本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
编译模型(亚马逊 A SageMaker I 控制台)
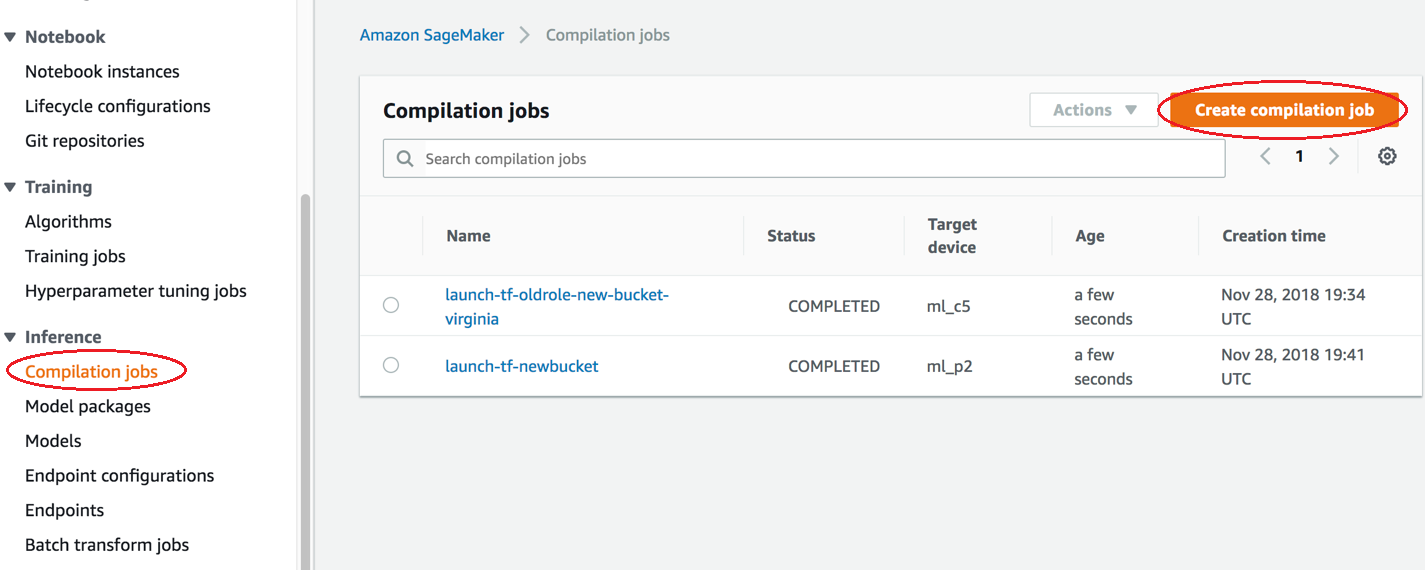
