本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
In-process 恢复和无检查点训练
HyperPod 无检查点训练使用模型冗余来实现容错训练。核心原则是,模型和优化器状态在多个节点组之间完全复制,权重更新和优化器状态更改在每个节点组内同步复制。发生故障时,运行正常的副本会完成其优化器步骤,并将更新的 model/optimizer 状态传输到正在恢复的副本。
这种基于模型冗余的方法支持多种故障处理机制:
-
In-process 恢复:尽管出现故障,但进程仍保持活动状态,在 GPU 内存中保留所有模型和优化器状态为最新值
-
优雅的中止处理:受控的中止和受影响操作的资源清理
-
代码块重新执行:仅在代码块 (RCB) 中重新运行受影响的 Re-executable 代码段
-
无检查点恢复,不会丢失训练进度:由于进程持续存在且状态保留在内存中,因此不会丢失任何训练进度;出现故障时,训练从上一步恢复,而不是从上次保存的检查点恢复
无检查点配置
以下是无检查点训练的核心片段。
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: 所有等级都将等待来自 HyperpodTrainingOperator 基础架构的等级信息。HPWrapper: Python 函数封装器,可为 Re-executable 代码块 (RCB) 启用重启功能。该实现使用上下文管理器而不是 Python 装饰器,因为装饰器无法确定运行时要监视的 RCB 的数量。CudaHealthCheck:通过与 GPU 同步,确保当前进程的 CUDA 上下文处于正常状态。使用由 LOCAL_RANK 环境变量指定的设备,如果未设置 LOCAL_RANK,则默认为主线程的 CUDA 设备。HPAgentK8sAPIFactory:此 API 支持无检查点训练,以查询 Kubernetes 训练集群中其他 Pod 的训练状态。它还提供了基础架构级别的屏障,可确保所有队伍在继续操作之前成功完成中止和重启操作。CheckpointManager:管理内存中的检查点和点对点恢复,实现无检查点容错。它有以下核心职责:In-Memory 检查点管理:在内存中保存和管理 NeMo 模型检查点,以便在无检查点恢复场景 I/O 中无需磁盘即可快速恢复。
恢复可行性验证:通过验证全局步骤一致性、等级运行状况和模型状态完整性,确定是否可以进行无检查点恢复。
Peer-to-Peer 恢复编排:使用分布式通信协调健康队伍和失败队列之间的检查点传输,以实现快速恢复。
RNG 状态管理:保留和恢复 Python、、和威震天中的随机数生成器状态 NumPy PyTorch,以实现确定性恢复。
[可选] 检查点卸载:如果 GPU 没有足够的内存容量,则将内存中的检查点卸载到 CPU。
PEFTCheckpointManager: 它CheckpointManager通过保留基本模型权重进行PEFT微调来扩展。CheckpointlessAbortManager:在遇到错误时在后台线程中管理中止操作。默认情况下,它会中止 TransformerEngine、Checkpointing TorchDistributed、和。 DataLoader用户可以根据需要注册自定义中止处理程序。中止完成后,必须停止所有通信,并且必须终止所有进程和线程,以防止资源泄漏。CheckpointlessFinalizeCleanup:在主线程中处理无法在后台线程中安全中止或清理的组件的最终清理操作。CheckpointlessMegatronStrategy: 它继承MegatronStrategy自《尼莫》中的 from。请注意,无检查点训练要求num_distributed_optimizer_instances至少为 2,这样才能进行优化器复制。该策略还负责基本属性注册和进程组初始化,例如 rootless。CheckpointlessCallback: 闪电回调,将 NeMo 训练与无检查点训练的容错系统集成在一起。它有以下核心职责:训练步骤生命周期管理:跟踪训练进度,并根据训练状态(第一步与 ParameterUpdateLock 后续步骤)进行协调以实现 enable/disable 无检查点恢复。
检查点状态协调:管理内存中 PEFT 基础模型检查点。 saving/restoring
CheckpointlessCompatibleConnector: 尝试CheckpointConnector将检查点文件预加载到内存的 PTL,源路径按此优先级确定:尝试无检查点恢复
如果无检查点返回 None,则回退到 parent.resume_start ()
如需向代码
概念
本节介绍无检查点训练概念。Amazon 上的 Checkpoint 无检查点培训 SageMaker HyperPod 支持进程内恢复。此 API 接口采用与 nvRX API 相似的格式。
概念- Re-Executable 代码块 (RCB)
