本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon 中使用弹性训练 SageMaker HyperPod
弹性训练是 Amazon 的一项新 SageMaker HyperPod 功能,可根据计算资源可用性和工作负载优先级自动扩展训练作业。弹性训练作业可以从模型训练所需的最少计算资源开始,然后通过自动检查点和跨不同节点配置(世界大小)的恢复,动态向上或向下扩展。扩展是通过自动调整数据并行副本的数量来实现的。在集群利用率高期间,可以将弹性训练作业配置为自动缩小规模,以响应优先级较高的作业的资源请求,从而腾出计算空间来处理关键工作负载。当资源在非高峰时段释放出来时,弹性训练作业会自动缩减以加快训练速度,然后在优先级较高的工作负载再次需要资源时缩小规模。
Elastic 训练建立在 HyperPod 训练操作员的基础上,并集成了以下组件:
-
PyTorch 用于可扩展状态和@@ 检查点管理的分布式检查点 (DCP)
,例如 DCP
支持的框架
-
PyTorch 使用分布式数据并行 (DDP) 和完全分片数据并行 (FSDP)
-
PyTorch 分布式检查点 (DCP)
先决条件
SageMaker HyperPod EKS 集群
您必须拥有一个使用 Amazon EKS 编排功能的正在运行的 SageMaker HyperPod 集群。有关创建 HyperPod EKS 集群的信息,请参阅:
SageMaker HyperPod 培训操作员
训练操作员 v.1.2 及更高版本支持弹性训练。
要将培训操作员安装为 EKS 附加组件,请参阅:https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(推荐)安装和配置任务治理和 Kueue
我们建议通过HyperPod 任务管理安装和配置 Kueue,以便通过弹性训练指定工作负载优先级。Kueue 通过排队、优先级划分、帮派调度、资源跟踪和优雅的抢占来提供更强的工作负载管理,这些对于在多租户训练环境中运行至关重要。
-
帮派调度可确保训练作业中所有必需的 pod 一起开始。这样可以防止某些 pod 启动而其他的 pod 处于待处理状态,这可能会导致资源浪费。
-
温和的抢占允许优先级较低的弹性作业将资源提供给优先级较高的工作负载。弹性作业可以在不被强制驱逐的情况下优雅地缩小规模,从而提高集群的整体稳定性。
我们建议配置以下 Kueue 组件:
-
PriorityClasses 定义相对的工作重要性
-
ClusterQueues 管理跨团队或工作负载的全球资源共享和配额
-
LocalQueues 将任务从单个命名空间路由到相应的 ClusterQueue
要进行更高级的设置,您还可以合并:
-
Fair-share 平衡多个团队资源使用情况的政策
-
自定义抢占规则以强制执行组织 SLA 或成本控制
请参阅:
(推荐)设置用户命名空间和资源配额
在 Amazon EKS 上部署此功能时,我们建议应用一组基本的群集级配置,以确保各团队之间的隔离、资源公平性和操作一致性。