你可以在亚马逊 A SageMaker I 控制台中创建 Amazon SageMaker Neo 编译任务。
在 Amazon SageMaker AI 控制台中,选择编译任务,然后选择创建编译任务。
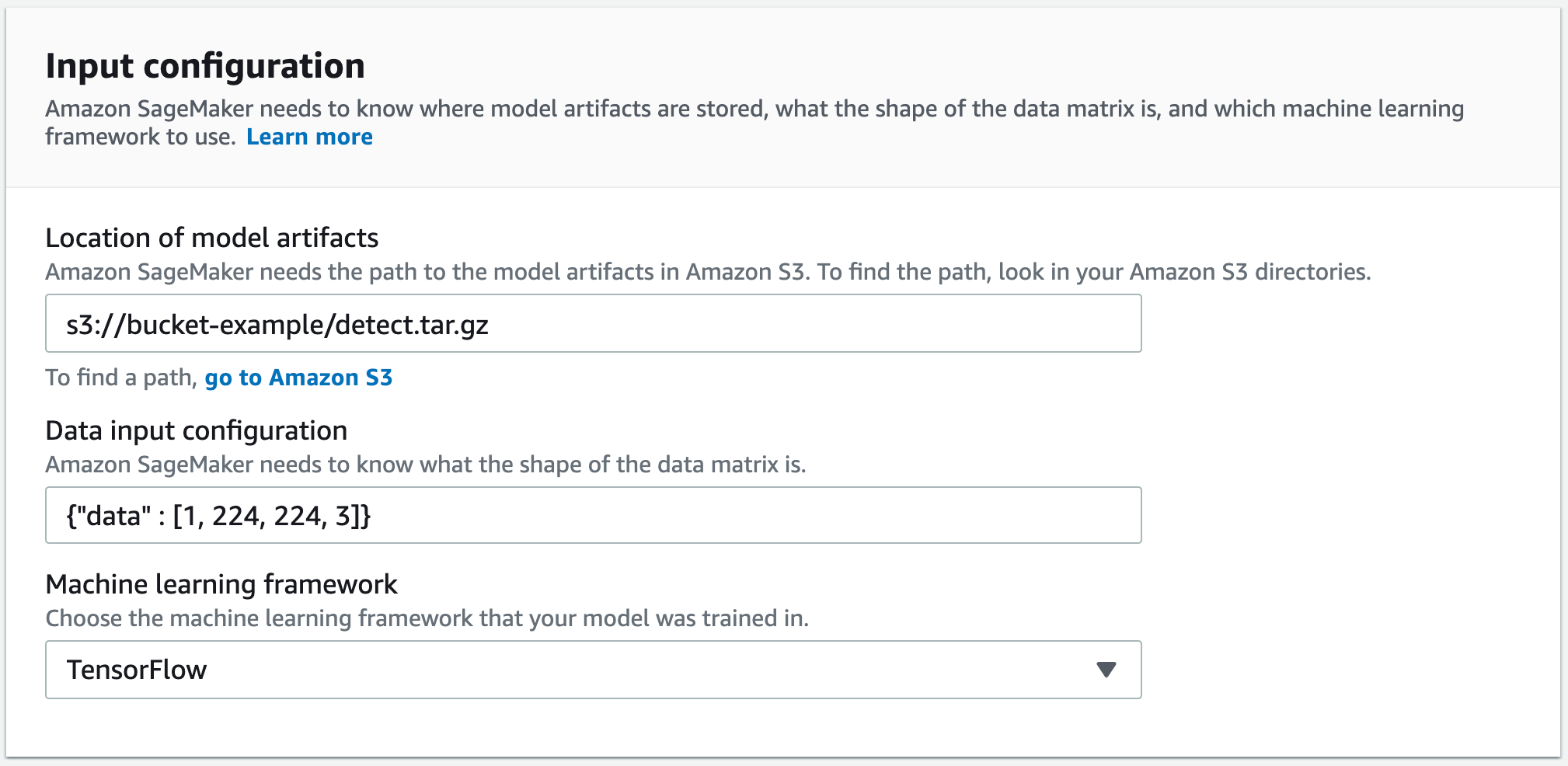
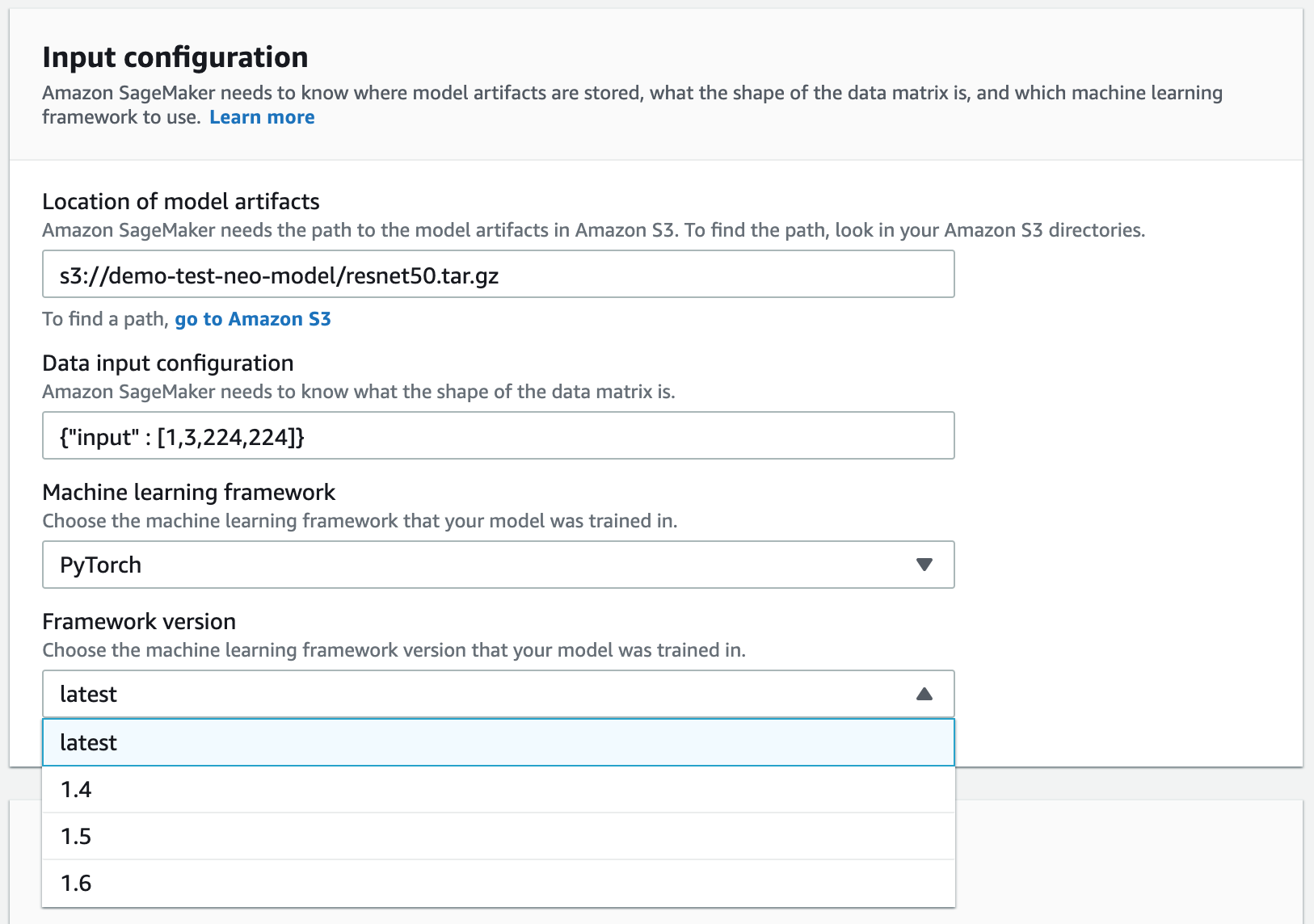
