本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
配置模型提供程序
注意
在本节中,我们假设您计划使用的语言和嵌入模型已经部署。对于提供的模型 Amazon,您应该已经拥有 SageMaker 人工智能终端节点的 ARN 或者可以访问 Amazon Bedrock。对于其他模型提供程序,您应该使用 API 密钥进行身份验证以及授权向您的模型提出的请求。
Jupyter AI 支持多种模型提供程序和语言模型,请参阅其支持的模型
Jupyter AI 的配置因使用聊天用户界面还是神奇命令而异。
在聊天用户界面中配置您的模型提供程序
注意
您可以按照相同的说明配置多个 LLM 和嵌入模型。但是,您必须配置至少一种语言模型。
要配置聊天用户界面
-
在中 JupyterLab,通过选择左侧导航面板中的聊天图标 (
 ) 来访问聊天界面。
) 来访问聊天界面。 -
选择左侧窗格右上角的配置图标 (
 )。这将打开 Jupyter AI 配置面板。
)。这将打开 Jupyter AI 配置面板。 -
填写与服务提供程序相关的字段。
-
适用于 JumpStart 或 Amazon Bedrock 提供的型号
-
在语言模型下拉列表中,选择
sagemaker-endpoint使用 Amazon Bedrock 部署的模型 JumpStart 或bedrock由 Amazon Bedrock 管理的模型。 -
根据您的模型部署在 SageMaker AI 上还是 Amazon Bedrock 上,参数会有所不同。
-
对于使用以下设备部署的模型 JumpStart:
-
在终端节点名称中输入您的终端节点的名称,然后 Amazon Web Services 区域 在区域名称中输入部署模型的名称。要检索 A SageMaker I 终端节点的 ARN,请导航到左侧菜单中的 “推理https://console.amazonaws.cn/sagemaker/
和终端节点”,然后选择该菜单。 -
粘贴为您的模型量身定制的请求架构的 JSON,以及解析模型输出的相应响应路径。
注意
您可以在以下示例笔记本
中找到各种 JumpStart 基础模型的请求和响应格式。每个笔记本都以其演示的模型命名。
-
-
对于由 Amazon Bedrock 管理的模型:在系统上添加存储您的 Amazon 凭证的 Amazon 配置文件(可选),然后 Amazon Web Services 区域 在区域名称中添加部署模型的配置文件。
-
-
(可选)选择您有权访问的嵌入模型。嵌入模型用于从本地文档中捕获更多信息,从而使文本生成模型能够在这些文档的上下文中回答问题。
-
选择保存更改,然后导航到左侧窗格左上角的向左箭头图标 (
 )。这将打开 Jupyter AI 聊天用户界面。您可以开始与模型交互了。
)。这将打开 Jupyter AI 聊天用户界面。您可以开始与模型交互了。
-
-
对于由第三方提供商托管的模型
-
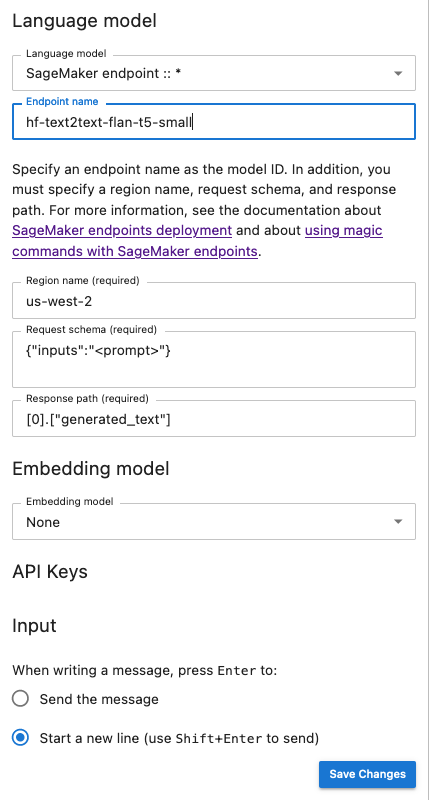
以下快照说明了聊天界面配置面板,该面板设置为调用由 AI 提供 JumpStart 并部署在 SageMaker AI 中的 Flan-t5-small 模型。
将额外的模型参数和自定义参数传递给您的请求
您的模型可能需要额外的参数,例如用于用户协议批准的自定义属性,或调整其他模型参数(如温度或响应长度)。我们建议使用生命周期配置将这些设置配置为 JupyterLab应用程序的启动选项。有关如何创建生命周期配置并将其附加到您的域或从 SageMaker AI 控制台
使用以下 JSON 架构配置额外参数:
{ "AiExtension": { "model_parameters": { "<provider_id>:<model_id>": { Dictionary of model parameters which is unpacked and passed as-is to the provider.} } } } }
以下脚本是 JSON 配置文件的示例,您可以在创建 JupyterLab 应用程序 LCC 时使用该文件来设置部署在 Amazon Bedrock 上的 AI21 Labs Jurassic-2 模型的最大长度。增加模型生成响应的长度可以防止模型响应的系统截断。
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:ai21.j2-mid-v1": {"model_kwargs": {"maxTokens": 200}}}}}' # equivalent to %%ai bedrock:ai21.j2-mid-v1 -m {"model_kwargs":{"maxTokens":200}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
以下脚本是一个用于创建 JupyterLab 应用程序 LCC 的 JSON 配置文件示例,该文件用于为部署在 Amazon Bed rock 上的 Anthropic Claude 模型设置其他模型参数。
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:anthropic.claude-v2":{"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":25 0,"max_tokens_to_sample":2}}}}}' # equivalent to %%ai bedrock:anthropic.claude-v2 -m {"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":250,"max_tokens_to_sample":2000}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
将 LCC 附加到域名或用户个人资料后,请在启动应用程序时将您的 LCC 添加到您的 JupyterLab 空间。要确保 LCC 更新您的配置文件,请在终端中运行 more ~/.jupyter/jupyter_jupyter_ai_config.json。文件内容应与传递给 LCC 的 JSON 文件内容一致。
在笔记本中配置您的模型提供程序
使用 %%ai 和 %ai 魔法命令通过 Studio Classic 笔记本电脑中的 Jupyter AI 调用模型 JupyterLab
和 %ai 魔法命令通过 Studio Classic 笔记本电脑中的 Jupyter AI 调用模型 JupyterLab-
在您的笔记本环境中安装特定于您的模型提供程序的客户端库。例如,在使用 OpenAI 模型时,您需要安装
openai客户端库。您可以在 Jupyter AI 模型提供程序列表的 Python 软件包列中找到每个提供程序所需的客户端库列表。 注意
对于托管的模型 Amazon,已安装在使用
boto3的 SageMaker AI 分发映像中 JupyterLab,或者安装在 Studio Classic 中使用的任何数据科学映像中。 -
-
对于托管的模特 Amazon
确保您的执行角色有权为由 Amazon Bedrock 提供的模型调用您的 SageMaker AI 终端节点, JumpStart 或者您有权访问 Amazon Bedrock。
-
对于由第三方提供商托管的模型
使用环境变量在笔记本环境中导出提供程序的 API 密钥。您可以使用以下神奇命令。将命令中的
provider_API_key替换为在 Jupyter AI 模型提供商列表的环境变量栏中为您的提供程序找到的环境变量。 %env provider_API_key=your_API_key
-