本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon 中的竞价型实例 SageMaker HyperPod
Amazon SageMaker HyperPod 支持 Amazon EC2 竞价型实例,可为容错和无状态 AI/ML 工作负载节省大量成本。用例包括批量推理和训练作业、超参数调整和实验工作负载。您还可以使用竞价型实例在低成本容量可用时自动扩展计算容量,并在回收增加的竞价容量后缩减到按需容量。
默认情况下,使用竞价型实例 HyperPod的持续配置功能,该功能 SageMaker HyperPod 允许在后台自动配置剩余容量,同时在可用实例上立即启动工作负载。 HyperPod 当节点配置由于容量限制或其他问题而遇到故障时, SageMaker HyperPod 会在后台自动重试,直到集群达到所需的规模,这样您的自动扩展操作就可以保持弹性和非阻塞性。您也可以将竞价型实例与基于 Karpenter 的自动扩缩功能配合使用。
需要考虑的关键能力和概念
-
与按需实例相比,最多可节省 90% 的成本
-
将竞价型实例用于可以处理中断以及任务开始和完成时间灵活的作业
-
使用 Karpenter 进行自动扩展时,您可以配置 HyperPod 为在 Spot 容量中断或不可用时自动回退到按需
-
访问支持的各种 CPU、GPU 和加速器实例类型 HyperPod
-
容量可用性取决于 EC2 的供应量,并因地区和实例类型而异
-
您可以使用 EC2 提供的竞价型实例顾问等各种工具执行各种操作,例如确定获取所需实例
或被中断的可能性
开始使用
先决条件
在开始之前,请确保您满足以下条件:
Amazon CLI 已安装并配置
设置您的 Amazon 凭证和区域:
aws configure
有关详细说明,请参阅Amazon 凭证文档。
用于 SageMaker HyperPod 执行的 IAM 角色
要更新集群,必须先为 Karpenter 创建Amazon 身份和访问管理
VPC 和 EKS 集群设置
2.1 创建 VPC 和 EKS 集群
按照 E HyperPod KS 设置指南进行以下操作:
-
创建子网位于多个可用区的 VPC
-
创建 EKS 集群。
-
使用 Helm 图表安装所需的依赖项
2.2 设置环境变量
export EKS_CLUSTER_ARN="arn:aws:eks:REGION:ACCOUNT_ID:cluster/CLUSTER_NAME" export EXECUTION_ROLE="arn:aws:iam::ACCOUNT_ID:role/SageMakerExecutionRole" export BUCKET_NAME="your-s3-bucket-name" export SECURITY_GROUP="sg-xxxxx" export SUBNET="subnet-xxxxx" export SUBNET1="subnet-xxxxx" export SUBNET2="subnet-xxxxx" export SUBNET3="subnet-xxxxx"
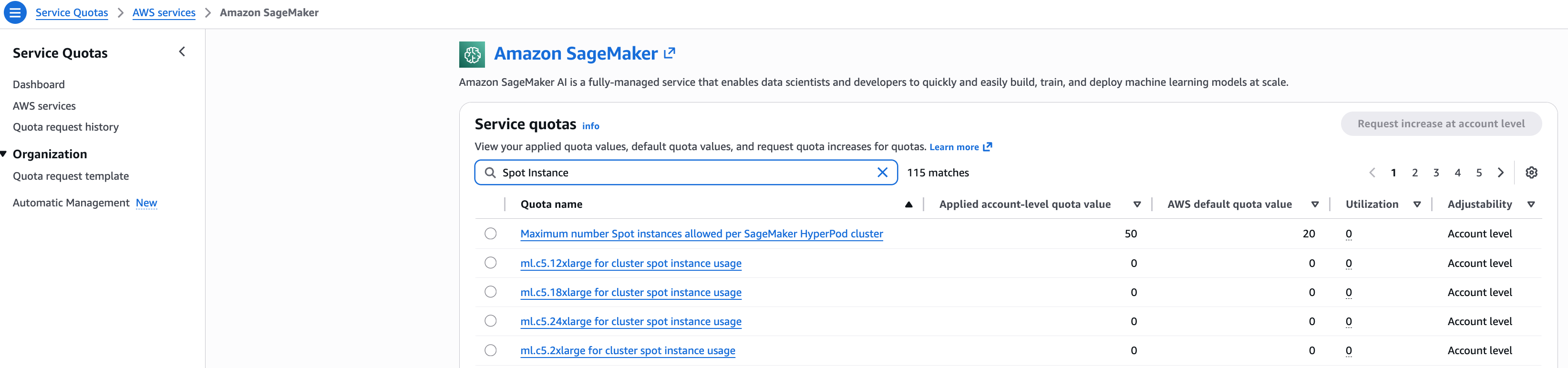
竞价型实例的服务配额
确认您是否具有要在 SageMaker HyperPod 集群中创建的实例所需的配额。要查看您的配额,请在 Service Quotas 控制台上,在导航窗格中选择 Amazon 服务,然后选择 SageMaker。例如,以下屏幕截图显示了 c5 实例的可用配额。
查看现货供应情况
在创建竞价型实例组之前,请检查不同可用区的可用性:
aws ec2 get-spot-placement-scores \ --region us-west-2 \ --instance-types c5.2xlarge \ --target-capacity 10 \ --single-availability-zone \ --region-names us-west-2
提示:将放置分数较高的可用区域作为目标,以获得更好的可用性。您也可以查看竞价型实例顾问和 EC2 竞价定价以了解可用性。选择可用性分数更高的所需可用区,并配置具有关联子网的实例组以在该可用区中启动实例。
创建实例组(不自动扩展)
CreateCluster (现货)
