本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
内存映射的数据加载器
另一个重启开销源于数据加载:在数据加载器初始化、从远程文件系统下载数据并将其分批处理时,训练集群保持空闲状态。
为了解决这个问题,我们引入了内存映射 DataLoader (MMAP) Dataloader,它可以将预取的批次缓存在永久内存中,确保即使在故障引起的重启之后,它们仍然可用。这种方法省去了数据加载器的设置时间,使训练能够使用缓存的批次立即恢复,而数据加载器同时在后台重新初始化并获取后续数据。数据缓存位于需要训练数据的每个等级上,并维护两种类型的批次:用于训练的最近消耗的批次和可立即使用的预取批次。
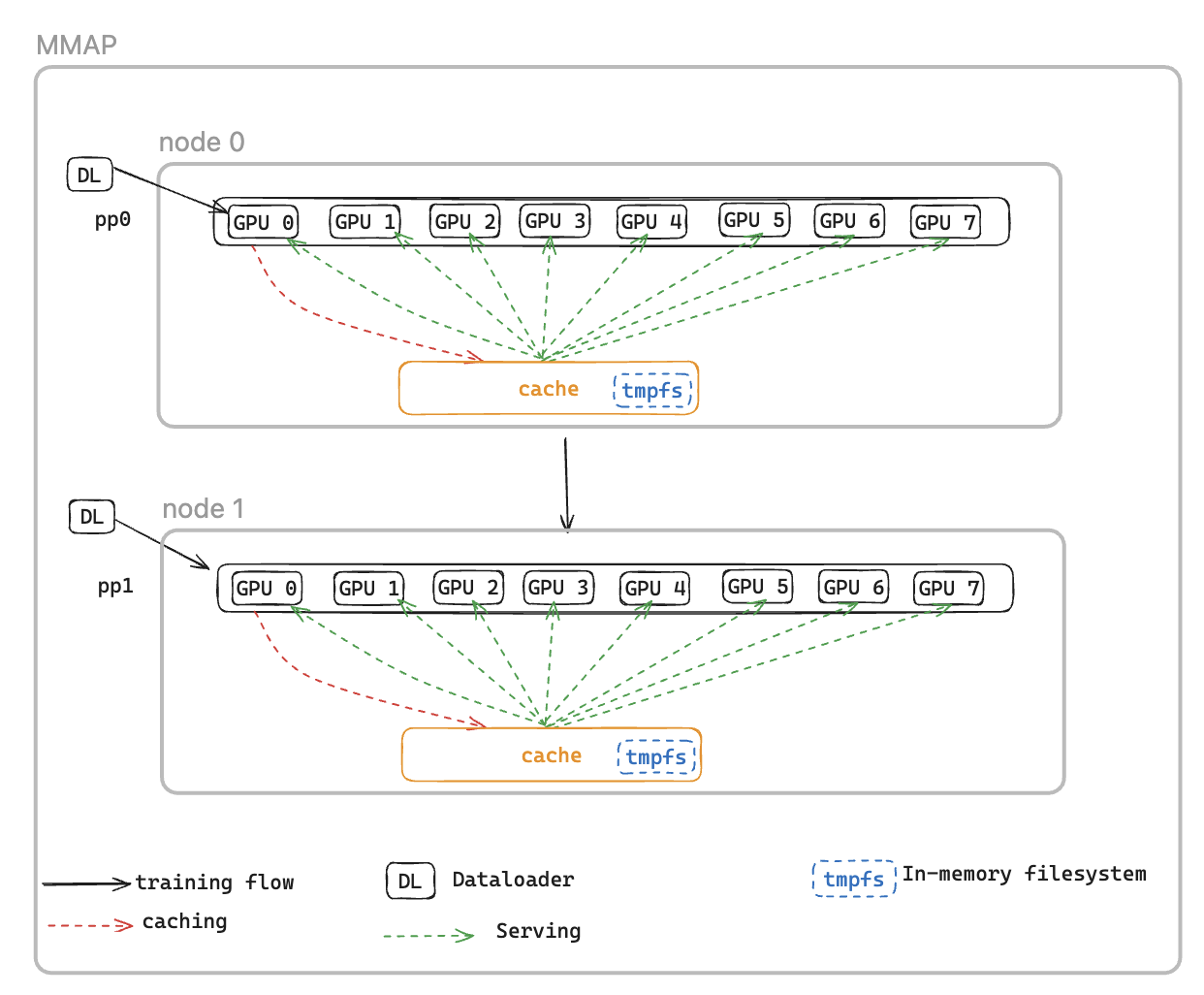
MMAP 数据加载器提供以下两个功能:
数据预取-主动获取和缓存数据加载器生成的数据
永久缓存-将已消耗的批次和预取的批次存储在进程重启后的临时文件系统中
使用缓存,训练作业将受益于:
减少内存占用-利用内存映射 I/O 在主机 CPU 内存中维护数据的单个共享副本,从而消除了 GPU 进程间的冗余副本(例如,在具有 8 个 GPU 的 p5 实例上,从 8 个副本减少到 1 个)
更快的恢复-允许从缓存的批次中立即恢复训练,无需等待数据加载器重新初始化和第一批生成,从而缩短平均重启时间 (MTTR)
MMAP 配置
要使用 MMAP,只需将您的原始数据模块传入 MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: MMAP Dataloader 参数控制缓存目录位置、大小限制和数据获取委托。默认情况下,每个节点只有 TP 等级 0 才能从源中获取数据,而同一数据复制组中的其他节点则从共享缓存中读取数据,从而消除了冗余传输。
MMAPDataModule: 它封装原始数据模块并返回用于训练和验证的 mmap 数据加载器。
请参阅启用 MMAP 的示例
API 参考
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
无检查点训练中缓存恢复内存映射 (MMAP) 数据加载器功能的配置类。 HyperPod
此配置通过缓存和预取功能实现了高效的数据加载,通过在内存映射文件中维护缓存的数据批次,允许在失败后快速恢复训练。
参数
-
cache_dir(str,可选)-用于存储缓存数据批处理的目录路径。默认:“/dev/shm/pdl_cache”
-
prefetch_length(int,可选)-训练期间要提前预取的批次数。默认值:10
-
val_prefetch_length(int,可选)-验证期间要提前预取的批次数。默认值:10
-
lookback_length(int,可选)-要保留在缓存中以备重复使用的先前使用的批次数。默认值:2
-
checkpoint_fre quency(int,可选)— 模型检查点步骤的频率。用于缓存性能优化。默认值:无
-
model_parallel_group(对象,可选)— 模型并行性的处理组。如果为 “无”,则会自动创建。默认值:无
-
enable_batch_ encryption(bool,可选)-是否为缓存的批处理数据启用加密。默认值:False
Methods
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
创建并返回已配置的 MMAP 数据加载器实例。
参数
-
dataloader_init_callable(可调用)— 用于初始化底层数据加载器的函数
-
p@@ arallel_state_util(对象)— 用于管理跨进程并行状态的实用程序
-
ste@@ p (int) — 训练期间要从中恢复的数据步骤
-
is_data_loading_rank(可调用)— 如果当前等级应该加载数据,则返回 True 的函数
-
create_model_parallel_group_callable(可调用)— 用于创建模型并行进程组的函数
-
名称(str,可选)-数据加载器的名称标识符。默认:“火车”
-
is_val(bool,可选)-这是否是验证数据加载器。默认值:False
-
cached_len(int,可选)-如果从现有缓存中恢复,则缓存数据的长度。默认:0
返回CacheResumePrefetchedDataLoader或 CacheResumeReadDataLoader — 已配置的 MMAP 数据加载器实例
ValueError如果 step 参数为,则引发None。