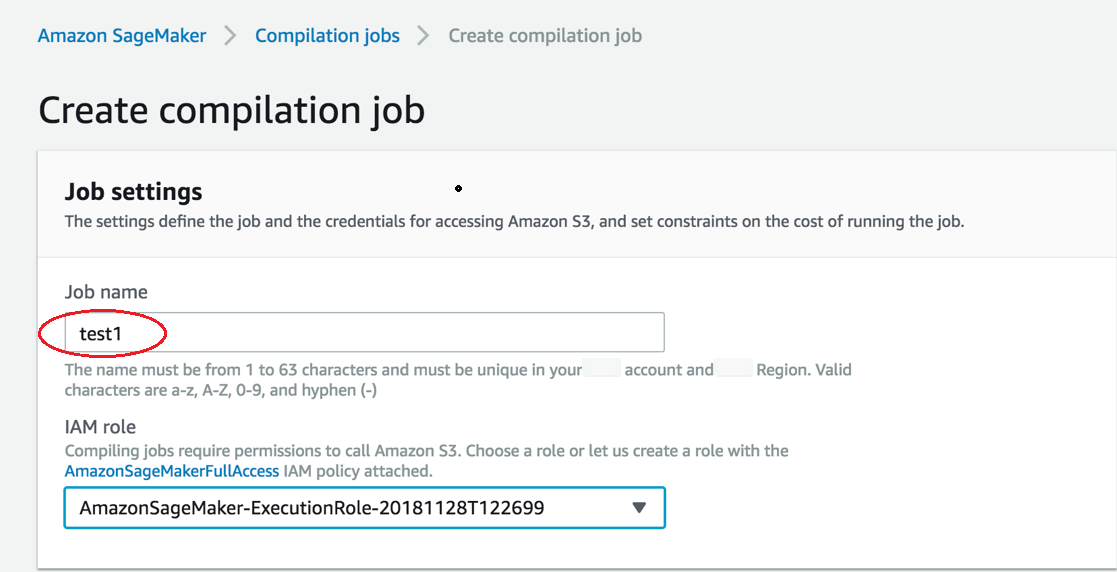
在创建编译作业页面的作业名称中,输入名称。然后选择 IAM 角色。
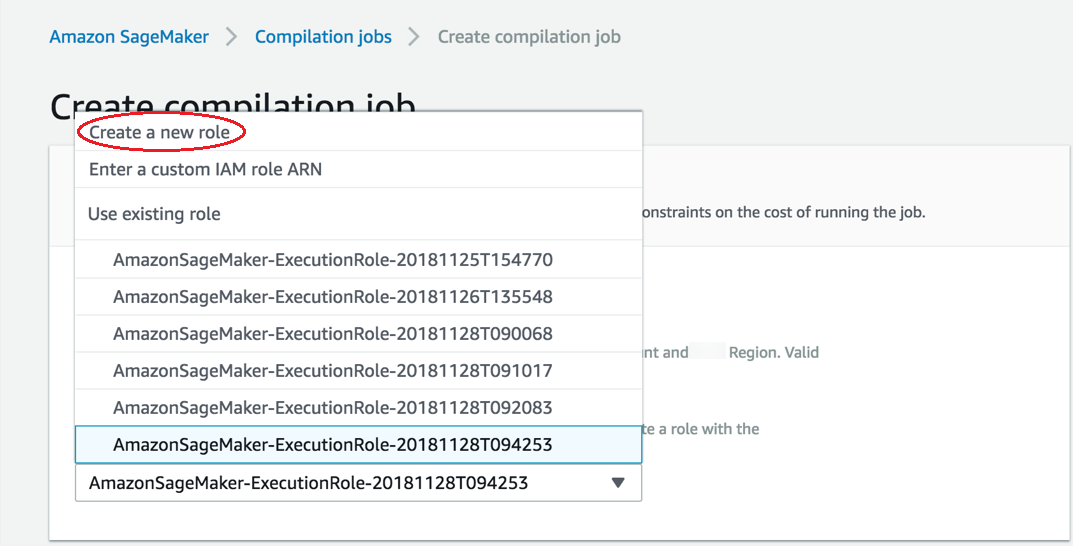
