本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Object2Vec 工作原理
使用 Amazon SageMaker AI Object2Vec 算法时,您需要遵循标准工作流程:处理数据、训练模型和生成推论。
步骤 1:处理数据
在预处理过程中,将数据转换为在Object2Vec 训练的数据格式中指定的 JSON 行np.random.shuffle;对于 Unix,您可以使用 shuf。
步骤 2:训练模型
SageMaker AI Object2Vec 算法具有以下主要组成部分:
-
两个输入通道 – 输入通道将一对相同或不同类型的对象作为输入,并将它们传递给独立的可自定义编码器。
-
两个编码器 – 两个编码器(enc0 和 enc1)将每个对象转换为固定长度的嵌入向量。然后,将对中的对象的编码嵌入传递到比较器中。
-
比较器 – 比较器以不同方式比较嵌入,并输出分数以表示成对对象之间的关系强度。例如,在句子对的输出分数中,1 表示句子对之间的关系较强,0 表示关系较弱。
在训练期间,该算法接受成对的对象及其关系标签或分数以作为输入。每个对中的对象可以具有不同的类型,如上所述。如果两个编码器的输入由相同的标记级单元组成,您可以在创建训练作业时将 tied_token_embedding_weight 超参数设置为 True 以使用共享标记嵌入层。例如,在比较两个具有单词标记级单元的句子时,可以执行该操作。要以指定的速率生成负样本,请将 negative_sampling_rate 超参数设置为所需的负样本/正样本比率。该超参数加快学习如何区分在训练数据中观察到的正样本和不太可能观察到的负样本。
对象对是通过独立的可自定义编码器传递的,这些编码器与相应对象的输入类型兼容。这些编码器将一个对中的每个对象转换为长度相等的固定长度嵌入向量。向量对传递到比较器运算符,该运算符使用 comparator_list 超参数中指定的值将向量合并为单个向量。然后,合并的向量通过多层感知机 (MLP) 层进行传递,该层生成输出,损失函数将输出与您提供的标签进行比较。这种比较评估对中的对象之间的关系强度,如模型中所预测的一样。下图显示了该工作流。
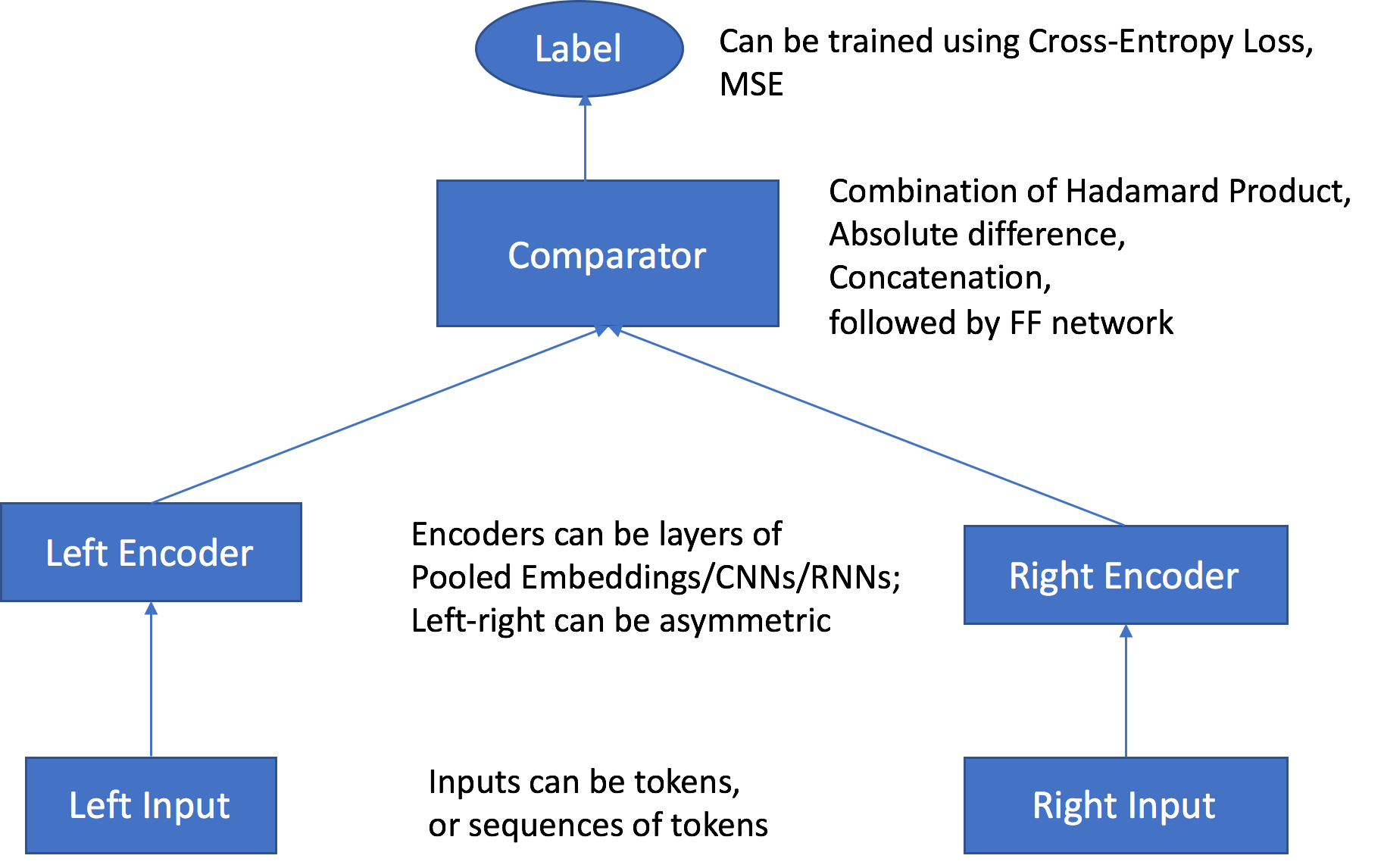
从数据输入到分数的 Object2Vec 算法架构
步骤 3:生成推理
训练模型后,您可以使用经过训练的编码器来预处理输入对象或执行两种类型的推理:
-
使用相应的编码器将单个输入对象转换为固定长度的嵌入
-
预测一对输入对象之间的关系标签或分数
推理服务器根据输入数据自动确定请求哪种类型。要将嵌入作为输出,请仅提供一个输入。要预测关系标签或分数,请在该对中同时提供两个输入。