本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
模型性能报告
Amazon SageMaker AI 模型质量报告(也称为绩效报告)为 AutoML 作业生成的最佳候选模型提供见解和质量信息。这包括有关作业详细信息、模型问题类型、目标函数和各种指标的信息。此部分详细介绍文本分类问题的性能报告的内容,并说明如何访问 JSON 文件原始数据格式的指标。
在对 DescribeAutoMLJobV2 响应的 BestCandidate.CandidateProperties.CandidateArtifactLocations.ModelInsights 位置,您可以找到为最佳候选项生成的模型质量报告构件的 Amazon S3 前缀。
性能报告分为两个部分:
-
第一部分包含有关生成模型的 Autopilot 作业的详细信息。
-
第二部分包含带有各种性能指标的模型质量报告。
Autopilot 作业详细信息
报告的第一部分提供了有关生成模型的 Autopilot 作业的一些常规信息。这些详情包括以下信息:
-
Autopilot 候选项名称:最佳候选模型的名称。
-
Autopilot 作业名称:作业的名称。
-
问题类型:问题的类型。在本例中为文本分类。
-
目标指标:用于优化模型性能的目标指标。在本例中为准确性。
-
优化方向:指示是最小化还是最大化目标指标。
模型质量报告
模型质量信息由 Autopilot 模型见解生成。所生成报告的内容取决于要解决的问题类型。报告指定了评估数据集中包含的行数,以及进行评估的时间。
指标表
模型质量报告的第一部分包含指标表。它们适用于模型所解决的问题类型。
下图是 Autopilot 针对图像或文本分类问题生成的指标表示例。它显示指标名称、值和标准差。
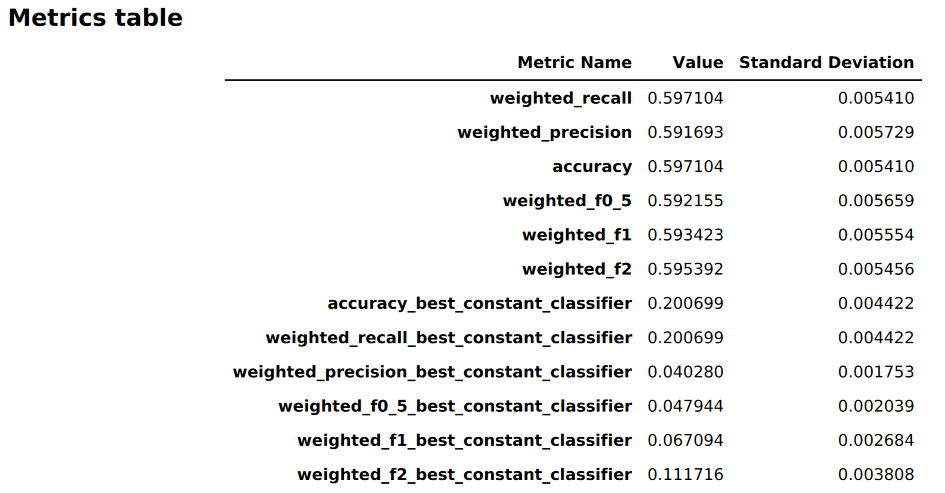
图形模型性能信息
模型质量报告的第二部分包含图形信息,用于帮助您评估模型性能。此部分的内容取决于所选的问题类型。
混淆矩阵
混淆矩阵提供了一种方法,用于可视化模型针对不同问题的二元分类和多元分类预测的准确性。
图中假阳性率 (FPR) 和真阳性率 (TPR) 的组成部分摘要定义如下。
-
正确预测
-
真阳性 (TP):预测的值为 1,真正的值为 1。
-
真阴性 (TN):预测的值为 0,真正的值为 0。
-
-
错误预测
-
假阳性 (FP):预测的值为 1,但真正的值为 0。
-
假阴性 (FN):预测的值为 0,但真正的值为 1。
-
模型质量报告中的混淆矩阵包含以下内容。
-
针对实际标签的正确和错误预测的数量和百分比
-
准确预测的数量和百分比按照从左上角到右下角沿对角线排列。
-
不准确预测的数量和百分比按照从右上角到左下角沿对角线排列。
在混淆矩阵上,错误预测是混淆值。
下图是一个多元分类问题的混淆矩阵的示例。模型质量报告中的混淆矩阵包含以下内容。
-
垂直轴分为三行,包含三个不同的实际标签。
-
水平轴分为三列,包含模型所预测的标签。
-
彩色条形图为较多数量的样本分配较深的色调,以直观地指示分类到每个类别中值的数量。
在下面的示例中,模型正确预测了标签 f 的 354 个实际值、标签 i 的 1094 个值和标签 m 的 852 个值。色调的差异表明数据集不平衡,因为值 i 的标签比值 f 或 m 要多得多。
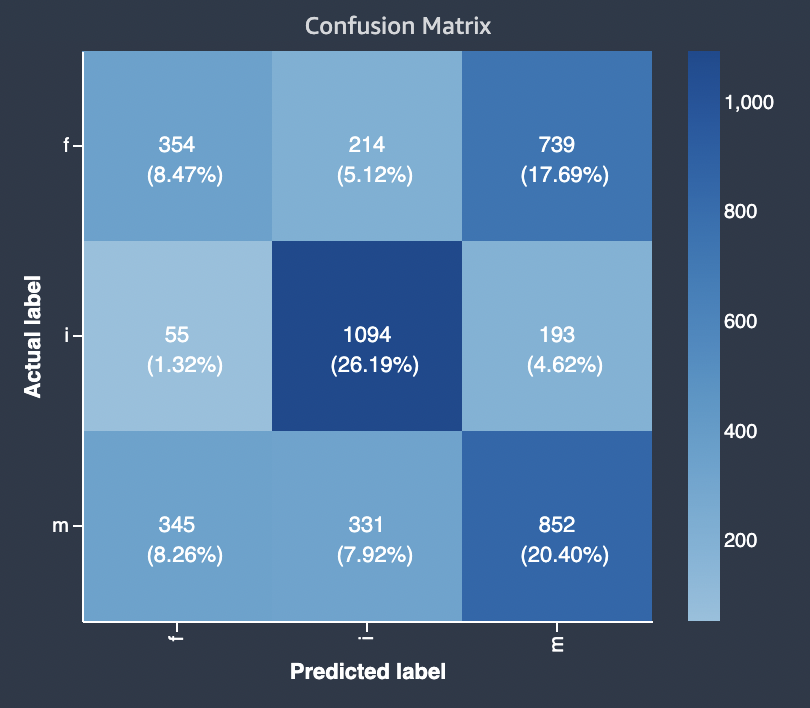
模型质量报告提供了一个混淆矩阵,对于多元分类问题类型,最多可容纳 15 个标签。如果与标签对应的行显示 Nan 值,这意味着用于检查模型预测的验证数据集不包含带有该标签的数据。