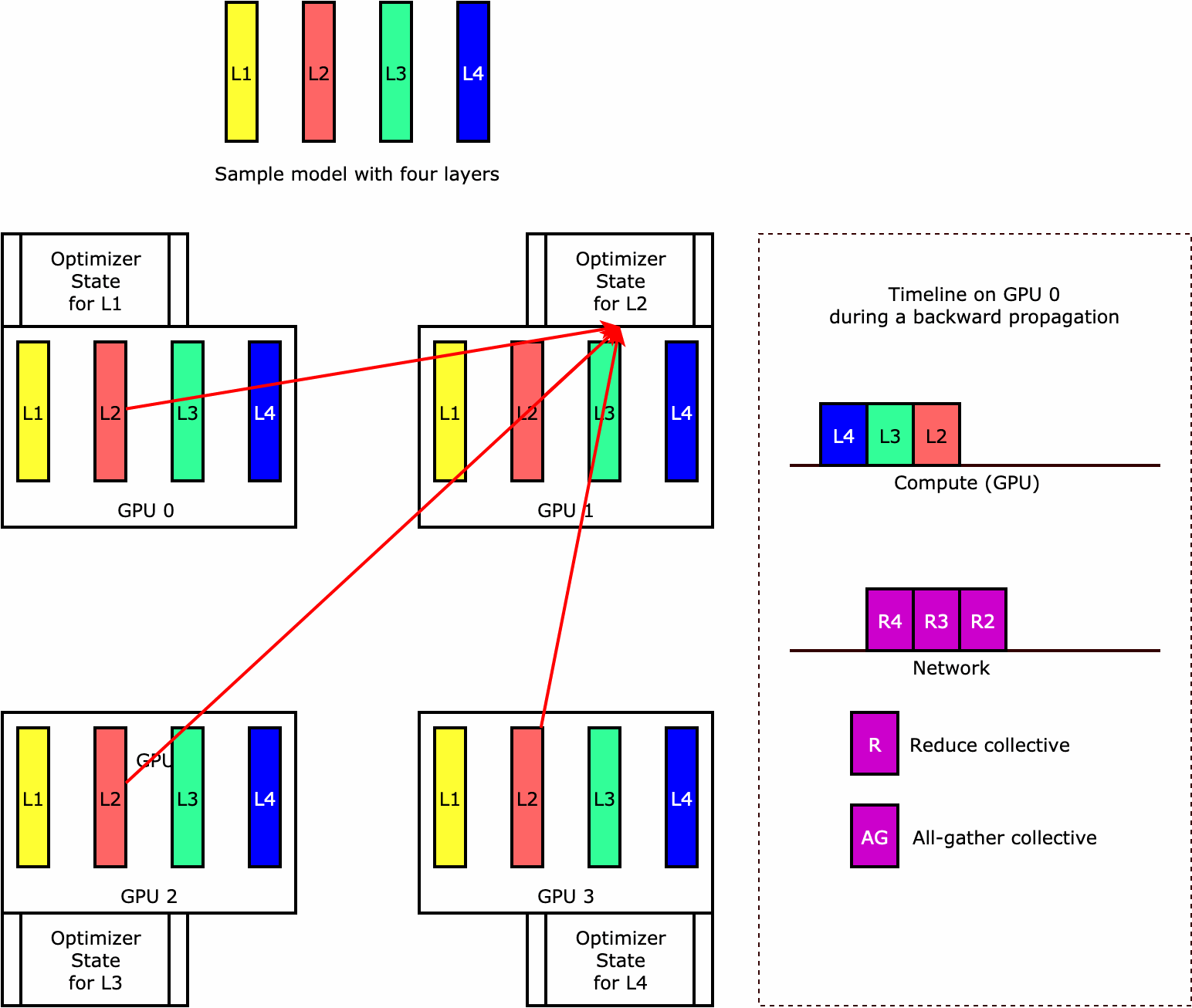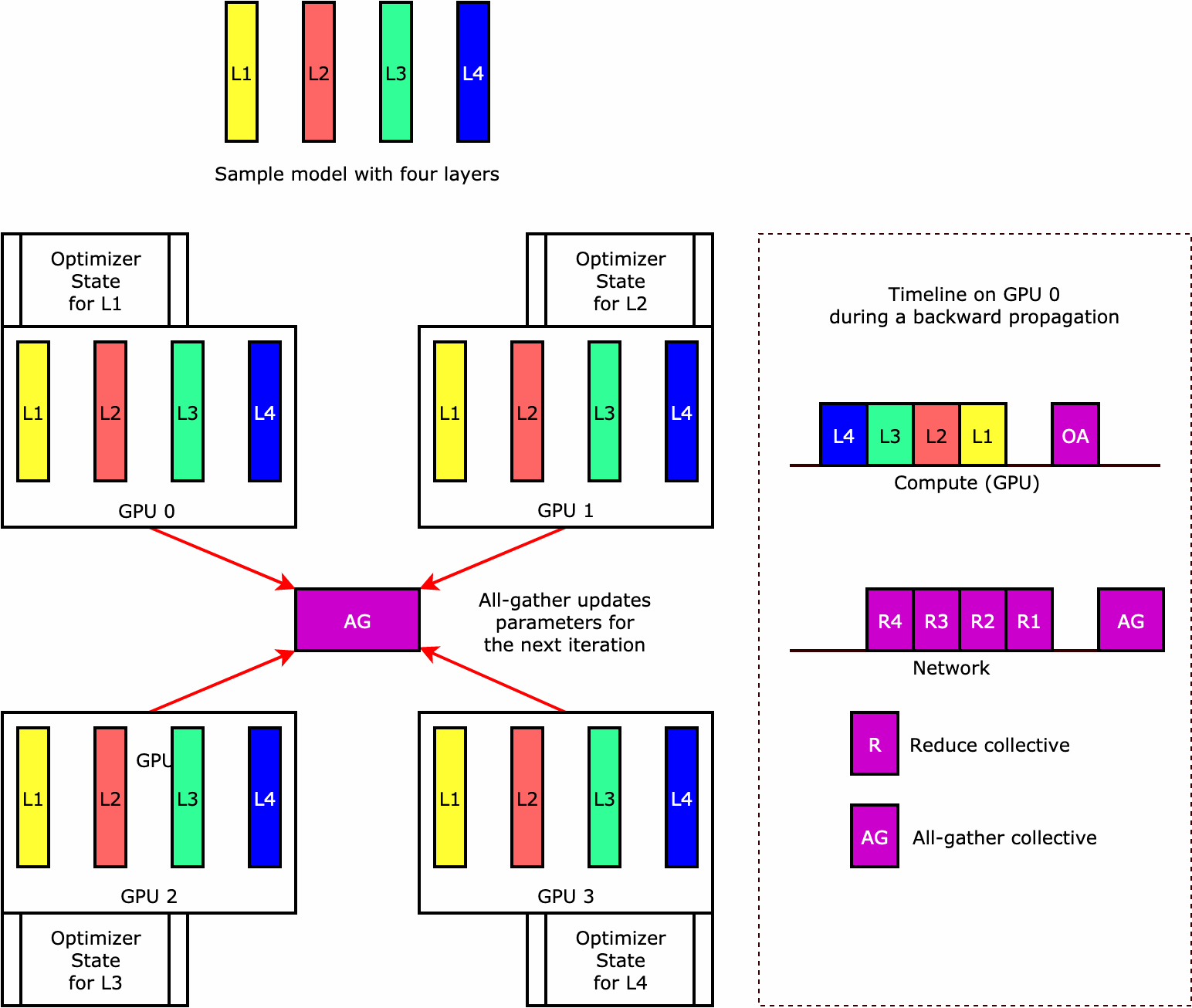
有关如何使用此功能的更多信息,请参阅优化器状态分片。
激活卸载和检查点操作(可用于) PyTorch
为了节省 GPU 内存,库支持激活检查点,以避免在向前传递期间,将用户指定模块的内部激活存储在 GPU 内存中。库会在向后传递期间重新计算这些激活。此外,激活分载功能将存储的激活分载到 CPU 内存,并在向后传递期间提取回 GPU,以进一步减少激活内存占用。有关如何使用这些功能的更多信息,请参阅激活检查点和激活分载。
为模型选择合适的技术
有关选择正确技术和配置的更多信息,请参阅SageMaker 分布式模型并行最佳实践和配置提示和陷阱。