本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
为实时推理部署模型
重要
允许 Amazon SageMaker Studio 或 Amazon SageMaker Studio Classic 创建亚马逊 SageMaker资源的自定义 IAM 策略还必须授予向这些资源添加标签的权限。之所以需要为资源添加标签的权限,是因为 Studio 和 Studio Classic 会自动为创建的任何资源添加标签。如果 IAM 策略允许 Studio 和 Studio Classic 创建资源但不允许标记,则在尝试创建资源时可能会出现 AccessDenied “” 错误。有关更多信息,请参阅 提供标记 A SageMaker I 资源的权限。
Amazon 亚马逊 A SageMaker I 的托管策略授予创建 SageMaker 资源的权限已经包括在创建这些资源时添加标签的权限。
使用 SageMaker AI 托管服务部署模型有多种选择。您可以使用 SageMaker Studio 以交互方式部署模型。或者,你可以使用 SDK(例如 Python Amazon SDK 或 SageMaker Python SDK for Boto3),以编程方式部署模型。您也可以使用进行部署 Amazon CLI。
开始前的准备工作
在部署 A SageMaker I 模型之前,请找到并记下以下内容:
-
您的 Amazon Web Services 区域 Amazon S3 存储桶所在的位置
-
存储模型构件的 Amazon S3 URI 路径
-
SageMaker 人工智能的 IAM 角色
-
包含推理代码的自定义镜像的 Docker Amazon ECR URI 注册表路径,或者支持和支持的内置 Docker 镜像的框架和版本 Amazon
有关每个地图中 Amazon Web Services 服务 可用的列表 Amazon Web Services 区域,请参阅区域地图和边缘网络
重要
存储模型构件的 Amazon S3 存储桶必须与所创建的模型位于相同 Amazon Web Services 区域 中。
多种模式的资源共享利用
您可以使用 Amazon A SageMaker I 将一个或多个模型部署到终端节点。当多个模型共享一个端点时,它们会共同使用该端点托管的资源,如 ML 计算实例、CPU 和加速器。将多个模型部署到一个端点的最灵活方法是将每个模型定义为一个推理组件。
推理组件
推理组件是一个 SageMaker AI 托管对象,可用于将模型部署到终端节点。在推理组件设置中,您可以指定模型、端点以及模型如何利用端点托管的资源。要指定模型,您可以指定 A SageMaker I 模型对象,也可以直接指定模型伪影和图像。
在设置中,您可以通过自定义如何为模型分配所需的 CPU 内核、加速器和内存来优化资源利用率。您可以为一个端点部署多个推理组件,每个推理组件包含一个模型和该模型的资源利用需求。