aws sagemaker create-cluster \ --cluster-name clusterNameHere \ --orchestrator 'Eks={ClusterArn='$EKS_CLUSTER_ARN'}' \ --node-provisioning-mode "Continuous" \ --cluster-role 'arn:aws:iam::YOUR-ACCOUNT-ID:role/SageMakerHyperPodRole' \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]' --vpc-config '{ "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET'"] }'
更新集群(Spot + 按需)
aws sagemaker update-cluster \ --cluster-name "my-cluster" \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-x-az3", "InstanceType": "ml.c5.xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} }, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET3'"] } }, { "InstanceGroupName": "auto-spot-c5-2x-az2", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET2'"] } }, { "InstanceGroupName": "auto-ondemand-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]'
CapacityRequirements实例组一经创建就无法修改。
描述集群
aws sagemaker describe-cluster --cluster-name $HP_CLUSTER_NAME --region us-west-2
## Sample Response { "ClusterName": "my-cluster", "InstanceGroups": [ { "InstanceGroupName": "ml.c5.2xlarge", "InstanceType": "ml.c5.xlarge", "InstanceCount": 5, "CurrentCount": 3, "CapacityRequirements: { "Spot": {} }, "ExecutionRole": "arn:aws:iam::account:role/SageMakerExecutionRole", "InstanceStorageConfigs": [...], "OverrideVpcConfig": {...} } // Other IGs ] }
DescribeClusterNode
aws sagemaker describe-cluster-node --cluster-name $HP_CLUSTER_NAME --region us-west-2
## Sample Response { "NodeDetails": { "InstanceId": "i-1234567890abcdef1", "InstanceGroupName": "ml.c5.2xlarge", "CapacityType": "Spot", "InstanceStatus": {...} } }
使用控制台
创建和配置集 SageMaker HyperPod 群
首先,启动并配置您的 SageMaker HyperPod EKS 集群,并验证在创建集群时是否启用了持续配置模式。完成以下步骤:
-
在 SageMaker AI 控制台上,在导航窗格中选择 HyperPod 集群。
-
在 Amazon EKS 上选择创建 HyperPod 集群和编排。
-
对于安装选项,请选择自定义设置。
-
对于名称,输入名称。
-
对于实例恢复,请选择自动。
-
对于实例配置模式,选择使用持续预配。
-
CapacityType : 选择地点
-
选择提交。
控制台屏幕截图:
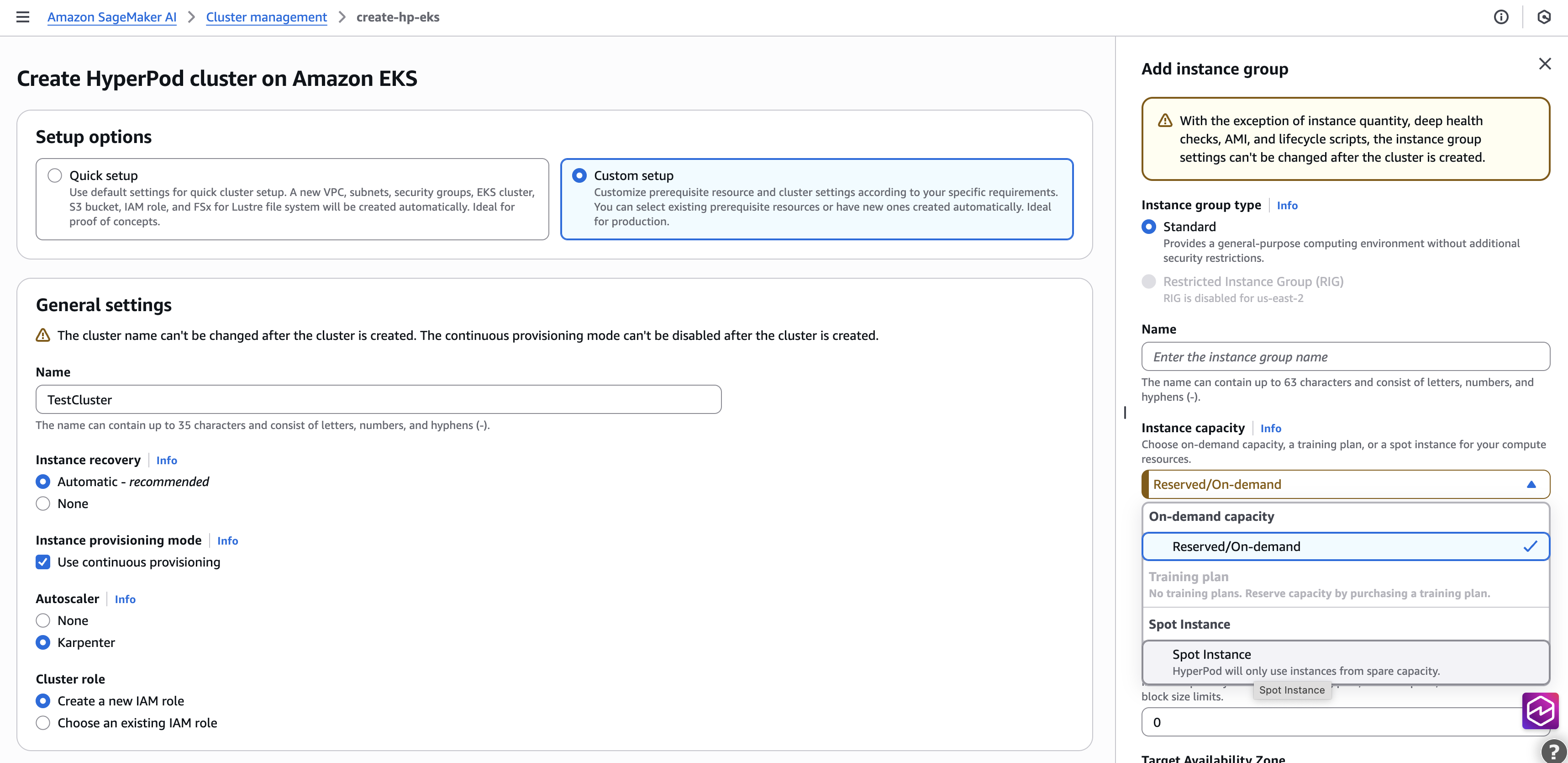