发生故障时,健康的进程会保持活动状态,但必须重新执行部分代码才能恢复训练状态和 python 堆栈。 Re-executable 代码块 (RCB) 是在故障恢复期间重新运行的特定代码段。在以下示例中,RCB 包含整个训练脚本(即 main () 下的所有内容),这意味着每次故障恢复都会重新启动训练脚本,同时保留内存中的模型和优化器状态。
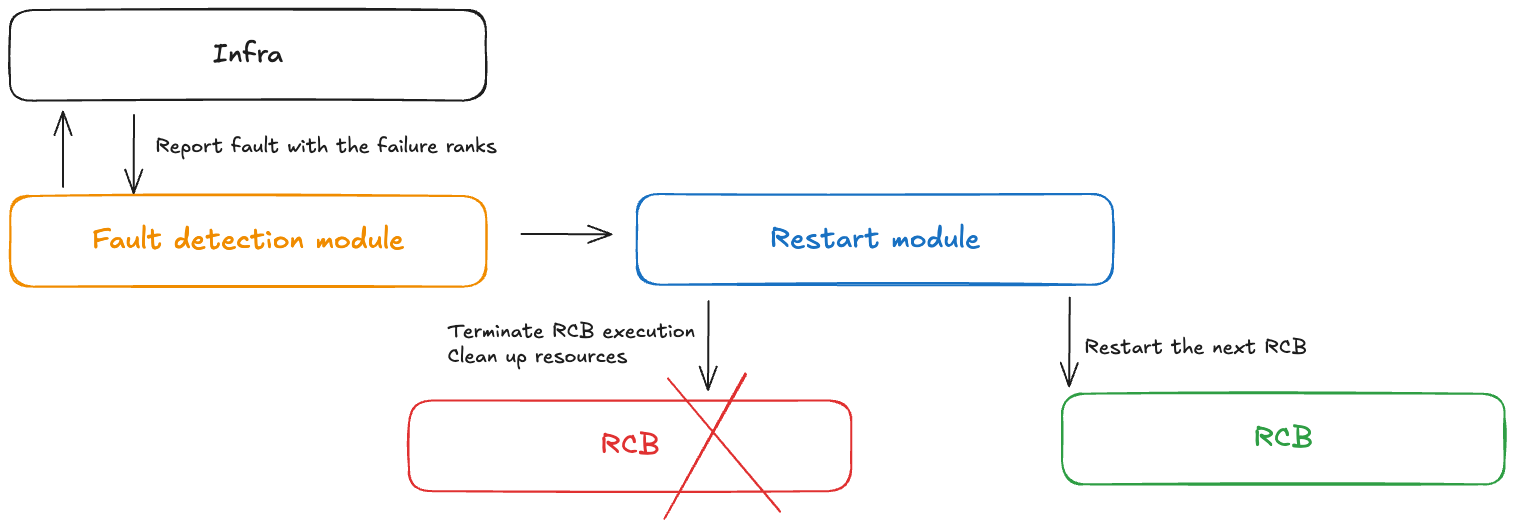
概念-故障控制
在无检查点训练期间发生故障时,故障控制器模块会收到通知。此故障控制器包括以下组件:
故障检测模块:接收基础设施故障通知
RCB 定义 API:使用户能够在其代码中定义可重复执行代码块 (RCB)
重启模块:终止 RCB、清理资源并重新启动 RCB
概念-模型冗余
大型模型训练通常需要足够大的数据并行大小才能有效地训练模型。在 PyTorch DDP 和 Horovod 等传统数据并行模式中,模型是完全复制的。更高级的分片数据并行技术(例如 DeepSpeed ZerO optimizer 和 FSDP)也支持混合分片模式,该模式允许对分片组内的 model/optimizer 状态进行分片并在复制组之间进行完全复制。 NeMo 还通过参数 num_distributed_optimizer_instances 具有这种混合分片功能,该参数允许冗余。
但是,添加冗余表示模型不会在整个集群中完全分片,从而导致更高的设备内存使用率。冗余内存的数量将因用户实现的特定模型分片技术而异。低精度模型权重、梯度和激活存储器不会受到影响,因为它们是通过模型并行度进行分片的。高精度主模型 weights/gradients 和优化器状态将受到影响。添加一个冗余模型副本会增加设备内存使用量,大约相当于一个 DCP 检查点的大小。
混合分片将整个 DP 组的集合分成相对较小的集合。以前,整个 DP 组中都有减少散射和全聚集。混合分片后,reduce-scatter 仅在每个模型副本内运行,并且模型副本组之间将进行全缩减。All-gather 也在每个模型复制品中运行。因此,整个通信量大致保持不变,但是集体的群组规模较小,因此我们预计延迟会更好。
概念-故障和重启类型
下表记录了不同的故障类型和相关的恢复机制。Checkpointless 训练首先尝试通过进程内恢复进行故障恢复,然后进行进程级重启。只有在发生灾难性故障(例如,多个节点同时出现故障)时,它才会回退到作业级别的重启。
| 失败类型 | 原因 | 恢复类型 | 恢复机制 |
|---|---|---|---|
| In-process 失败 | Code-level 错误、异常 | In-Process 恢复 (IPR) | 在现有流程中重新运行 RCB;健康的流程保持活跃 |
| 进程重启失败 | CUDA 上下文已损坏,进程已终止 | 进程级重启 (PLR) | SageMaker HyperPod 训练操作员重新启动进程;跳过 K8s pod 的重启 |
| 节点替换失败 | 永久性 node/GPU 硬件故障 | Job 等级重启 (JLR) | 替换故障节点;重新启动整个训练作业 |
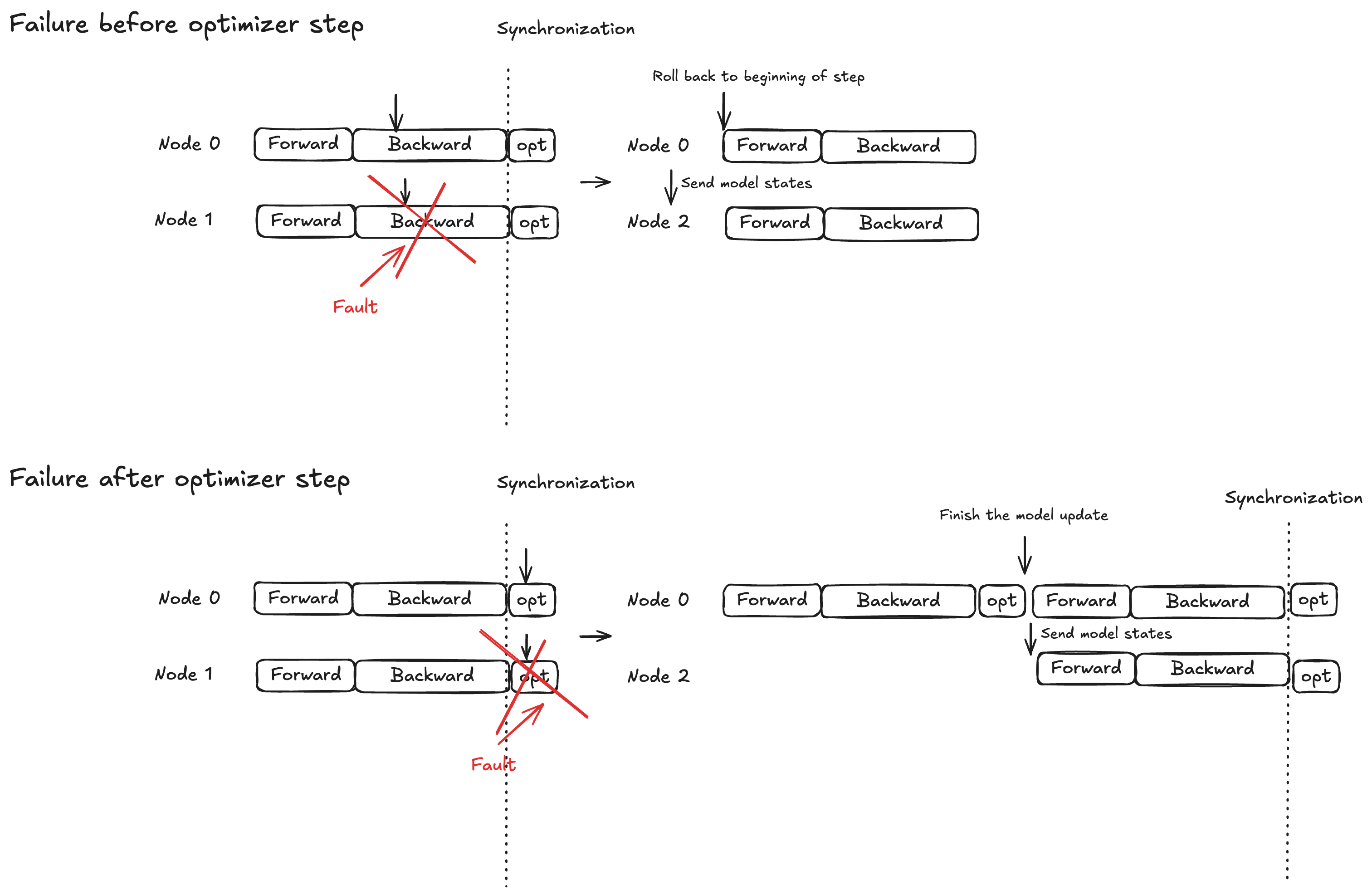
概念-优化器步骤的原子锁保护
模型执行分为三个阶段:向前传播、向后传播和优化器步骤。恢复行为因故障时间而异:
Forward/backward 传播:回滚到当前训练步骤的开头,将模型状态广播到替换节点
Optimizer 步骤:允许运行良好的副本在锁定保护下完成该步骤,然后向替换节点广播更新的模型状态
此策略可确保已完成的优化器更新永远不会被丢弃,从而有助于缩短故障恢复时间。
无检查点训练流程图
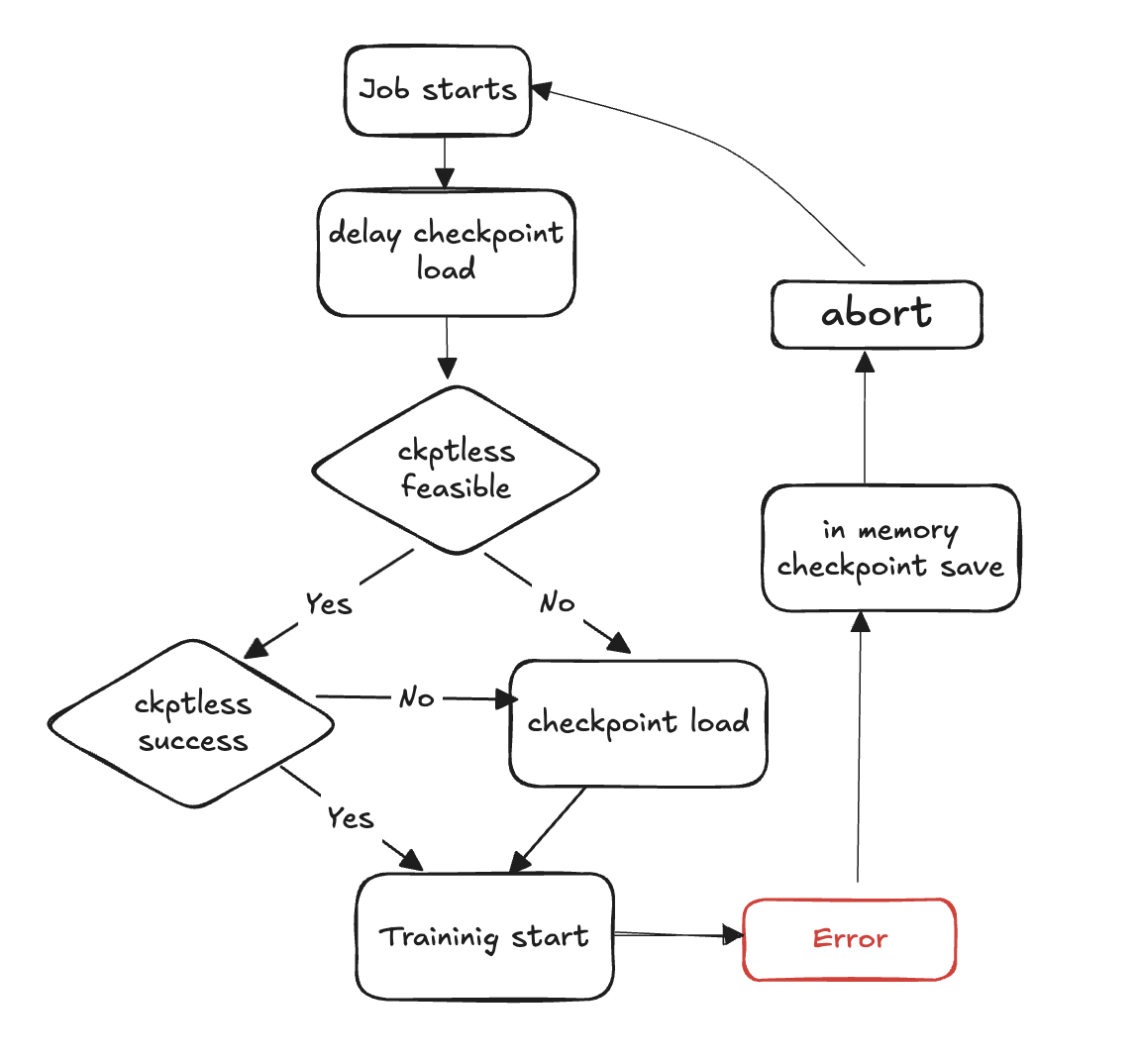
以下步骤概述了故障检测和无检查点恢复过程:
训练循环开始
出现故障
评估无检查点简历的可行性
检查无检查点简历是否可行
如果可行,尝试无检查点恢复
如果恢复失败,则回退到从存储中加载检查点
如果恢复成功,则从恢复状态继续训练
如果不可行,则回退到从存储中加载检查点
清理资源-中止所有进程组和后端并释放资源,为重启做准备。
恢复训练循环-新的训练循环开始,该过程返回到步骤 1。
API 参考
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
等待并从中检索排名信息 HyperPod,然后使用分布式训练变量更新当前流程环境。
此函数为分布式训练获取正确的等级分配和环境变量。它可以确保每个进程都根据其在分布式训练作业中的角色进行适当的配置。
参数
无
返回值
无
行为
进程检查:如果从子进程调用,则跳过执行(仅在中运行) MainProcess
环境检索:从环境变量获取当前
RANK和WORLD_SIZE从环境变量中获取HyperPod 沟通:
hyperpod_wait_rank_info()要求从中检索排名信息的电话 HyperPod环境更新:使用从中收到的特定于工作人员的环境变量更新当前流程环境 HyperPod