部署推理组件后,您可以在 SageMaker API 中使用 InvokeEndpoint 操作时直接调用关联的模型。
推理组件具有以下优点
- 弹性
-
推理组件将托管模型的细节与端点本身分离开来。这样就能更灵活地控制端点托管和提供模型的方式。您可以在同一基础设施上托管多个模型,也可以根据需要从端点添加或删除模型。您可以独立更新每个模型。
- 可扩展性
-
您可以指定要托管的每个模型的副本数量,还可以设置副本的最低数量,以确保模型加载的数量符合服务请求的要求。您可以将任何推理组件副本缩减为零,这样就可以为另一个副本的缩放腾出空间。
SageMaker 当您使用以下方法部署模型时,AI 会将模型打包为推理组件:
-
SageMaker 经典工作室。
-
用于部署模型对象的 SageMaker Python SDK(将终端节点类型设置为其中
EndpointType.INFERENCE_COMPONENT_BASED)。 -
用于定义部署 适用于 Python (Boto3) 的 Amazon SDK 到终端节点的
InferenceComponent对象。
使用 SageMaker Studio 部署模型
完成以下步骤,通过 SageMaker Studio 以交互方式创建和部署模型。有关 Studio 的更多信息,请参阅 Studio 文档。有关各种部署场景的更多演练,请参阅博客 Package 并使用 Amazon A SageMaker I 轻松部署经典机器学习模型和 LLM — 第 2 部分
准备构件和权限
在 SageMaker Studio 中创建模型之前,请先完成本节。
在 Studio 中,您有两种方法来获取构件和创建模型:
-
您可以携带预先打包好的
tar.gz存档,其中应包括模型构件、任何自定义推理代码以及requirements.txt文件中列出的任何依赖关系。 -
SageMaker AI 可以为你打包你的神器。你只需要将原始模型工件和任何依赖项带到
requirements.txt文件中, SageMaker AI 就可以为你提供默认的推理代码(或者你可以用自己的自定义推理代码覆盖默认代码)。 SageMaker 人工智能支持以下框架的此选项: PyTorch,xgBoost。
除了带上您的模型、您的 Amazon Identity and Access Management (IAM) 角色和 Docker 容器(或 A SageMaker I 具有预构建容器的所需框架和版本)外,您还必须授予通过 AI Stud SageMaker io 创建和部署模型的权限。
您应该将AmazonSageMakerFullAccess策略附加到您的 IAM 角色上,这样您就可以访问 SageMaker AI 和其他相关服务。要在 Studio 中查看实例类型的价格,您还必须附加Amazon PriceListServiceFullAccess政策(或者如果您不想附加整个政策,更具体地说,就是pricing:GetProducts操作)。