此设置创建必要的配置,例如虚拟私有云 (VPC)、子网、安全组和 EKS 集群,并在集群中安装操作员。如果您想使用现有集群而不是创建新集群,也可以提供现有资源,例如 EKS 集群。此设置大约需要 20 分钟。
向同一个集群添加新的竞价型实例组
向现有的 E HyperPod KS 集群添加 Spot IG。完成以下步骤:
-
在 SageMaker AI 控制台上,在导航窗格中选择 HyperPod 集群。
-
使用 Amazon EKS Orchestration 选择现有 HyperPod 集群(确保已启用持续配置)。
-
单击编辑。
-
在编辑集群页面上,单击创建实例组。
-
在实例组配置中选择容量类型:竞价型实例。
-
点击创建实例组。
-
单击 Submit (提交)。
主机屏幕截图:

使用 Amazon CloudFormation
Resources: TestCluster: Type: AWS::SageMaker::Cluster Properties: ClusterName: "SampleCluster" InstanceGroups: - InstanceGroupName: group1 InstanceType: ml.c5.2xlarge InstanceCount: 1 LifeCycleConfig: SourceS3Uri: "s3://'$BUCKET_NAME'" OnCreate: "on_create_noop.sh" ExecutionRole: "'$EXECUTION_ROLE'", ThreadsPerCore: 1 CapacityRequirements: Spot: {} VpcConfig: Subnets: - "'$SUBNET1'" SecurityGroupIds: - "'$SECURITY_GROUP'" Orchestrator: Eks: ClusterArn: '$EKS_CLUSTER_ARN' NodeProvisioningMode: "Continuous" NodeRecovery: "Automatic"
基于 Karpenter 的自动缩放
创建集群角色
步骤 1:导航到 IAM 控制台
-
前往 Amazon Web Services 管理控制台→ I AM 服务
-
点击左侧边栏中的 “角色”
-
单击 “创建角色”
步骤 2:设置信任策略
-
选择自定义信任策略(而不是 Amazon 服务)
-
将默认 JSON 替换为以下信任策略:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "hyperpod.sagemaker.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }
单击 “下一步”
步骤 3:创建自定义权限策略
由于这些是特定 SageMaker 权限,因此您需要创建自定义策略:
-
点击创建策略(打开新选项卡)
-
单击 JSON 选项卡
-
输入此策略:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sagemaker:BatchAddClusterNodes", "sagemaker:BatchDeleteClusterNodes" ], "Resource": "*" } ] } -
单击下一步
-
给它起个名字
SageMakerHyperPodRolePolicy -
点击创建策略
步骤 4:将策略附加到角色
-
返回角色创建选项卡
-
刷新策略列表
-
搜索并选择您新创建的策略
-
单击下一步
步骤 5:命名和创建角色
-
输入角色名称(例如
SageMakerHyperPodRole) -
如果需要,可以添加描述
-
查看信任策略和权限
-
单击 “创建角色”
验证
创建完成后,您可以通过以下方式进行验证:
-
选中 “信任关系” 选项卡会显示 hyperpod 服务
-
选中 “权限” 选项卡会显示您的自定义策略
-
角色 ARN 将可用于 HyperPod
角色 ARN 的格式将是:
arn:aws:iam::YOUR-ACCOUNT-ID:role/SageMakerHyperPodRole
使用以下方式创建集群 AutoScaling:
为了提高可用性,请 AZs 通过配置子网来创建 IGs 多个子网。您也可以包括 onDemand IGs 作为后备选项。