环境变量
该函数读取以下环境变量:
RANK (int)-当前进程等级(如果未设置,则默认值:-1)
WORLD_SIZ E (int)-分布式作业中的进程总数(如果未设置,则默认值:0)
加注
AssertionError— 如果来自的回复格式 HyperPod 不符合预期,或者缺少必填字段
示例
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
备注
仅在主进程中执行;子进程调用会自动跳过
该函数会阻塞,直到 HyperPod 提供等级信息
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Python 函数封装器,可在无 HyperPod 检查点训练中为 Re-executable 代码块 (RCB) 启用重启功能。
该封装器通过监控训练执行并在发生故障时协调分布式进程的重启来提供容错和自动恢复功能。它使用上下文管理器方法而不是装饰器来维护整个培训生命周期中的全球资源。
参数
abort(中止,可选)— 检测到故障时异步中止执行。默认值:
Compose(HPAbortTorchDistributed())final i ze(Finalize,可选 Rank-local )— 在重新启动期间执行的最终处理程序 默认值:
Nonehealth_check(HealthCheck可选)— 在重启期间执行的运行 Rank-local 状况检查。默认值:
Nonehp_api_fac tory(可调用,可选)— 用于创建要与之交互的 API 的工厂函数。 HyperPod HyperPod默认值:
Noneabort_timeou t(float,可选)— 故障控制线程中中止调用的超时。默认值:
None启用(bool,可选)-启用包装器功能。当
False,包装器变为直通。默认值:Truetrace_file_path(str,可选)— 用于分析的跟踪文件的路径。 VizTracer 默认值:
Noneasync_raise_before_abort(bool,可选)— 在故障控制线程中启用中止前加注。默认值:
Truee@@ arly_abort_communicator(bool,可选)— 在中止数据加载器之前中止通信器 ()。NCCL/Gloo默认值:
Falsecheckpoint_manager(任意,可选)— 用于在恢复期间处理检查点的管理器。默认值:
Nonecheck_memory_stat us(bool,可选)— 启用内存状态检查和日志记录。默认值:
True
Methods
def __call__(self, fn)
封装启用重启功能的函数。
参数:
fn(可调用)— 使用重启功能进行封装的函数
退货:
Callable — 具有重启功能的封装函数,如果禁用则为原始函数
示例
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
备注
包装器必须
torch.distributed可用当
enabled=False,包装器变为直通函数并原封不动地返回原始函数包装器维护全局资源,例如在整个训练生命周期中监控线程
支持在提供时 VizTracer
trace_file_path进行性能分析与集成 HyperPod ,可在分布式训练中协调故障处理
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
在执行期间监控和管理重启代码块 (RCB) 的状态。
该类处理 RCB 执行的生命周期,包括故障检测、与其他级别的协调以进行重启以及清理操作。它管理分布式同步,并确保在所有训练过程中实现一致的恢复。
参数
包装器 (HPWrapper) — 包含全局进程内恢复设置的父封装器
属性
step_upon_restar t (int) — 用于跟踪自上次重启以来的步骤的计数器,用于确定重启策略
Methods
def initialize_barrier()
遇到 RCB 异常后等待 HyperPod 屏障同步。
def start_hp_fault_handling_thread()
启动故障处理线程以监控和协调故障。
def handle_fn_exception(call_ex)
处理来自执行函数或 RCB 的异常。
参数:
call_ex(异常)-监控功能异常
def restart(term_ex)
执行重启处理程序,包括完成、垃圾收集和运行状况检查。
参数:
term_ex (RankShouldRestart)-触发重启的终止异常
def launch(fn, *a, **kw)
使用适当的异常处理来执行 RCB。
参数:
fn(可调用)— 要执行的函数
a-函数参数
kw — 函数关键字参数
def run(fn, a, kw)
处理重启和屏障同步的主执行循环。
参数:
fn(可调用)— 要执行的函数
a-函数参数
kw — 函数关键字参数
def shutdown()