如果您选择在创建模型时上传模型构件(或上传样本有效载荷文件以获得推理建议),则必须创建一个 Amazon S3 存储桶。存储桶名称的前缀必须是 SageMaker AI。 SageMaker 人工智能的替代大写形式也是可以接受的:Sagemaker或。sagemaker
我们建议您使用存储桶命名规范 sagemaker-{。该存储桶用于存储您上传的构件。Region}-{accountID}
创建存储桶后,将以下 CORS(跨源资源共享)策略附加到存储桶:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
您可以使用以下任一方法将 CORS 策略附加到 Amazon S3 存储桶:
-
通过 Amazon S3 管理控制台中的编辑跨源资源共享(CORS)
页面 -
使用亚马逊 S3 API PutBucketCors
-
使用 put-bucket-cors 命令 Amazon CLI :
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
创建可部署模型
在此步骤中,您将通过提供构件以及其他规范(例如所需的容器和框架、任何自定义推理代码和网络设置)来在 SageMaker AI 中创建模型的可部署版本。
通过执行以下操作在 SageMaker Studio 中创建可部署模型:
-
打开 SageMaker Studio 应用程序。
-
在左侧导航窗格中,选择 模型。
-
选择可部署模型选项卡。
-
在可部署模型页面,选择创建。
-
在创建可部署模型页面上,在模型名称字段中输入模型名称。
在创建可部署模型页面上还有几个部分需要填写。
容器定义部分看起来就像下面的界面截图:
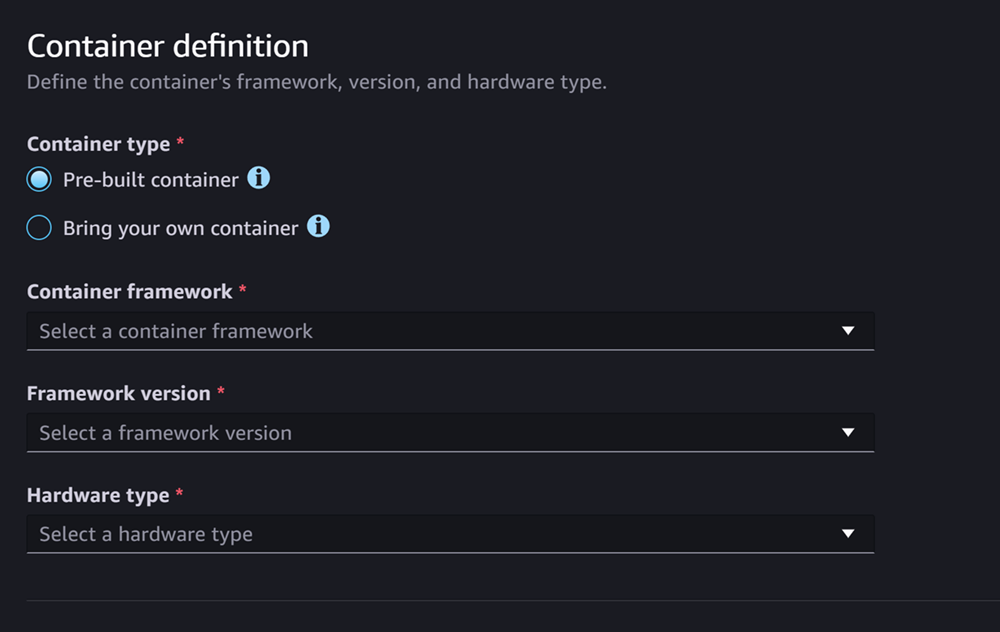
对于 容器定义 部分,执行以下操作:
-
对于容器类型,如果您想使用 SageMaker AI 托管的容器,请选择容器;如果您有自己的容器,请选择自带容器。Pre-built
-
如果您选择了Pre-built 容器,请选择要使用的容器框架、框架版本和硬件类型。
-
如果您选择了自带容器,请为容器映像的 ECR 路径输入 Amazon ECR 路径。
然后,填写构件部分,如下界面截图所示:

对于 构件 部分,执行以下操作:
-
如果你使用的是 SageMaker AI 支持的框架之一来打包模型工件(PyTorch 或 XGBoost),那么对于构件,你可以选择上传工件选项。使用此选项,您可以简单地指定原始模型工件、您拥有的任何自定义推理代码以及 requirements.txt 文件, SageMaker AI 会为您打包存档。执行以下操作:
-
在构件中,选择上传构件继续提供文件。否则,如果您已经有一个包含模型文件、推理代码和
requirements.txt文件的tar.gz存档,则选择输入 S3 URI 到预打包构件。 -
如果您选择上传项目,则对于 S3 存储桶,请输入 Amazon S3 路径,指向您希望 SageMaker AI 在为您打包工件后将其存储在其中存储的存储桶。然后,完成以下步骤。
