本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
带 SageMaker 处理功能的数据转换工作负载
SageMaker 处理是指 AI 在 SageMaker 人工智能完全托管的基础架构上 SageMaker 运行数据预处理和后处理、特征工程和模型评估任务的能力。这些任务作为处理作业执行。以下内容提供了有关 SageMaker 处理的信息和资源。
使用 P SageMaker rocessing API,数据科学家可以运行脚本和笔记本来处理、转换和分析数据集,为机器学习做好准备。与 SageMaker AI 提供的其他关键机器学习任务(例如训练和托管)相结合,Processing 可为您提供完全托管的机器学习环境的优势,包括 SageMaker AI 内置的所有安全性和合规性支持。您可以灵活地使用内置的数据处理容器,也可以使用自己的容器进行自定义处理逻辑,然后提交作业以在 SageMaker AI 托管基础设施上运行。
注意
您可以使用 SageMaker AI 支持的任何语言调用 CreateProcessingJobAPI 操作或使用,以编程方式创建处理作业。 Amazon CLI有关此 API 操作如何转换为您所选语言的函数的信息,请参阅的 “另请参阅” 部分 CreateProcessingJob 并选择 SDK。例如,对于 Python 用户,请参阅 Pyt SageMaker hon 软件开发工具包的亚马逊 SageMaker 处理
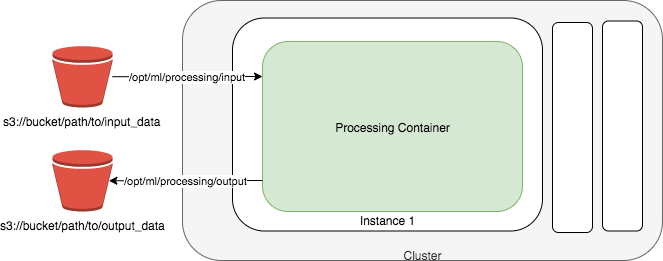
下图显示了 Amazon SageMaker AI 如何启动处理任务。Amazon SageMaker AI 获取您的脚本,从亚马逊简单存储服务 (Amazon S3) 复制您的数据,然后提取处理容器。处理任务的底层基础设施完全由 Amazon A SageMaker I 管理。在您提交处理任务后, SageMaker AI 会启动计算实例,处理和分析输入数据,并在完成后释放资源。处理作业的输出存储在您指定的 Amazon S3 存储桶中。
注意
输入数据必须存储在 Amazon S3 存储桶中。或者,您可以使用 Amazon Athena 或 Amazon Redshift 作为输入源。
提示
要了解机器学习 (ML) 训练和处理作业的分布式计算最佳实践,请参阅采用 SageMaker AI 最佳实践进行分布式计算。
使用 Amazon SageMaker 处理示例笔记本
我们提供两个示例 Jupyter 笔记本,以展示如何执行数据预处理、模型评估或这两者。
有关演示如何运行 scikit-learn 脚本以使用 Pyth SageMaker on SDK 进行数据预处理以及模型训练和评估的示例笔记本,请参阅 scikit-learn 处理。
有关演示如何使用 Amazon Processing SageMaker 通过 Spark 执行分布式数据预处理的示例笔记本,请参阅分布式处理 (Spark)
有关如何创建和访问可用于在 SageMaker AI 中运行这些示例的 Jupyter 笔记本实例的说明,请参阅。Amazon SageMaker 笔记本实例创建并打开笔记本实例后,选择 “SageMaker AI 示例” 选项卡以查看所有 SageMaker AI 示例的列表。要打开笔记本,请选择其使用选项卡,然后选择创建副本。
使用 CloudWatch 日志和指标监控 Amazon SageMaker 处理任务
Amazon SageMaker Processing 提供亚马逊 CloudWatch 日志和指标来监控处理任务。 CloudWatch 提供 CPU、GPU、内存、GPU 内存和磁盘指标以及事件记录。有关更多信息,请参阅亚马逊中的亚马逊 A SageMaker I 指标 CloudWatch和CloudWatch 亚马逊 A SageMaker I 的日志。