关闭故障处理和监控线程。
备注
自动处理
RankShouldRestart异常以进行协调恢复管理内存跟踪和中止、重启期间的垃圾收集
支持进程内恢复和基于故障时机的 PLR(Process-Level 重启)策略
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
确保在无检查点训练恢复期间,当前进程的 CUDA 上下文处于健康状态。
此运行状况检查与 GPU 同步,以验证训练失败后 CUDA 上下文是否未损坏。它执行 GPU 同步操作以检测任何可能阻碍成功恢复训练的问题。运行状况检查是在分布式群组被销毁并完成定稿后执行的。
参数
超时(datetime.timedelta,可选)-GPU 同步操作的超时持续时间。默认值:
datetime.timedelta(seconds=30)
Methods
__call__(state, train_ex=None)
执行 CUDA 运行状况检查以验证 GPU 上下文的完整性。
参数:
状态 (hpStat e) — 包含等级和分布信息的当前 HyperPod 状态
train_ex(异常,可选)-触发重启的原始训练异常。默认值:
None
退货:
tuple — 如果运行状况检查通过,则包含
(state, train_ex)未更改内容的元组
加注:
TimeoutError— 如果 GPU 同步超时,则表示 CUDA 上下文可能已损坏
状态保存:如果所有检查都通过,则返回原始状态和异常不变
示例
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
备注
使用线程实现 GPU 同步的超时保护
旨在检测可能阻碍成功恢复训练的损坏的 CUDA 上下文
应在分布式训练场景中用作容错管道的一部分
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
用于创建与 HyperPod 基础设施通信以进行分布式训练协调的 hpagentk8sAPI 实例的工厂类。
该工厂提供了一种标准化的方法来创建和配置 Hpagentk8sAPI 对象,这些对象用于处理训练过程与控制平面之间的通信。 HyperPod 它封装了底层套接字客户端和 API 实例的创建,确保了训练系统的不同部分的配置保持一致。
Methods
__call__()
创建并返回一个为通信配置的 hpagentk8sAPI 实例。 HyperPod
退货:
hpagentk8sAPI — 用于与基础设施通信的已配置 API 实例 HyperPod
示例
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
备注
旨在与 HyperPod Kubernetes-based 的基础架构无缝协作。在分布式训练场景中,这对于协调故障处理和恢复至关重要
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
管理内存中的检查点和点对点恢复,以实现分布式训练中的无检查点容错。
该课程通过管理内存中的 NeMo 模型 HyperPod 检查点、验证恢复可行性以及协调健康和失败等级之间的点对点检查点传输,为无检查点训练提供了核心功能。它消除了恢复 I/O 期间对磁盘的需求,从而大大缩短了平均恢复时间 (MTTR)。
参数
enable_checksum(bool,可选)— 启用模型状态校验和验证,以便在恢复期间进行完整性检查。默认值:
Falseenable_offload(bool,可选)— 启用从 GPU 到 CPU 内存的检查点卸载以减少 GPU 内存使用量。默认值:
False
属性
global_step(int 或 None)— 与保存的检查点关联的当前训练步骤
rng_states(列表或无)— 存储的随机数生成器状态用于确定性恢复
checksum_manager (MemoryChecksumManager) — 模型状态校验和验证管理器
p@@ arameter_update_lock (ParameterUpdateLock) — 用于在恢复期间协调参数更新的锁定
Methods
save_checkpoint(trainer)
将 NeMo 模型检查点保存在内存中,以便进行可能的无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
备注:
CheckpointlessCallback 在批处理结束时或异常处理期间由调用
无需磁盘 I/O 开销即可创建恢复点
存储完整的模型、优化器和调度器状态
delete_checkpoint()
删除内存中的检查点并执行清理操作。
备注:
清除检查点数据、RNG 状态和缓存的张量
执行垃圾收集和 CUDA 缓存清理
成功恢复后或不再需要检查点时调用
try_checkpointless_load(trainer)
尝试通过从对等队列加载状态来进行无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