-
对于上传模型构件,请上传模型文件。
-
对于推理代码,如果您想使用 SageMaker AI 提供的用于提供推理的默认代码,请选择使用默认推理代码。否则,请选择上传自定义推理代码,以使用您自己的推理代码。
-
对于上传 requirements.txt,请上传一个文本文件,其中列出要在运行时安装的任何依赖关系。
-
-
如果您没有使用 A SageMaker I 支持的框架来打包模型工件,Studio 会显示Pre-packaged构件选项,并且您必须提供所有已打包为
tar.gz存档的构件。执行以下操作:-
对于Pre-packaged 构件,如果您已将
tar.gz档案上传到 Amazon S3,请为预打包的模型工件选择输入 S3 URI。如果您想直接将存档上传到 SageMaker AI,请选择上传预先打包的模型工件。 -
如果您选择了预打包模型构件的输入 S3 URI,请为 S3 URI 输入存档的 Amazon S3 路径。否则,请选择并从本地计算机上传存档。
-
下一部分是安全性,界面截图如下:
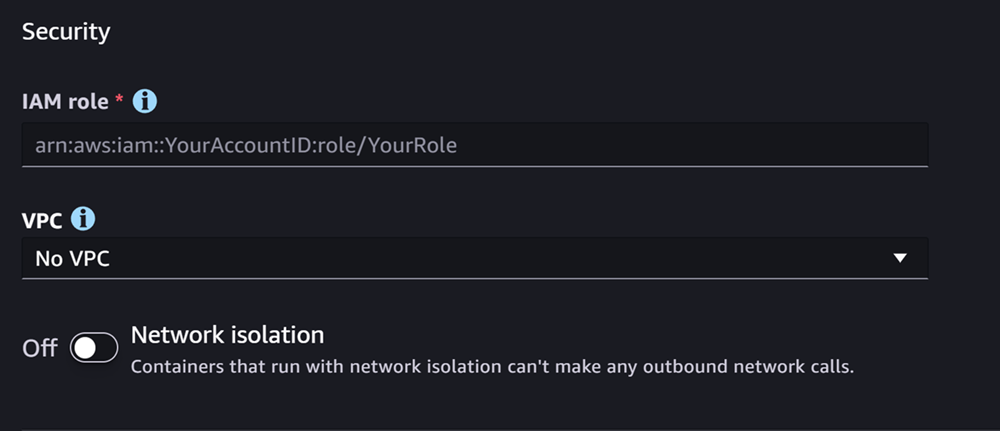
对于 安全性 部分,执行以下操作:
-
对于 IAM 角色,输入 IAM 角色的 ARN。
-
(可选)对于虚拟私有云(VPC),您可以选择一个 Amazon VPC 来存储模型配置和构件。
-
(可选)如果您要限制容器的互联网访问,请打开网络隔离开关。
最后,您可以选择填写高级选项部分,如下界面截图所示:
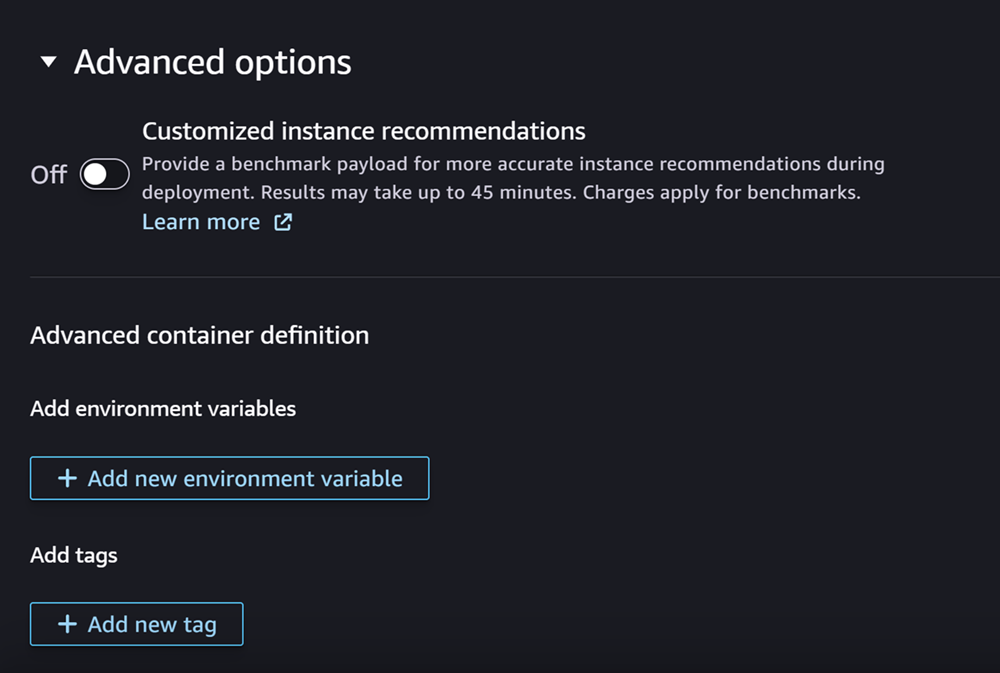
(可选)对于 高级选项 部分,执行以下操作:
-
如果您想在模型创建后对其运行 Amazon SageMaker Inference 推荐器作业,请打开自定义实例推荐开关。Inference Recommender 是一项为您提供推荐实例类型的功能,用于优化推理性能和成本。您可以在准备部署模型时查看这些实例建议。
-
在添加环境变量中,为容器输入键值对形式的环境变量。
-
在标签中,以键值对形式输入任何标签。
-
完成模型和容器配置后,选择创建可部署模型。
现在 SageMaker Studio 中应该有一个可以部署的模型。
部署模型
最后,将上一步配置的模型部署到 HTTPS 端点。您可以将单个模型或多个模型部署到端点。
模型和端点兼容性
在将模型部署到端点之前,模型和端点必须兼容,以下设置的值必须相同:
-
IAM 角色
-
Amazon VPC,包括其子网络和安全组
-
网络隔离(启用或禁用)
Studio 可通过以下方式防止您将模型部署到不兼容的端点:
-
如果您尝试将模型部署到新的终端节点, SageMaker AI 会使用兼容的初始设置配置该终端节点。如果您更改了这些设置,破坏了兼容性,Studio 就会显示警告并阻止您的部署。
-
如果您尝试部署到现有端点,而该端点不兼容,Studio 会显示警告并阻止部署。
-