命名空间和访问配置
为每个团队或项目使用单独的命名空间来组织工作负载。这使您可以应用精细的隔离和治理。我们还建议配置 Amazon IAM 到 Kubernetes 的 RBAC 映射,以将单个 IAM 用户或角色与其相应的命名空间关联起来。
主要做法包括:
-
当工作负载需要权限时,使用服务账户的 IAM 角色 (IRSA) 将 IAM 角色映射到 Kubernetes 服务账户。 Amazon https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
应用 RBAC 策略将用户限制为仅使用其指定的命名空间(例如,
Role/RoleBinding而不是集群范围的权限)。
资源和计算限制
为防止资源争用并确保团队间的公平安排,请在命名空间级别应用配额和限制:
-
ResourceQuotas 上限 CPU、内存、存储和对象总数(Pod、PVC、服务等)。
-
LimitRanges 强制执行每个 Pod 或每个容器的 CPU 和内存的默认和最大限制。
-
PodDisruptionBudgets (PDB)(视需要定义弹性预期)。
-
可选: Namespace-level 队列限制(例如,通过任务管理或 Kueue),以防止用户过度提交作业。
这些限制有助于维护集群的稳定性,并支持分布式训练工作负载的可预测调度。
Auto-scaling
SageMaker HyperPod 在 EKS 上支持通过 Karpenter 进行集群自动扩展。当 Karpenter 或类似的资源配置器与弹性训练一起使用时,在弹性训练作业提交后,集群和弹性训练作业可能会自动扩展。这是因为弹性训练操作员采取贪婪的方法,要求的总是超过可用的计算资源,直到达到作业设定的最大限制。之所以发生这种情况,是因为弹性训练操作员在弹性作业执行过程中不断请求额外资源,这可能会触发节点配置。像 Karpenter 这样的持续资源供应器将通过扩展计算集群来满足请求。
为了保持这些扩展的可预测性和可控性,我们建议在创建弹性训练作业的命名空间 ResourceQuotas 中配置命名空间级别。 ResourceQuotas 帮助限制作业可以请求的最大资源,防止集群无限增长,同时仍允许在定义的限制内弹性行为。
例如,a ResourceQuota for 8 ml.p5.48xlarge 实例将采用以下形式:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
构建训练容器
HyperPod 训练操作员使用通过 HyperPod Elastic Agent package (https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun命令替换hyperpodrun为才能启动培训。欲了解更多详情,请参阅:
训练容器示例:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
修改训练代码
SageMaker HyperPod 提供了一组已配置为使用 Elastic Policy 运行的配方。