退货:
dict 或 None — 如果成功则恢复检查点,如果需要回退到磁盘,则为 None
备注:
无检查点恢复的主要切入点
在尝试 P2P 传输之前验证恢复的可行性
尝试恢复后始终清理内存中的检查点
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
确定在当前的故障情况下是否可以进行无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
inclu@@ de_checksum_verificati on(bool,可选)— 是否包括校验和验证。默认值:
True
退货:
bool — 如果无检查点恢复可行,则为 True,否则为 False
验证标准:
健康等级的全球步数一致性
有足够的健康副本可供恢复
模型状态校验和完整性(如果启用)
store_rng_states()
存储所有随机数生成器状态以进行确定性恢复。
备注:
捕获 Python NumPy、 PyTorch CPU/GPU、和威震天 RNG 状态
对于恢复后保持训练决定性至关重要
load_rng_states()
恢复所有 RNG 状态,以便继续进行确定性恢复。
备注:
恢复之前存储的所有 RNG 状态
确保使用相同的随机序列继续训练
maybe_offload_checkpoint()
如果启用了卸载,则将检查点从 GPU 卸载到 CPU 内存。
备注:
减少大型模型的 GPU 内存使用量
只有在以下情况下才会执行
enable_offload=True保持检查点可访问性,便于恢复
示例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
验证:使用校验和验证检查点完整性(如果启用)
备注
使用分布式通信基元实现高效的 P2P 传输
自动处理张量 dtype 转换和设备放置
MemoryChecksumManager— 处理模型状态完整性验证
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
使用单独的基础和适配器处理来管理 PEFT (Parameter-Efficient Fine-Tuning) 的检查点,以优化无检查点恢复。
这个专门的检查点管理器扩展 CheckpointManager 到通过将基本模型权重与适配器参数分开来优化 PEFT 工作流程。
参数
继承以下所有参数:CheckpointManager
enable_checksum(bool,可选)— 启用模型状态校验和验证。默认值:
Falseenable_offload(bool,可选)— 启用将检查点卸载到 CPU 内存。默认值:
False
其他属性
p@@ arams_to_save (s et)-应另存为适配器参数的一组参数名称
base_model_weig hts(dict 或 None)— 缓存的基础模型权重,保存一次即可重复使用
base_model_keys_to_extrac t(列表或无)— 用于在 P2P 传输期间提取基础模型张量的密钥
Methods
maybe_save_base_model(trainer)
保存一次基本模型权重,过滤掉适配器参数。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
备注:
仅在第一次调用时保存基础模型权重;后续调用无效
过滤掉适配器参数以仅存储冻结的基本模型权重
基础模型权重在多次训练中保持不变
save_checkpoint(trainer)
将 NeMo PEFT 适配器型号检查点保存在内存中,以便进行无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
备注:
maybe_save_base_model()如果基础模型尚未保存,则自动调用筛选检查点以仅包括适配器参数和训练状态
与完整模型检查点相比,显著减少了检查点的大小
try_base_model_checkpointless_load(trainer)
尝试 PEFT 基础模型通过从对等队列加载状态来权重无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
退货:
dict or None — 如果成功则恢复基本模型检查点,如果需要回退,则为 None
备注:
在模型初始化期间用于恢复基础模型权重
恢复后不清理基础模型权重(保留以供重复使用)
针对仅限模型权重的恢复场景进行了优化
try_checkpointless_load(trainer)
尝试 PEFT 适配器通过从对等队列加载状态来权重无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
退货:
dict 或 None — 如果成功则恢复适配器检查点,如果需要回退,则为 None
备注:
仅恢复适配器参数、优化器状态和调度程序