如果您尝试将多个模型添加到部署中,Studio 会阻止您部署彼此不兼容的模型。
当 Studio 显示有关模型和端点不兼容的警告时,您可以在警告中选择查看详情,以查看哪些设置不兼容。
部署模型的一种方法是在 Studio 中执行以下操作:
-
打开 SageMaker Studio 应用程序。
-
在左侧导航窗格中,选择 模型。
-
在模型页面上,从 SageMaker AI 模型列表中选择一个或多个模型。
-
选择部署。
-
为端点名称打开下拉菜单。您可以选择一个现有的端点,也可以创建一个新的端点来部署模型。
-
在实例类型中,选择要用于端点的实例类型。如果您之前为模型运行过推理推荐作业,那么您推荐的实例类型就会出现在列表中,标题为推荐。否则,您会看到一些可能适合您的模型的预测性实例。
的实例类型兼容性 JumpStart
如果您正在部署 JumpStart 模型,Studio 仅显示该模型支持的实例类型。
-
对于初始实例数,请输入您希望为端点配置的初始实例数。
-
对于最大实例数,指定端点纵向扩展以适应流量增加时可提供的最大实例数。
-
如果您要部署的模型是模型中心中最常用的 JumpStart LLM 之一,则在实例类型和实例计数字段之后会显示替代配置选项。
对于最受欢迎的 JumpStart LLM, Amazon 有预先基准测试的实例类型,可以针对成本或性能进行优化。这些数据可以帮助您决定使用哪种实例类型来部署 LLM。选择其他配置,打开包含预设基准数据的对话框。面板看起来就像下面的界面截图:
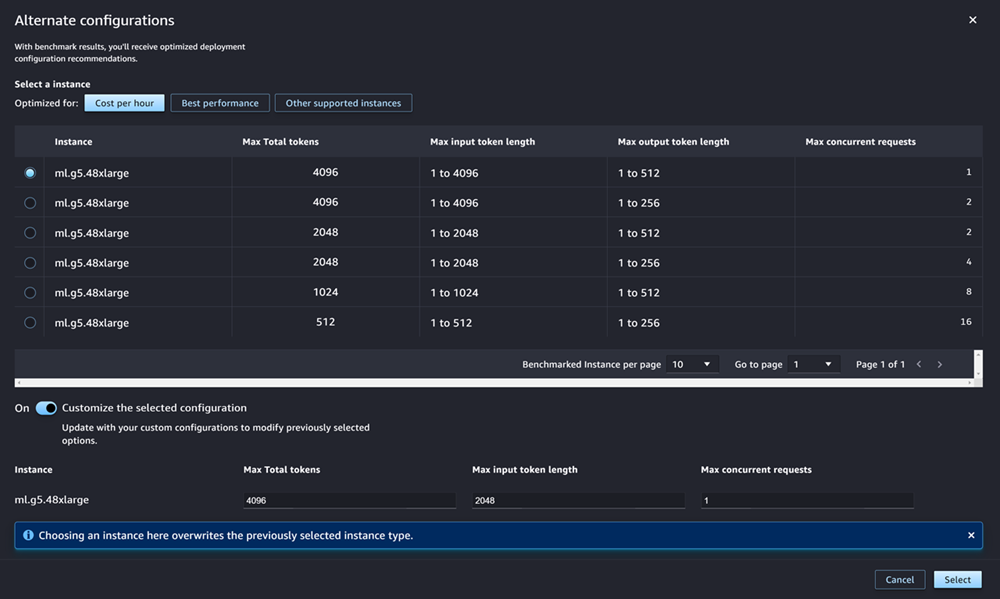
在其他配置框中执行以下操作:
-
选择一个实例类型。您可以选择每小时成本或最佳性能,查看为指定模型优化成本或性能的实例类型。您也可以选择 “其他支持的实例”,查看与该 JumpStart 模型兼容的其他实例类型的列表。请注意,在此选择实例类型会覆盖之前在步骤 6 中指定的任何实例选择。
-
(可选)打开自定义所选配置开关,以指定最大总令牌数(允许的最大令牌数,即输入令牌数与模型生成的输出之和)、最大输入令牌长度(允许每个请求输入的最大令牌数)和最大并发请求数(模型一次可处理的最大请求数)。
-
选择选择确认实例类型和配置设置。
-
-
模型字段应已填入要部署的一个或多个模型的名称。您可以选择添加模型将更多模型添加到部署中。对于添加的每个模型,请填写以下字段:
-
在 CPU 内核数中,输入您希望专用于模型使用的 CPU 内核数。
-
在副本的最小数量中,输入您希望在任何给定时间在端点上托管的模型副本的最小数量。
-
在最小 CPU 内存 (MB)中,输入模型所需的最小内存量(单位:MB)。
-
在最大 CPU 内存 (MB)中,输入允许模型使用的最大内存容量(单位:MB)。
-
-
(可选)对于高级选项,执行以下操作:
-
对于 IAM 角色,请使用默认 A SageMaker I IAM 执行角色,或者指定自己拥有所需权限的角色。请注意,此 IAM 角色必须与创建可部署模型时指定的角色相同。
-