要为自定义 PyTorch 训练脚本启用弹性训练,您需要对训练循环进行细微的修改。本指南将引导您完成必要的修改,以确保您的训练作业对计算资源可用性变化时发生的弹性扩展事件做出响应。在所有弹性事件(例如,节点可用或节点被抢占)期间,训练作业都会收到一个弹性事件信号,该信号用于通过保存检查点来协调正常关闭,并通过使用新的世界配置从保存的检查点重新启动来恢复训练。要使用自定义训练脚本启用弹性训练,您需要:
检测弹性扩展事件
在训练循环中,检查每次迭代期间的弹性事件:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
实现检查点保存和检查点加载
注意:我们建议使用 PyTorch 分布式检查点 (DCP) 来保存模型和优化器状态,因为 DCP 支持从具有不同世界大小的检查点恢复。其他检查点格式可能不支持在不同的世界大小上加载检查点,在这种情况下,您需要实现自定义逻辑来处理动态世界大小的变化。
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(可选)使用有状态的数据加载器
如果您只针对单一时期(即一次遍历整个数据集)进行训练,则模型必须只看到每个数据样本一次。如果训练作业在纪元中期停止并以不同的世界大小恢复,则如果数据加载器状态未保持不变,则将重复之前处理的数据样本。有状态的数据加载器通过保存和恢复数据加载器的位置来防止这种情况,确保恢复的运行从弹性缩放事件中继续,而无需重新处理任何样本。我们建议使用 StatefulDataLoaderstate_dict()和load_state_dict()方法的直接替代品)torch.utils.data.DataLoader,启用数据加载过程的中期检查点。
提交弹性训练作业
HyperPod 训练操作员定义了一种新的资源类型-hyperpodpytorchjob。Elastic 训练扩展了这种资源类型,并在下面添加了突出显示的字段:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
使用 kubectl
随后,您可以使用以下命令启动弹性训练。
kubectl apply -f elastic-training-job.yaml
使用 SageMaker 食谱
弹性训练作业可以通过SageMaker HyperPod 配方
注意
我们在 Hyperpod Recipe 上收录了 46 个 SFO 和 DPO 任务的弹性配方。用户可以在现有的静态启动器脚本的基础上更改一行来启动这些作业:
++recipes.elastic_policy.is_elastic=true
除了静态配方外,弹性配方还添加了以下字段来定义弹性行为:
弹性策略
该elastic_policy字段定义弹性训练作业的作业级别配置,它具有以下配置:
-
is_elastic:bool-如果此作业是弹性作业 -
min_nodes:int-用于弹性训练的最小节点数 -
max_nodes:int-用于弹性训练的最大节点数 -