如果您没有 IAM 角色,请选择 Create a new role (创建新角色)。
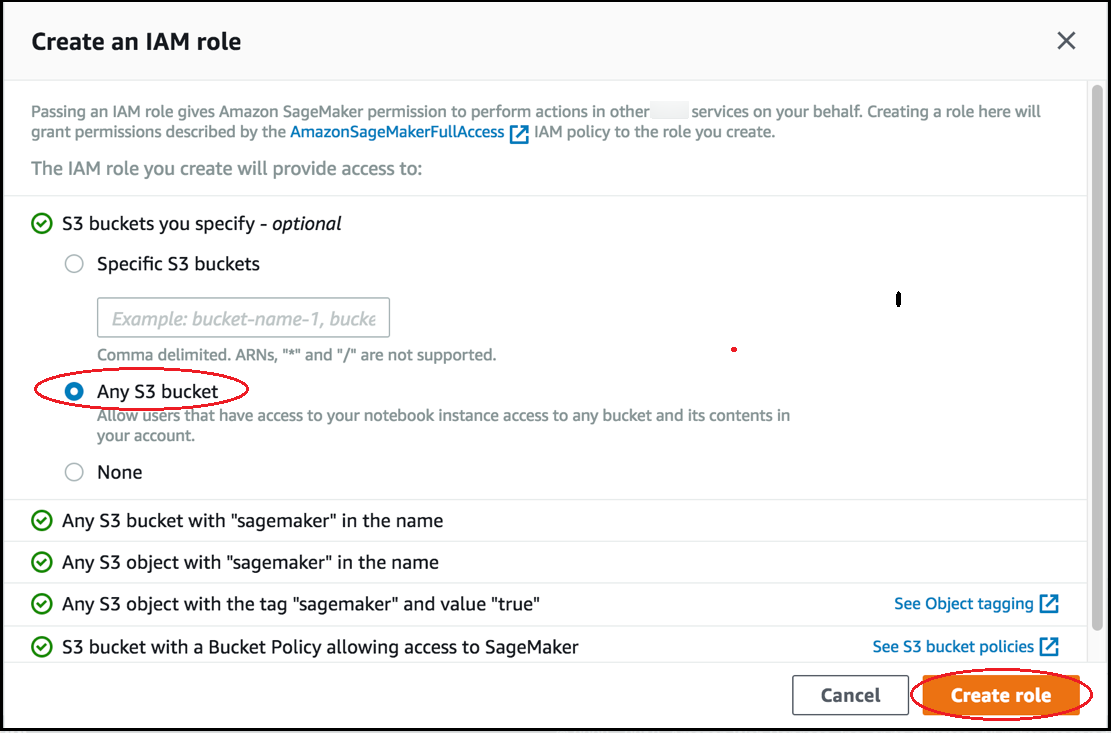
在 Create an IAM role (创建 IAM 角色) 页面上,选择 Any S3 bucket (任意 S3 存储桶),然后选择 Create role (创建角色)。