对于虚拟私有云(VPC),您可以指定一个 VPC 来托管端点。
-
对于加密 KMS 密 Amazon KMS 钥,选择一个密钥来加密连接到托管终端节点的 ML 计算实例的存储卷上的数据。
-
打开启用网络隔离开关,以限制容器的互联网访问。
-
在超时配置中,输入模型数据下载超时(秒)和容器启动运行状况检查超时(秒)字段的值。这些值分别确定 SageMaker AI 允许将模型下载到容器和启动容器的最大时间。
-
在标签中,以键值对形式输入任何标签。
注意
SageMaker AI 使用与您正在部署的模型兼容的初始值配置 IAM 角色、VPC 和网络隔离设置。如果您更改了这些设置,破坏了兼容性,Studio 就会显示警告并阻止您的部署。
-
配置完选项后,页面应如下界面截图所示。
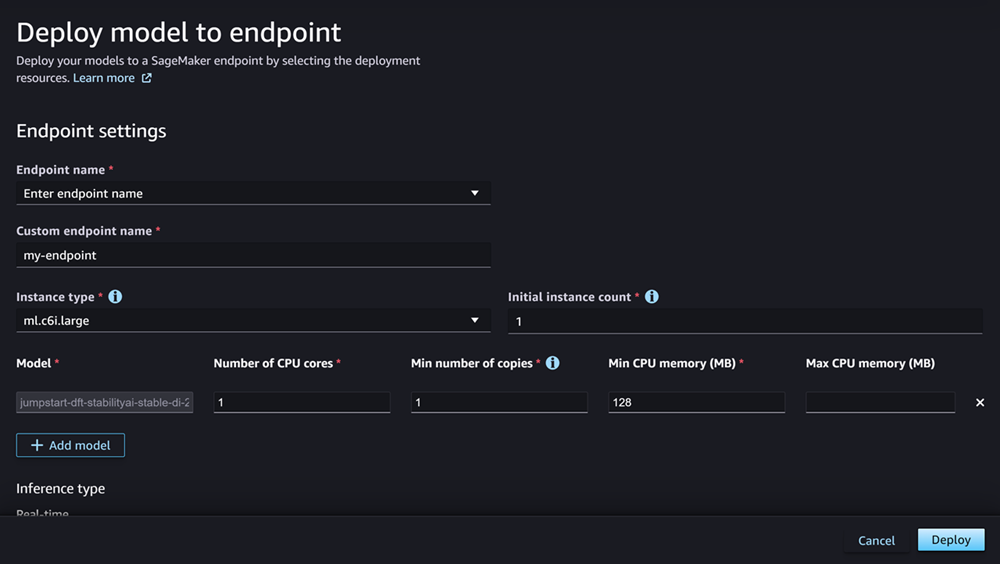
配置部署后,选择部署创建端点并部署模型。
使用 Python SDK 部署模型
使用 SageMaker Python SDK,您可以通过两种方式构建模型。首先,从 Model 或 ModelBuilder 类中创建一个模型对象。如果您使用 Model 类创建 Model 对象,则需要指定模型包或推理代码(取决于模型服务器)、处理客户端与服务器之间数据序列化和反序列化的脚本,以及上传到 Amazon S3 供使用的任何依赖关系。构建模型的第二种方法是使用 ModelBuilder,并为其提供模型构件或推理代码。ModelBuilder 会自动捕捉您的依赖关系,推导出所需的序列化和反序列化函数,并将您的依赖关系打包,创建您的 Model 对象。有关 ModelBuilder的更多信息,请参阅使用 Amazon A SageMaker I 创建模型 ModelBuilder。
下文将介绍创建模型和部署模型对象的两种方法。
设置
以下示例为模型部署过程做了准备。它们导入必要的库,并定义用于定位模型构件的 S3 URL。
例模型构件 URL
以下代码构建了一个 Amazon S3 URL 示例。该 URL 可定位 Amazon S3 存储桶中预训练模型的模型构件。
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
完整的 Amazon S3 URL 保存在变量 model_url 中,并在下面的示例中使用。
概述
您可以通过多种方式使用 SageMaker Python SDK 或适用于 Python 的 SDK (Boto3) 部署模型。以下章节总结了几种可能方法的操作步骤。下面的示例演示了这些步骤。
配置
以下示例配置了将模型部署到端点所需的资源。
部署
以下示例将模型部署到端点。
使用部署模型 Amazon CLI
您可以使用将模型部署到终端节点 Amazon CLI。
概述
使用部署模型时 Amazon CLI,无论是否使用推理组件,都可以部署模型。以下章节概述了这两种方法下运行的命令。下面的示例将演示这些命令。
配置
以下示例配置了将模型部署到端点所需的资源。
部署
以下示例将模型部署到端点。