replica_increment_step:int-增加固定大小的组中的 pod 数量,这个字段与scale_config我们稍后定义的字段是相互排斥的。 -
use_graceful_shutdown:bool-如果在缩放事件期间使用优雅关机,则默认为。true -
scaling_timeout:int-超时之前缩放事件期间的等待时间(以秒为单位) -
graceful_shutdown_timeout:int-等待优雅关机的时间
以下是该字段的示例定义,你也可以在配方中的 Hyperpod Recipe 存储库中找到:recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
缩放 Config
该scale_config字段定义了每种特定规模的重写配置。它是一个键值字典,其中 key 是表示目标比例的整数,值是基本配方的子集。在<key>规模上,我们使用<value>来更新 base/static 配方中的特定配置。以下是该字段的示例:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
上述配置定义了等级 2 和 3 的训练配置。在这两种情况下,我们都使用学习率4e-4,批量大小为128。但是在规模 2 中,我们使用 8 的 amicro_train_batch_size,而比例 3,我们使用不均匀的批次大小,因为列车批次大小无法平均分配到 3 个节点。
批量大小不均匀
此字段用于定义在无法将全局批量大小平均除以等级数时批量分配行为。它不是弹性训练所特有的,但它可以实现更精细的缩放粒度。
-
use_uneven_batch:bool-如果使用不均匀的批次分配 -
num_dp_groups_with_small_batch_size:int-在不均匀的批次分布中,有些等级使用较小的本地批次大小,而其他等级使用较大的批次大小。全局批量大小应等于small_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int-此值是较小的本地批次大小 -
large_local_batch_size:int-此值是较大的本地批次大小
在 mlFlow 上监控训练
Hyperpod 配方任务通过 mlFlow 支持可观察性。用户可以在配方中指定 mlFlow 配置:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
这些配置映射到相应的 mlFlow 设置
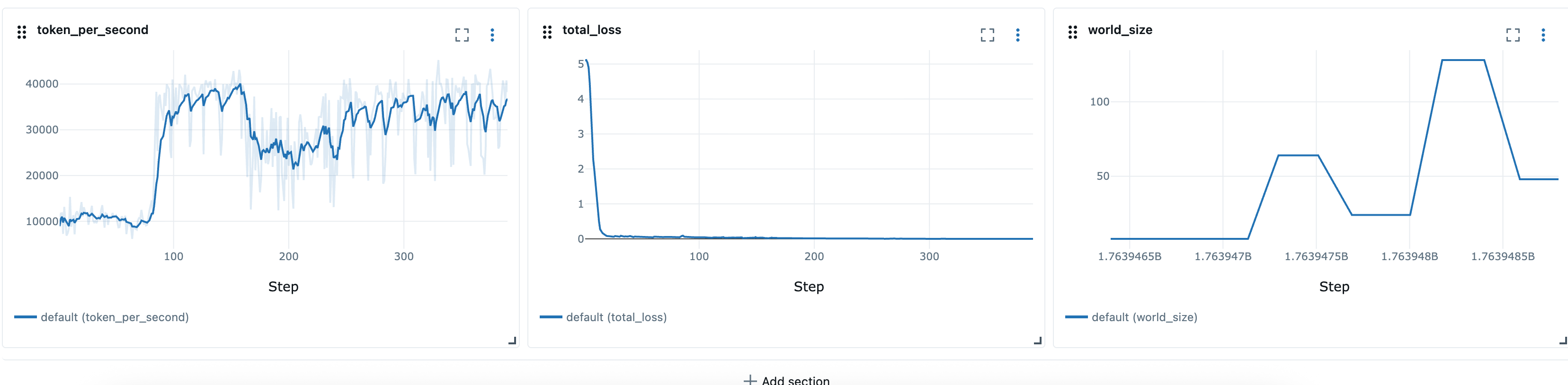
定义弹性配方后,我们可以使用启动器脚本,例如launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh启动弹性训练作业。这类似于使用 Hyperpod 配方启动静态作业。
注意
来自配方支持的 Elastic 训练作业会自动从最新的检查点恢复,但是,默认情况下,每次重启都会创建一个新的训练目录。要正确启用从上一个检查点恢复的功能,我们需要确保重复使用相同的训练目录。这可以通过设置来完成