成功恢复后自动加载优化器和调度器状态
尝试恢复后清理适配器检查点
is_adapter_key(key)
检查状态字典密钥是否属于适配器参数。
参数:
key(str 或元组)— 要检查的状态字典密钥
退货:
bool — 如果密钥是适配器参数,则为 True,如果为基本模型参数,则为 Fals
检测逻辑:
检查密钥是否已
params_to_save设置识别包含 “.adapter” 的密钥。substring
识别以 “.adapters” 结尾的密钥
对于元组键,检查参数是否需要渐变
maybe_offload_checkpoint()
将基本模型权重从 GPU 转移到 CPU 内存。
备注:
扩展父方法以处理基础模型的权重卸载
适配器重量通常很小,不需要卸载
设置内部标志以跟踪卸载状态
备注
专为 Parameter-Efficient Fine-Tuning 场景(LoRa、适配器等)而设计
自动处理基本模型和适配器参数的分离
示例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
工厂类,用于创建和管理中止组件组合以实现无检查点容错。
该实用程序类提供了用于创建、自定义和管理无 HyperPod 检查点训练中错误处理期间使用的中止组件组合的静态方法。它简化了中止序列的配置,这些序列在故障恢复期间处理分布式训练组件、数据加载器和特定于框架的资源的清理。
参数
无(所有方法都是静态的)
静态方法
get_default_checkpointless_abort()
获取包含所有标准中止组件的默认中止撰写实例。
退货:
Compose — 包含所有中止组件的默认合成中止实例
默认组件:
AbortTransformerEngine() — 清理资源 TransformerEngine
HPCheckpointingAbort() — 处理检查点系统清理
HPAbortTorchDistributed()-中止 PyTorch 分布式操作
HPDataLoaderAbort() — 停止并清理数据加载器
create_custom_abort(abort_instances)
创建仅包含指定中止实例的自定义中止组合。
参数:
abor@@ t_inst ances (Abort) — 要包含在撰写中的中止实例数量可变
退货:
Compose-仅包含指定组件的新合成的中止实例
加注:
ValueError— 如果未提供中止实例
override_abort(abort_compose, abort_type, new_abort)
将 Compose 实例中的特定中止组件替换为新组件。
参数:
abort_compose (C ompose) — 要修改的原始 Compose 实例
abort_typ e (type) — 要替换的中止组件的类型(例如)
HPCheckpointingAbortnew_abort (Abort) — 用作替换的新中止实例
退货:
Compose — 替换了指定组件的新 Compose 实例
加注:
ValueError— 如果 abort_compose 没有 “实例” 属性
示例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
备注
自定义配置允许对清理行为进行微调控制
中止操作对于在故障恢复期间正确清理资源至关重要
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
在故障检测后进行全面清理,为无检查点训练期间的进程内恢复做好准备。
此 finalize 处理程序通过销毁训练组件引用来执行特定于框架的清理操作,包括 Megatron/TransformerEngine 中止、DDP 清理、模块重新加载和内存清理。它可以确保正确重置训练环境,以便成功进行进程内恢复,而无需终止整个进程。
参数
无
属性
训练师(pytorch_Lightning.Trainer 或 N one)— 参考闪电训练器实例 PyTorch
Methods
__call__(*a, **kw)
执行全面的清理操作,为进程中的恢复做好准备。
参数:
a — 可变位置参数(继承自 Finalize 接口)
kw — 可变关键字参数(继承自 Finalize 接口)
清理操作:
威震天框架清理 — 呼吁清理
abort_megatron()资源 Megatron-specificTransformerEngine 清理 — 呼叫
abort_te()清理资源 TransformerEngineR@@ ope Cleanup —
cleanup_rope()呼吁清理旋转位置嵌入资源DDP 清理 — 呼叫清
cleanup_ddp()理资源 DistributedDataParallel模块重新加载 — 调用
reload_megatron_and_te()重新加载框架模块闪电模块清理 — 可选择清除闪电模块以减少 GPU 内存
内存清理-销毁对空闲内存的训练组件引用