示例
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
备注
-
缓存目录应有足够的空间和快速的 I/O 性能(例如,/dev/shm 用于内存存储)。
-
设置通过将缓存管理与模型检查点对齐来
checkpoint_frequency提高缓存性能 -
对于验证数据加载器 (
is_val=True),该步骤将重置为 0 并强制冷启动 -
根据当前等级是否负责数据加载,使用不同的数据加载器实现
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
一款 PyTorch Lightning DataModule 包装器,可将内存映射 (MMAP) 数据加载功能应用于现有 DataModules 无检查点训练。
该课程封装了现有的 PyTorch Lightning, DataModule 并通过 MMAP 功能对其进行了增强,从而在训练失败期间实现了高效的数据缓存和快速恢复。它保持了与原始 DataModule 界面的兼容性,同时增加了无检查点训练功能。
参数
- data_module (pl. LightningDataModule)
DataModule 要封装的底层(例如 LLMDataModule)
- mmap_config (mmapConfig)
定义缓存行为和参数的 MMAP 配置对象
parallel_state_util(MegatronParallelStateUtil,可选)用于管理分布式进程间的并行状态的实用程序。默认: MegatronParallelStateUtil()
is_data_loading_rank(可调用,可选)如果当前等级应该加载数据,则返回 True 的函数。如果为 “无”,则默认为 parallel_state_util.is_tp_0。默认值:无
属性
global_step(int)当前的全局训练步骤,用于从检查点恢复
cached_train_dl_len(int)训练数据加载器的缓存长度
cached_val_dl_len(int)验证数据加载器的缓存长度
Methods
setup(stage=None)
为指定的训练阶段设置底层数据模块。
stage(str,可选)训练阶段(“适合”、“验证”、“测试” 或 “预测”)。默认值:无
train_dataloader()
使用 MM DataLoader AP 包装创建训练。
返回: DataLoader — DataLoader 使用缓存和预取功能进行 MMAP-wrapped 训练
val_dataloader()
使用 MM DataLoader AP 包装创建验证。
返回: DataLoader — DataLoader 具有缓存功能的 MMAP-wrapped 验证
test_dataloader()
DataLoader 如果底层数据模块支持测试,则创建该测试。
返回: DataLoader 或 None — DataLoader 从底层数据模块进行测试,如果不支持,则返回 None
predict_dataloader()
DataLoader 如果底层数据模块支持预测,则创建预测。
返回: DataLoader 或 None — DataLoader 从底层数据模块进行预测,如果不支持,则返回 None
load_checkpoint(checkpoint)
加载检查点信息以从特定步骤恢复训练。
- 检查点(字典)
包含 “global_step” 键的检查点字典
get_underlying_data_module()
获取底层封装的数据模块。
退货:pl. LightningDataModule — 封装的原始数据模块
state_dict()
获取 DataModule 用于检查点的 MMAP 的状态字典。
返回:dict — 包含缓存数据加载器长度的字典
load_state_dict(state_dict)
加载状态字典以恢复 MMAP DataModule 状态。
state_dict(字典)要加载的州字典
属性
data_sampler
向 NeMo 框架公开底层数据模块的数据采样器。
返回:object 或 None — 来自底层数据模块的数据采样器
示例
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
备注
包装器使用 __getattr__ 将大多数属性访问权限委托给底层数据模块
只有数据加载等级才会真正初始化并使用底层数据模块;其他等级使用虚假的数据加载器
保持缓存的数据加载器长度以优化训练恢复期间的性能