recipes.training_config.training_args.override_training_dir=true
Use-case 示例和限制
Scale-up 当有更多资源可用时
当集群上有更多可用资源时(例如,其他工作负载已完成)。在此活动期间,训练控制器将自动扩大训练作业。下文将对此行为进行说明。
为了模拟有更多可用资源的情况,我们可以提交高优先级作业,然后通过删除高优先级作业来释放资源。
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
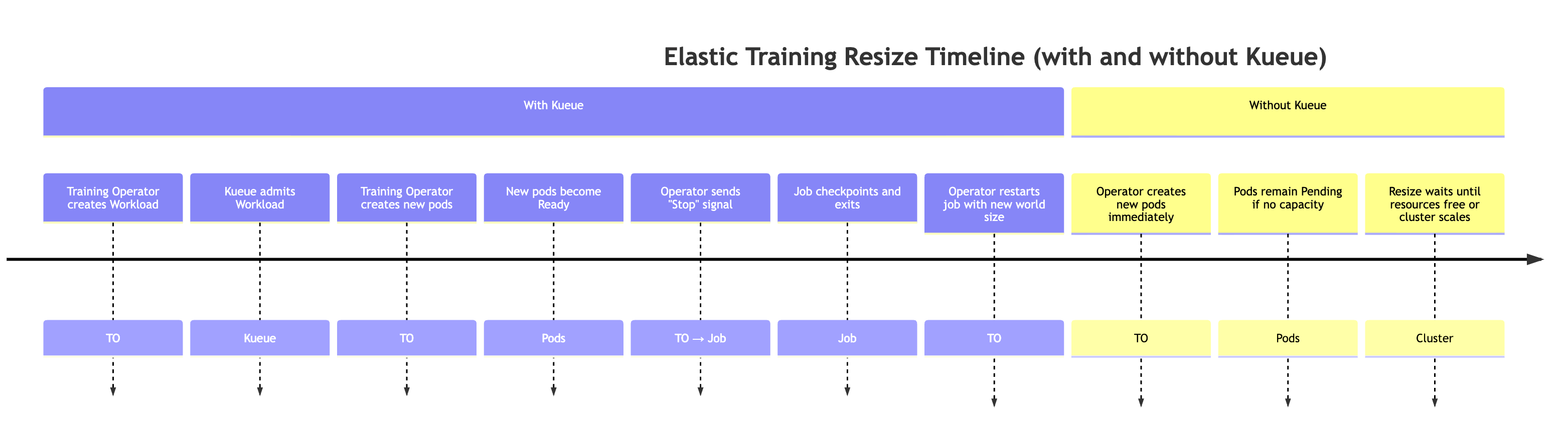
预期行为:
-
训练操作员创建 Kueue Workload 当弹性训练作业请求更改世界大小时,训练操作员会额外生成一个代表新资源需求的 Kueue Workload 对象。
-
Kueue 承认工作负载 Kueue 会根据可用资源、优先级和队列策略评估请求。一旦获得批准,工作负载即被接受。
-
训练操作员创建额外的 Pods 入场后,操作员会启动达到新世界大小所需的额外吊舱。
-
当新 pod 准备就绪时,训练操作员会向训练脚本发送一个特殊的弹性事件信号。
-
训练作业执行检查点,为正常关闭做准备。训练过程通过调用 el astic_event_det ected () 函数定期检查弹性事件信号。一旦检测到,它就会启动检查点。成功完成检查点后,训练过程将干净利落地退出。
-
训练操作员使用新的世界大小重新启动作业。操作员等待所有进程退出,然后使用更新的世界大小和最新的检查点重新启动训练作业。
注意:不使用 Kueue 时,训练操作员会跳过前两个步骤。它会立即尝试创建新的世界大小所需的额外吊舱。如果集群中没有足够的可用资源,则这些 Pod 将保持待定状态,直到容量可用为止。
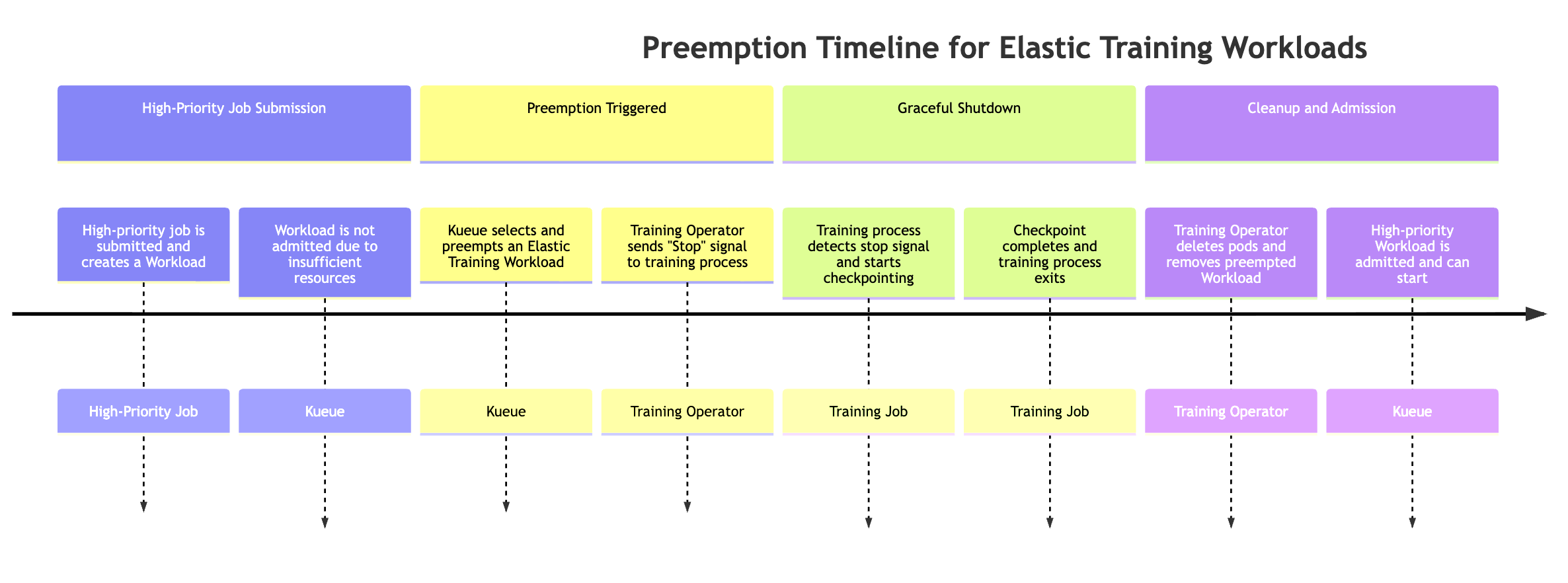
通过高优先级任务抢占先机
当高优先级的作业需要资源时,弹性作业可以自动缩小规模。要模拟这种行为,您可以提交弹性训练作业,该作业从训练开始起使用最大数量的可用资源,然后提交高优先级作业,然后观察抢占行为。
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
当高优先级的作业需要资源时,Kueue 可以抢占优先级较低的 Elastic Training 工作负载(可能有 1 个以上的工作负载对象与 Elastic Training 作业相关联)。抢占过程遵循以下顺序:
-
提交了高优先级作业该作业创建了新的 Kueue 工作负载,但由于集群资源不足,无法接受该工作负载。
-
Kueue 抢占了 Elastic Training 作业的其中一个工作负载 Elastic 作业可能有多个活跃的工作负载(每个世界大小的配置一个)。Kueue 根据优先级和队列策略选择一个要抢占的对象。
-
训练操作员发送弹性事件信号。触发抢占后,训练操作员会通知正在运行的训练过程优雅地停止。