register_attributes(trainer)
注册训练器实例,以便在清理操作期间使用。
参数:
训练师 (pytorch_Lightning.Trainer) — 要注册的 Lightning 训练师实例 PyTorch
与集成 CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
备注
清理操作按特定顺序执行,以避免依赖性问题
内存清理使用垃圾收集内省来查找目标对象
所有清理操作都设计为均等且可安全重试
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo 威震天策略具有集成的无检查点恢复功能,用于容错分布式训练。
请注意,无检查点训练要求num_distributed_optimizer_instances至少为 2,这样才能进行优化器复制。该策略还负责基本属性注册和流程组初始化。
参数
继承以下所有参数:MegatronStrategy
标准 NeMo MegatronStrategy 初始化参数
分布式训练配置选项
模型并行度设置
属性
base_store(t orch.distributed.tcpStore 或 None)— 用于协调流程组的分布式存储
Methods
setup(trainer)
初始化策略并向训练器注册容错组件。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
设置操作:
家长设置-调用家长 MegatronStrategy 设置
故障注入登记 — 注册 HPFaultInjectionCallback 挂钩(如果存在)
完成注册 — 向最终清理处理人员注册培训师
中止注册 — 向支持它的中止处理程序注册训练器
setup_distributed()
使用带前缀的 TcpStore 或无根连接初始化进程组。
load_model_state_dict(checkpoint, strict=True)
加载具有无检查点恢复兼容性的模型状态字典。
参数:
检查点(映射 [str,Any])-包含模型状态的检查点字典
st rict(bool,可选)— 是否严格强制执行状态字典键匹配。默认值:
True
get_wrapper()
获取容错协调 HPCallWrapper 实例。
退货:
HPCallWrapper— 为了容错而附加到训练器上的包装器实例
is_peft()
通过检查 PEFT 回调,检查训练配置中是否启用了 PEFT (Parameter-Efficient Fine-Tuning)
退货:
bool — 如果存在 PEFT 回调则为真,否则为假
teardown()
覆盖 PyTorch Lightning 原生拆解,将清理委托给中止处理程序。
示例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
闪电回调,将 NeMo 训练与无检查点训练的容错系统集成在一起。
此回调管理步数跟踪、检查点保存和参数更新协调,以实现进程内恢复功能。它是 L PyTorch ightning 训练循环和 HyperPod 无检查点训练机制之间的主要集成点,在整个训练生命周期中协调容错操作。
参数
enable_inprocess(bool,可选)-启用进程内恢复功能。默认值:
Falseenable_checkpointles s(bool,可选)— 启用无检查点恢复(需要)。
enable_inprocess=True默认值:Falseenable_checksum(bool,可选)— 启用模型状态校验和验证(必需)。
enable_checkpointless=True默认值:Falseclean_tensor_hook(bool,可选)— 在清理期间清除所有 GPU 张量中的张量挂钩(昂贵的操作)。默认值:
Falseclean_lightning_module(bool,可选)— 启用闪电模块清理以在每次重启后释放 GPU 内存。默认值:
False
属性
tried_adapter_checkpointless (bool) — 用于跟踪是否尝试过适配器无检查点还原的标记
Methods
get_wrapper_from_trainer(trainer)
从培训师那里获取容错协调 HPCallWrapper 实例。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
退货:
HPCallWrapper— 容错操作的包装器实例
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
在每个训练批次开始时调用,以管理步数跟踪和恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
pl_module(pytorch_li ghtning LightningModule) — 正在训练闪电模块
batch-当前训练批次数据
