本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
集体通信初始化改进
NCCL 和 Gloo 是基本的通信库,可实现分布式训练过程中的集体操作(例如全缩和广播)。但是,传统的 NCCL 和 Gloo 初始化可能会在故障恢复期间造成瓶颈。
标准恢复过程要求所有进程都连接到集中式 TCPStore 并通过根进程进行协调,这会带来昂贵的开销,在重启期间尤其成问题。这种集中式设计带来了三个关键问题:强制性 TCPStore 连接产生的协调开销、每次重启都必须重复完整的初始化序列而导致的恢复延迟,以及根进程本身的单点故障。这要求每次训练初始化或重新启动时都需要执行昂贵的集中式协调步骤。
HyperPod 无检查点训练消除了这些协调瓶颈,通过使初始化 “无根” 和 “tcpstoreLess”,可以更快地从故障中恢复。
无根配置
要启用 Rootless,只需公开以下环境变量即可。
export HPCT_USE_ROOTLESS=1 && \ sysctl -w net.ipv4.ip_local_port_range="20000 65535" && \
HPCT_USE_ROOTLESS:0 或 1。用于无根开启和关闭
sysctl-w net.ipv4.ip_local_port_range= “20000 65535":设置系统端口范围
请参阅启用 Rootless 的示例
无根
HyperPod checkpointless 训练为 NCCL 和 Gloo 过程组提供了新颖的初始化方法,即 Rootless 和 tcpStoreLess。
这些优化的实现包括修改 NCCL、Gloo 和: PyTorch
扩展第三方库 API 以启用 Rootless 和 Storeless NCCL 和 Gloo优化,同时保持向后兼容性
更新进程组后端以有条件地使用优化的路径并处理进程内恢复问题
绕过 PyTorch 分布层昂贵的 TcpStore 创建,同时通过全局组计数器保持对称地址模式
下图显示了分布式训练库的架构以及无检查点训练中所做的更改。
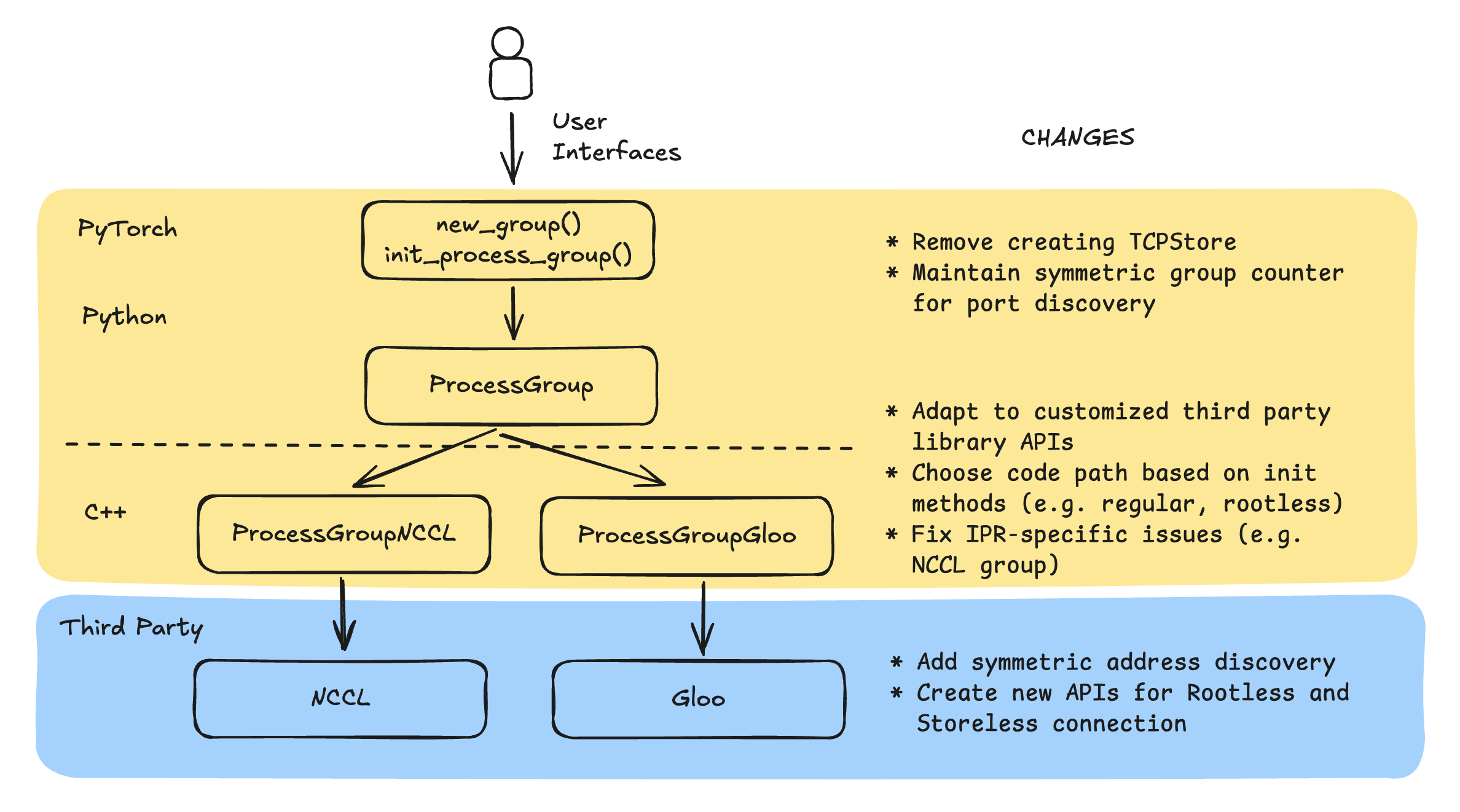
NCCL 和 Gloo
这些是独立的软件包,用于执行集体通信的核心功能。它们提供关键 API,例如 ncclCommInitRank,用于初始化通信网络、管理底层资源和执行集体通信。在 NCCL 和 Gloo 中进行自定义更改后,Rootless 和 Storeless 会优化通信网络的初始化(例如,跳过连接到 TCPStore)。您可以在使用原始代码路径或优化的代码路径之间灵活切换。
PyTorch 进程组后端
进程组后端,特别是 ProcessGroup NCCL 和 ProcessGroupGloo,通过调用相应底 ProcessGroup 层库的 API 来实现 API。由于我们扩展了第三方库的 API,因此我们必须正确调用它们并根据客户的配置进行代码路径切换。
除了优化代码路径外,我们还更改了流程组后端以支持进程内恢复。