-
训练过程执行检查点操作。训练作业会定期检查弹性事件信号。检测到后,它会开始协调检查点以保持进度,然后再关机。
-
训练操作员清理吊舱和工作负载。操作员等待检查点完成,然后删除属于抢占工作负载的训练 pod。它还会从 Kueue 中移除相应的工作负载对象。
-
允许高优先级工作负载。资源释放后,Kueue 接受了高优先级作业,允许它开始执行。
抢占可能会导致整个训练作业暂停,这可能不是所有工作流程都需要的。为了避免暂停全部任务,同时仍然允许弹性扩展,客户可以通过定义两个replicaSpec部分在同一个培训作业中配置两个不同的优先级别:
-
具有普通或高优先级的主要(固定)ReplicaSpec
-
包含保持训练作业运行所需的最低副本数量。
-
使用更高的值 PriorityClass,确保这些副本永远不会被抢占。
-
即使集群面临资源压力,也能保持基准进度。
-
-
优先级较低的弹性(可扩展)ReplicaSpec
-
包含在弹性扩展期间提供额外计算能力的其他可选副本。
-
使用较低的 PriorityClass,允许 Kueue 在优先级较高的作业需要资源时抢占这些副本。
-
确保只回收弹性部分,同时核心训练不间断地继续进行。
-
此配置支持部分抢占,即只回收弹性容量,从而保持训练的连续性,同时仍然支持多租户环境中的公平资源共享。示例:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
处理 pod 驱逐、吊舱崩溃和硬件降级:
HyperPod 训练操作员包括内置机制,可在训练过程意外中断时恢复训练过程。中断可能由于各种原因而发生,例如训练代码故障、Pod 驱逐、节点故障、硬件降级和其他运行时问题。
发生这种情况时,操作员会自动尝试重新创建受影响的 pod,并从最新的检查点恢复训练。例如,如果由于剩余容量不足而无法立即恢复,则操作员可以通过暂时缩小世界规模和缩小弹性训练作业来继续前进。
当弹性训练作业崩溃或丢失副本时,系统的行为如下:
-
恢复阶段(使用备用节点)Training Controller 会
faultyScaleDownTimeoutInSeconds等待资源变为可用状态,并尝试通过在备用容量上重新部署 pod 来恢复失败的副本。 -
Elastic scale-down 如果在超时窗口内无法恢复,则训练操作员会将作业缩小到更小的世界规模(如果作业的弹性策略允许)。然后,使用更少的副本恢复训练。
-
Elastic scale-up 当其他资源再次可用时,操作员会自动将训练作业扩展到首选的世界规模。
这种机制可确保即使在资源压力或基础设施部分故障的情况下,也能以最少的停机时间继续训练,同时仍然可以利用弹性扩展。
将弹性训练与其他 HyperPod 功能结合使用
Elastic 训练目前不支持无检查点训练功能、 HyperPod 托管分层检查点或 Spot 实例。
注意
我们收集某些常规汇总和匿名的运营指标,以提供基本的服务可用性。这些指标的创建是完全自动化的,不需要对底层模型训练工作负载进行人工审查。这些指标与任务和扩展操作、资源管理和基本服务功能有关。