batch_idx (int) — 当前批次的索引
args — 其他位置参数
kwargs — 其他关键字参数
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
在每个训练批次结束时释放参数更新锁。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
pl_module(pytorch_li ghtning LightningModule) — 正在训练闪电模块
输出(STEP_OUTPUT)— 训练步骤输出
batch(任意)-当前训练批次数据
batch_idx (int) — 当前批次的索引
备注:
锁定释放时间可确保参数更新完成后可以继续进行无检查点恢复
仅当
enable_inprocess和均enable_checkpointless为 True 时才执行
get_peft_callback(trainer)
从培训师的回拨列表中检索 PEFT 回调。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
退货:
PEFT 或无 — 如果找到 PEFT 回调实例,否则为 None
_try_adapter_checkpointless_restore(trainer, params_to_save)
尝试对 PEFT 适配器参数进行无检查点恢复。
参数:
训练师 (pytorch_Lightning.Trainer) — 闪电训练器实例 PyTorch
p@@ arams_to_save (s et)-要另存为适配器参数的参数名称集
备注:
每次训练只执行一次(由
tried_adapter_checkpointless旗帜控制)使用适配器参数信息配置检查点管理器
示例
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
内存管理
clean_tensor_hook:在清理过程中移除张量挂钩(昂贵但彻底)
clean_lightning_module:在重启期间释放闪电模块 GPU 内存
这两个选项都有助于减少故障恢复期间的内存占用
与协调 ParameterUpdateLock 以实现线程安全的参数更新跟踪
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Lightning Checkpoint 连接器,将无检查点恢复与传统的基于磁盘的检查点加载集成在一起。
该连接器扩展了 PyTorch Lightning_CheckpointConnector,提供了无检查点恢复和标准检查点恢复之间的无缝集成。它首先尝试无检查点恢复,然后在无检查点恢复不可行或失败时回退到基于磁盘的检查点加载。
参数
从 _ 继承所有参数 CheckpointConnector
Methods
resume_start(checkpoint_path=None)
尝试预加载具有无检查点恢复优先级的检查点。
参数:
checkpoint_path(str 或 None,可选)— 用于回退的磁盘检查点的路径。默认值:
None
resume_end()
完成检查点加载过程并执行加载后操作。
备注
通过无检查点恢复支持扩展了 L PyTorch ightning 的内部职
_CheckpointConnector业保持与标准 PyTorch 闪电检查点工作流程的完全兼容性
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
使用延 NeMo迟设置 AutoResume 进行扩展,以便在解析检查点路径之前启用无检查点恢复验证。
该类实现了两阶段初始化策略,允许在回退到传统的基于磁盘的检查点加载之前进行无检查点恢复验证。它会有条件地延迟 AutoResume 设置以防止过早解析检查点路径,从而使 CheckpointManager 能够首先验证无检查点的点对点恢复是否可行。
参数
继承所有参数 AutoResume
Methods
setup(trainer, model=None, force_setup=False)
有条件地延迟 AutoResume 设置以启用无检查点恢复验证。
参数:
训练器(pytorch_Lightning.Trainer 或 Lightning.fabric.Fabric)— Lightningtning. PyTorch
模型(可选)-用于设置的模型实例。默认值:
Noneforce_setup(bool,可选)— 如果为 True,则绕过延迟并立即执行 AutoResume 安装程序。默认值:
False
示例
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
备注
扩展 NeMo了带有延迟机制的 AutoResume 类,用于实现无检查点恢复
与之配合使用
CheckpointlessCompatibleConnector以实现完整的恢复工作流程