aws sagemaker create-cluster \ --cluster-name clusterNameHere \ --orchestrator 'Eks={ClusterArn='$EKS_CLUSTER_ARN'}' \ --node-provisioning-mode "Continuous" \ --cluster-role 'arn:aws:iam::YOUR-ACCOUNT-ID:role/SageMakerHyperPodRole' \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 0, // For Auto scaling keep instance count as 0 "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]' --vpc-config '{ "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET'"] }' --auto-scaling ' { "Mode": "Enable", "AutoScalerType": "Karpenter" }'
更新集群(Spot + 按需)
aws sagemaker update-cluster \ --cluster-name "my-cluster" \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-x-az3", "InstanceType": "ml.c5.xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} }, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET3'"] } }, { "InstanceGroupName": "auto-spot-c5-2x-az2", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET2'"] } }, { "InstanceGroupName": "auto-ondemand-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]'
创建 HyperpodNodeClass
HyperpodNodeClass是一种自定义资源,可映射到中预先创建的实例组 SageMaker HyperPod,定义了在 Karpenter 的自动扩展决策中支持哪些实例类型和可用区的限制。要使用HyperpodNodeClass,只需指定要用作 Amazon 计算资源源的 SageMaker HyperPod 集群的名称即可,用于在中扩展 pod NodePools。InstanceGroups您在此处使用的HyperpodNodeClass名称将延续到下一节 NodePool 中,您将在其中引用该名称。这告诉他们该从 NodePool 哪HyperpodNodeClass个那里提取资源。要创建HyperpodNodeClass,请完成以下步骤:
-
创建与以下代码类似的 YAML 文件(例如 nodeclass.yaml)。添加您在创建 SageMaker HyperPod 集群时使用的
InstanceGroup名称。您也可以向现有 SageMaker HyperPod EKS 集群添加新的实例组。 -
在 NodePool 配置中引用该
HyperPodNodeClass名称。
以下是示例HyperpodNodeClass:
apiVersion: karpenter.sagemaker.amazonaws.com/v1 kind: HyperpodNodeClass metadata: name: multiazg6 spec: instanceGroups: # name of InstanceGroup in HyperPod cluster. InstanceGroup needs to pre-created # before this step can be completed. # MaxItems: 10 - auto-spot-c5-2x-az1 - auto-spot-c5-2x-az2 - auto-spot-c5-x-az3 - auto-ondemand-c5-2x-az1