-
-
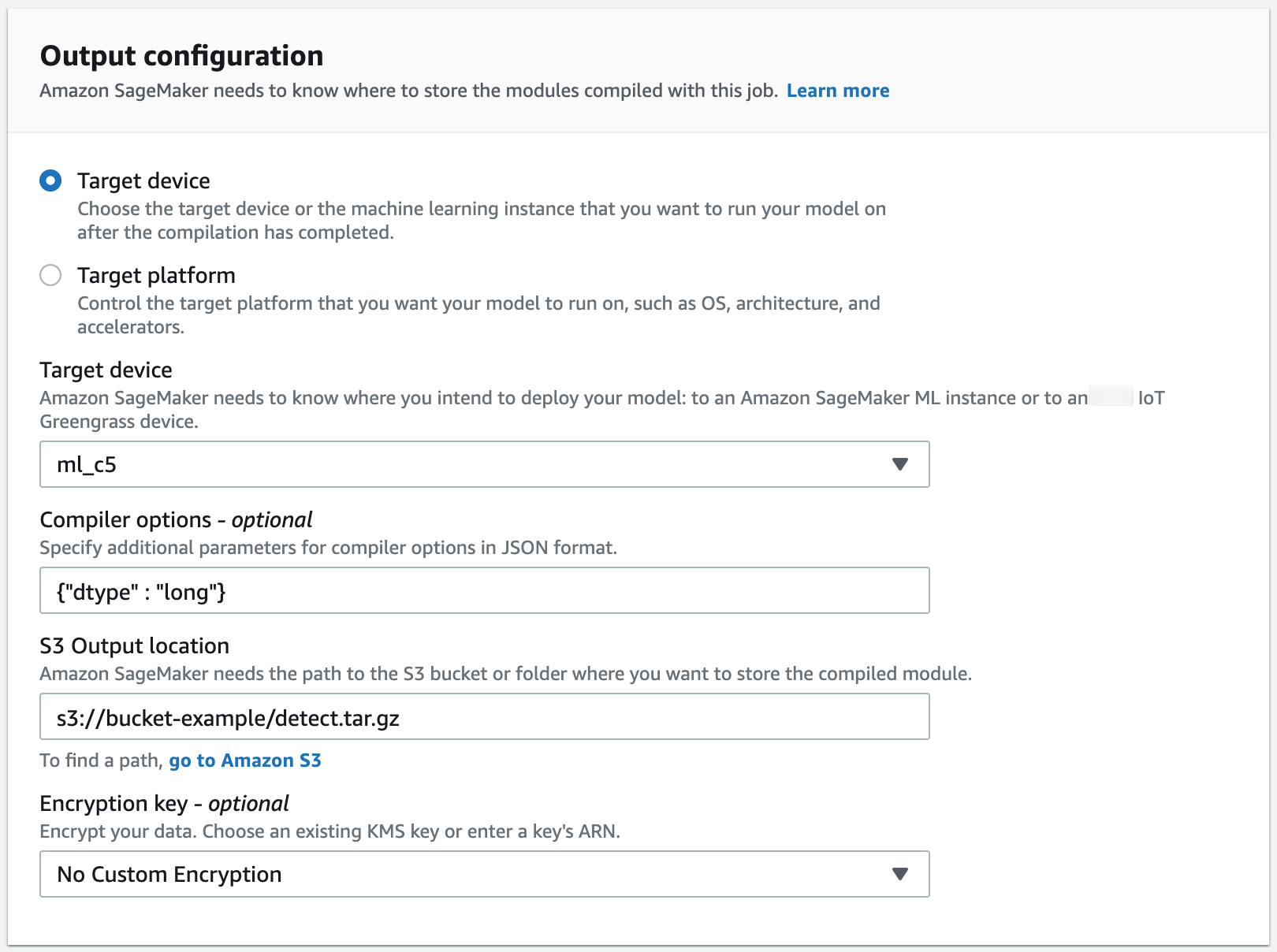
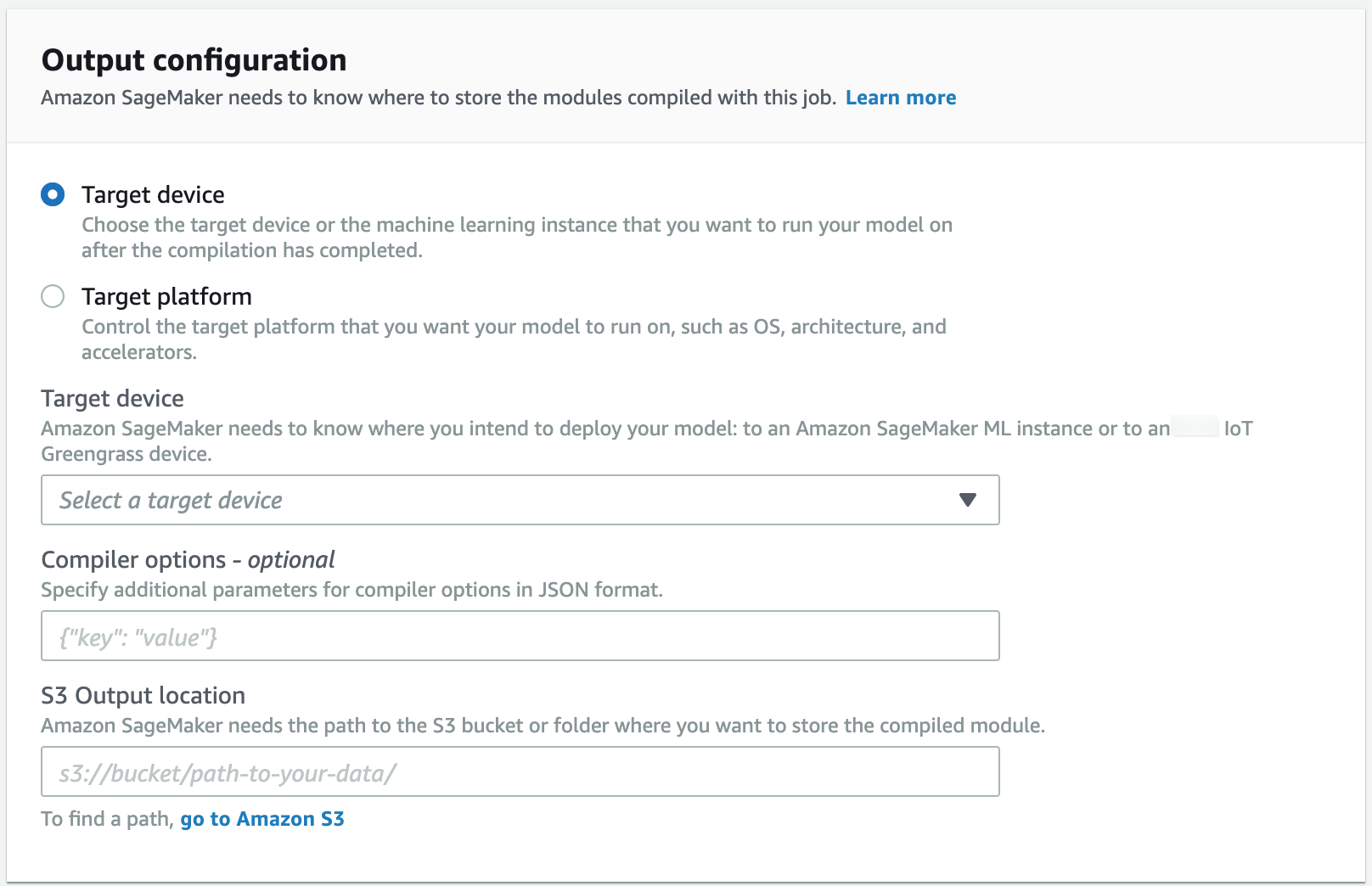
转到输出配置部分。选择要部署模型的位置。您可以将模型部署到目标设备或者目标平台。