本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
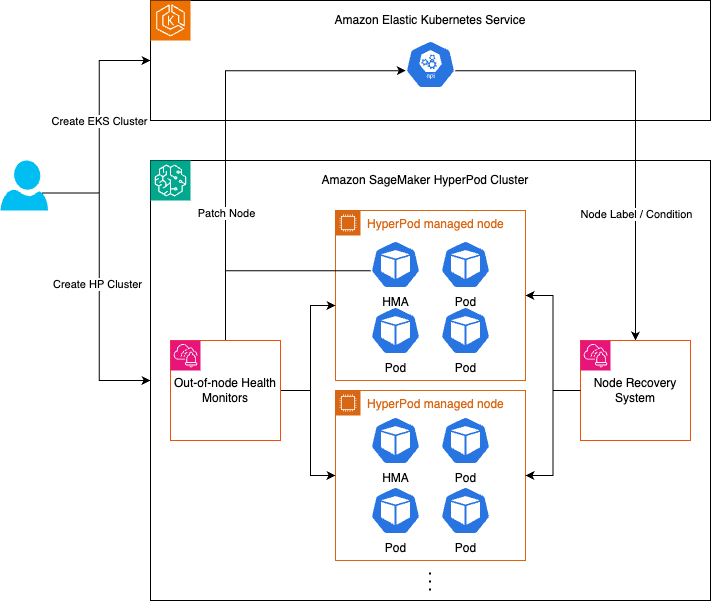
Health 监控系统
SageMaker HyperPod 健康监控系统包括两个组件
-
安装在节点中的监控代理,包括用作主机运行状况监控器的运行状况监控代理 (HMA) 和一组节点外运行状况监视器。
-
由管理的节点恢复系统 SageMaker HyperPod。运行状况监控系统将通过监控代理持续监控节点的运行状况,然后在使用节点恢复系统检测到故障时自动采取措施。
由运行状况 SageMaker HyperPod 监控代理完成的健康检查
SageMaker HyperPod 运行状况监控代理会检查以下内容。
NVIDIA GPU
-
nvidia-smi输出中的错误 -
Amazon Elastic Compute Cloud (EC2) 平台生成的日志中的各种错误
-
GPU 计数验证 — 如果特定实例类型的预期 GPU 数量(例如:ml.p5.48xlarge 实例类型中的 8 个 GPU)与返回的计数不匹配,则 HMA 会重新启动该节点
nvidia-smi
Amazon Trainium
-
神经元节点问题检测器生成的输出(有关神经 Amazon 元节点问题检测器的更多信息,请参阅 Amazon EKS 集群中 Amazon 神经元节点的节点问题检测和恢复
。) -
Amazon EC2 平台生成的日志中的各种错误
-
Neuron Device Count 验证 — 如果特定实例类型中的实际神经元设备计数与返回的计数不匹配
neuron-ls,则 HMA 会重新启动节点
上述检查是被动的,后台 HyperPod 运行状况检查会持续在您的节点上运行。除了这些检查外, HyperPod 还会在创建和更新 HyperPod 集群期间运行深度(或主动)运行状况检查。了解有关深度运行状况检查的更多信息。
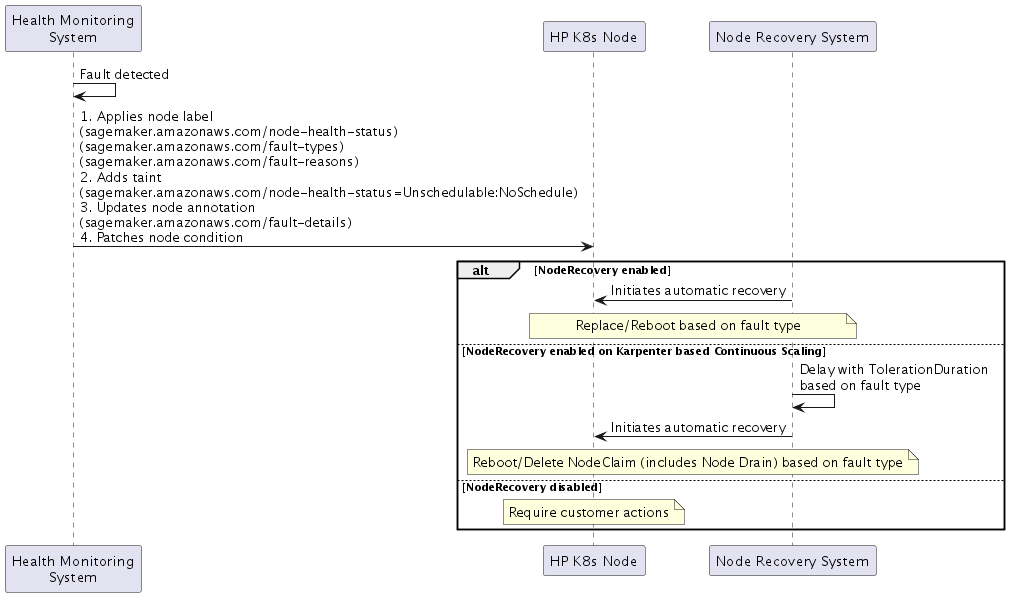
故障检测
当 SageMaker HyperPod 检测到故障时,它会实现由四部分组成的响应:
-
节点标签
-
Health 状态:
sagemaker.amazonaws.com/node-health-status -
错误类型:用于高级分类的
sagemaker.amazonaws.com/fault-types标签 -
故障原因:详细故障信息的
sagemaker.amazonaws.com/fault-reasons标签
-
-
节点污点
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
节点注释
-
故障详情:
sagemaker.amazonaws.com/fault-details -
记录节点上发生的最多 20 个带有时间戳的故障
-
-
节点条件(Kubernetes
节点条件) -
反映节点条件下的当前生命值:
-
类型:与故障类型相同
-
状态:
True -
原因:与故障原因相同
-
LastTransitionTime: 故障发生时间
-
-
运行 SageMaker HyperPod 状况监控代理生成的日志
运行 SageMaker HyperPod 状况监控代理是一项开箱即用的运行状况检查功能,可在所有集群上持续运行。 HyperPod 运行状况监控代理将在 GPU 或 Trn 实例上检测到的运行状况事件发布到集群日志组 CloudWatch /aws/sagemaker/Clusters/下。
来自 HyperPod 运行状况监控代理的检测日志创建为SagemakerHealthMonitoringAgent为每个节点命名的单独日志流。您可以使用日志见解查询检测日志,如下所示。 CloudWatch
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
返回的输出结果应与下面类似。
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}