Karpenter 优先考虑竞价型实例组而不是按需实例,如果在配置中指定,则使用按需实例作为后备实例。实例选择按与每个子网的可用区关联的 EC2 竞价放置分数排序。
使用以下方法将配置应用于您的 EKS 集群kubectl:
kubectl apply -f nodeclass.yaml
集 HyperPod 群必须已 AutoScaling 启用且 AutoScaling 状态必须更改为,InService然后HyperpodNodeClass才能应用。它还将实例组的容量显示为 Spot 或 OnDemand。有关更多信息和关键注意事项,请参阅在 SageMaker HyperPod EKS 上自动缩放。
例如
apiVersion: karpenter.sagemaker.amazonaws.com/v1 kind: HyperpodNodeClass metadata: creationTimestamp: "2025-11-30T03:25:04Z" name: multiazc6 uid: ef5609be-15dd-4700-89ea-a3370e023690 spec: instanceGroups: -spot1 status: conditions: // true when all IGs in the spec are present in SageMaker cluster, false otherwise - lastTransitionTime: "2025-11-20T03:25:04Z" message: "" observedGeneration: 3 reason: InstanceGroupReady status: "True" type: InstanceGroupReady // true if subnets of IGs are discoverable, false otherwise - lastTransitionTime: "2025-11-20T03:25:04Z" message: "" observedGeneration: 3 reason: SubnetsReady status: "True" type: SubnetsReady // true when all dependent resources are Ready [InstanceGroup, Subnets] - lastTransitionTime: "2025-11-30T05:47:55Z" message: "" observedGeneration: 3 reason: Ready status: "True" type: Ready instanceGroups: - instanceTypes: - ml.c5.2xlarge name:auto-spot-c5-2x-az2 subnets: - id: subnet-03ecc649db2ff20d2 zone: us-west-2a zoneId: usw2-az2 - capacities: {"Spot": {}}
创建 NodePool
它们对 Karpenter 可以创建的节点以及可以在这些节点上运行的 Pod NodePool 设置了限制。 NodePool 可以设置为执行各种操作,例如:
-
定义标签和污点以限制可以在 Karpenter 创建的节点上运行的 pod
-
将节点创建限制在特定的区域、实例类型和计算机架构等范围内
有关的更多信息 NodePool,请参阅NodePools
要创建 NodePool,请完成以下步骤:
创建一个名nodepool.yaml为所需 NodePool配置的 YAML 文件。以下代码是创建示例的示例配置 NodePool。我们指定包括我们的 NodePool ml.g6.xlarge SageMaker 实例类型,另外还为一个区域指定了该类型。有关更多自定义 NodePools