目标设备包括云和边缘设备。目标平台是指您希望模型在其上运行的特定操作系统、架构和加速器。
对于 S3 输出位置,请输入要在其中存储模型的 S3 存储桶的路径。您可以选择在编译器选项部分使用 JSON 格式添加编译器选项。
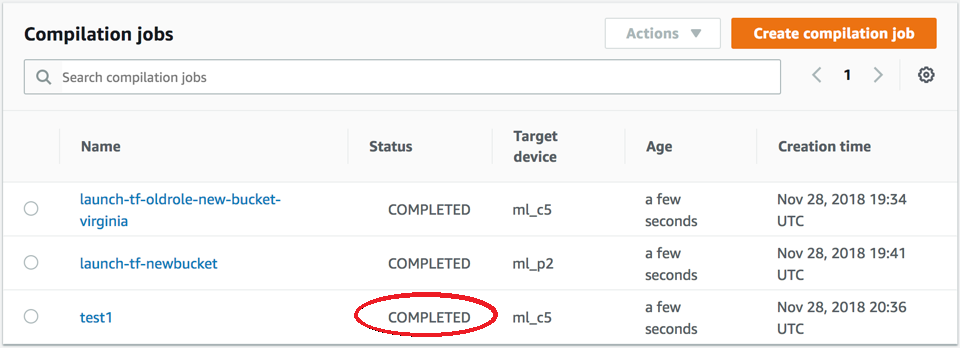