apiVersion: karpenter.sh/v1 kind: NodePool metadata: name: gpunodepool spec: template: spec: nodeClassRef: group: karpenter.sagemaker.amazonaws.com kind: HyperpodNodeClass name: multiazg6 expireAfter: Never requirements: - key: node.kubernetes.io/instance-type operator: Exists - key: "node.kubernetes.io/instance-type" // Optional otherwise Karpenter will decide based on Job config resource requirements operator: In values: ["ml.c5.2xlarge"] - key: "topology.kubernetes.io/zone" operator: In values: ["us-west-2a"]
提示:在 EC2 Spot 中断时,Hyperpod 会污染节点以触发吊舱驱逐。Karpenter 的整合过程尊重容器中断预算并执行正常的 Kubernetes 驱逐,但是如果您将 consolidateAfter: 0,则可以立即进行整合,从而几乎没有时间进行优雅的容器驱逐。将其设置为非零,最长可达 2 分钟,以允许优雅地驱逐 pod 以满足任何检查点需求。
将应用 NodePool 于您的集群:
kubectl apply -f nodepool.yaml
监控 NodePool 状态以确保状态中的 “就绪” 条件设置为 True:
kubectl get nodepool gpunodepool -oyaml
此示例说明如何使用来指定 Pod 的硬件(实例类型)和位置(可用区)。 NodePool
启动简单的工作负载
以下工作负载运行 Kubernetes 部署,其中部署中的 pod 请求每个 Pod 的每个副本具有 1 个 CPU 和 256 MB 内存。吊舱还没装好。
kubectl apply -f https://raw.githubusercontent.com/aws/karpenter-provider-aws/refs/heads/main/examples/workloads/inflate.yaml
当我们应用它时,我们可以在集群中看到部署和单个节点启动,如以下屏幕截图所示。
要缩放此组件,请使用以下命令:
kubectl scale deployment inflate --replicas 10
有关更多详细信息,请参阅 https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-hyperpod-eks-autoscaling .html。
管理节点中断
竞价型实例可以随时回收。在大多数情况下,EC2 会尽力提供 2 分钟中断通知,但不能保证会发出此通知。在某些情况下,EC2 可能会在没有任何事先警告的情况下立即终止竞价型实例。 HyperPod 自动处理这两种情况:
-
提醒 2 分钟:当 Spot 容量可用时,自动重新尝试优雅地驱逐容量和受控容量更换。
-
恕不另行通知(立即终止):自动重试节点替换(当 Spot 容量可用时),无需优雅驱逐
工作原理
当 EC2 发送 Spot 中断通知时, HyperPod 会自动:
-
检测中断信号
-
污染节点:阻止在中断的实例上调度新 Pod
-
优雅地驱逐 pod:让正在运行的 pod 有时间完成工作或检查其工作(尊重 Kubernetes)
terminationGracePeriodSeconds -
替换容量:自动尝试配置替换实例(竞价型或按需型实例,视可用性而定)。
容量替换的工作原理是自动配置替换实例。当容量不能立即可用时,系统会继续检查,直到可以访问资源。对于非自动扩缩实例组,会 HyperPod 尝试在同一实例组内进行扩展,直到所需的容量可用为止。对于基于 Karpenter 的实例组,当主组无法满足需求时,Karpenter 会对在 Node 类中配置的其他实例组实施回退机制。此外,您可以将按需配置为后备选项,允许 Karpenter 在无法成功扩展 Spot 实例组时自动切换到按需实例。
-
重新安排工作负载:Kubernetes 会自动在运行正常的节点上重新调度已被驱逐的 Pod
查找您的使用情况和账单
要查看竞价型实例的使用情况和账单, HyperPod 可以使用 Cost Explorer 控制台。 Amazon 前往 Billing and Cost Management > Bill
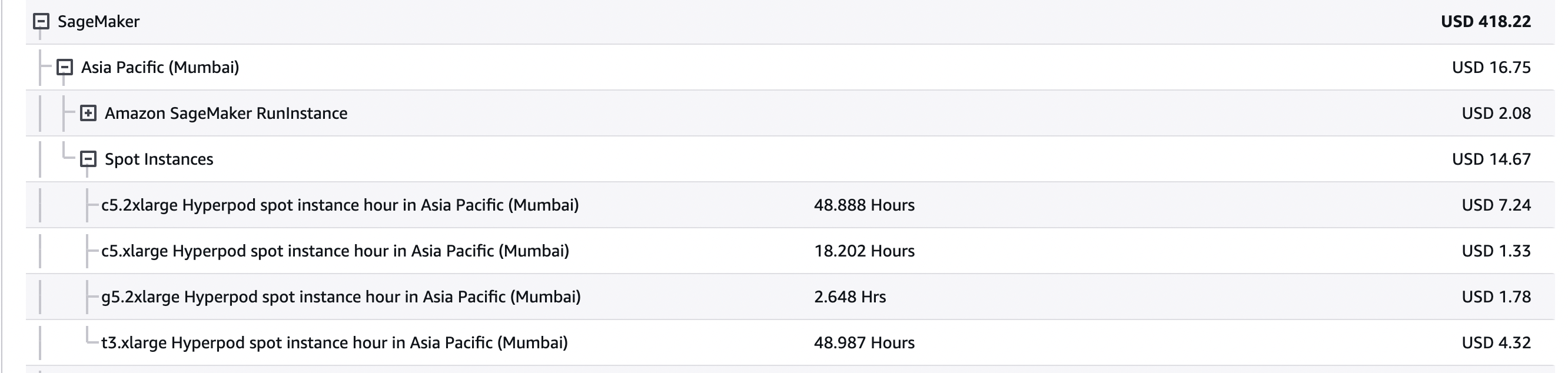
要在控制台上浏览使用情况和账单,请前往账单和成本管理 > Cost Explorer