在启动时检查编译作业的状态。该作业状态可以在编译作业页面的顶部找到,如以下屏幕截图所示。您也可以在状态列中查看其状态。
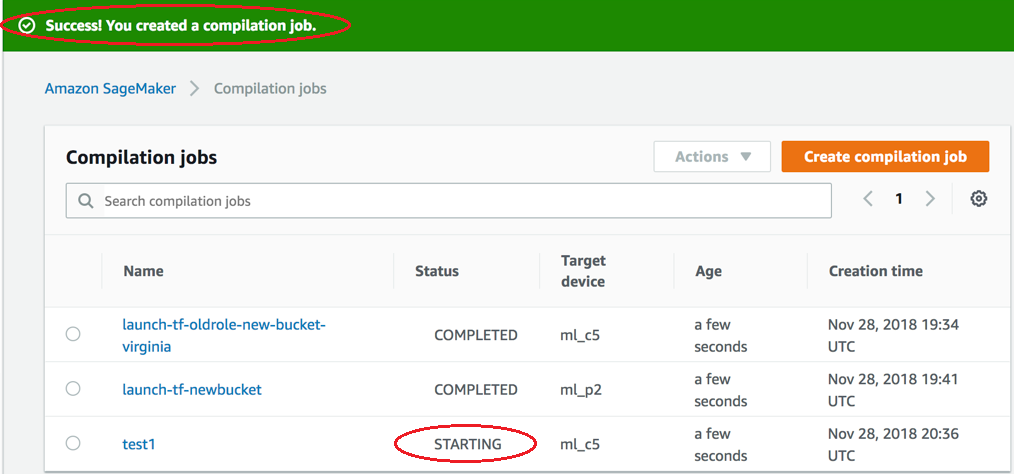
在完成时检查编译作业的状态。您可以在状态列中查看状态,如以下屏幕截图所示。