本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SageMaker 训练编译器故障排除
重要
Amazon Web Services (Amazon) 宣布, SageMaker 训练编译器将没有新版本或新版本。你可以继续通过现有的 Dee Amazon p Lear SageMaker ning Containers (DLC) 使用 Training Compiler 进行 SageMaker 训练。值得注意的是,尽管现有的 DLC 仍然可以访问,但根据Amazon 深度学习容器框架支持政策 Amazon,它们将不再收到来自的补丁或更新。
在遇到错误时,您可以根据以下列表尝试对训练作业进行问题排查。如果您需要更多支持,请通过 Amazon SageMaker AI Amazon 支持
与本机框架训练作业相比,训练作业未按预期收敛
收敛问题从 “ SageMaker 训练编译器开启时模型无法学习” 到 “模型正在学习但比原生框架慢” 不等。在本故障排除指南中,我们假设如果没有 T SageMaker raining Compiler(在本机框架中),您的收敛效果很好,因此将其视为基准。
在遇到此类收敛问题时,第一步是确定问题是限于分布式训练还是源于单 GPU 训练。使用 Training Compiler 进行分布式 SageMaker 训练是单 GPU 训练的扩展,增加了额外的步骤。
-
设置具有多个实例或 GPU 的集群。
-
将输入数据分发给所有工作线程。
-
同步来自所有工作线程的模型更新。
因此,单 GPU 训练中的任何收敛问题都会传播到具有多个工作线程的分布式训练。
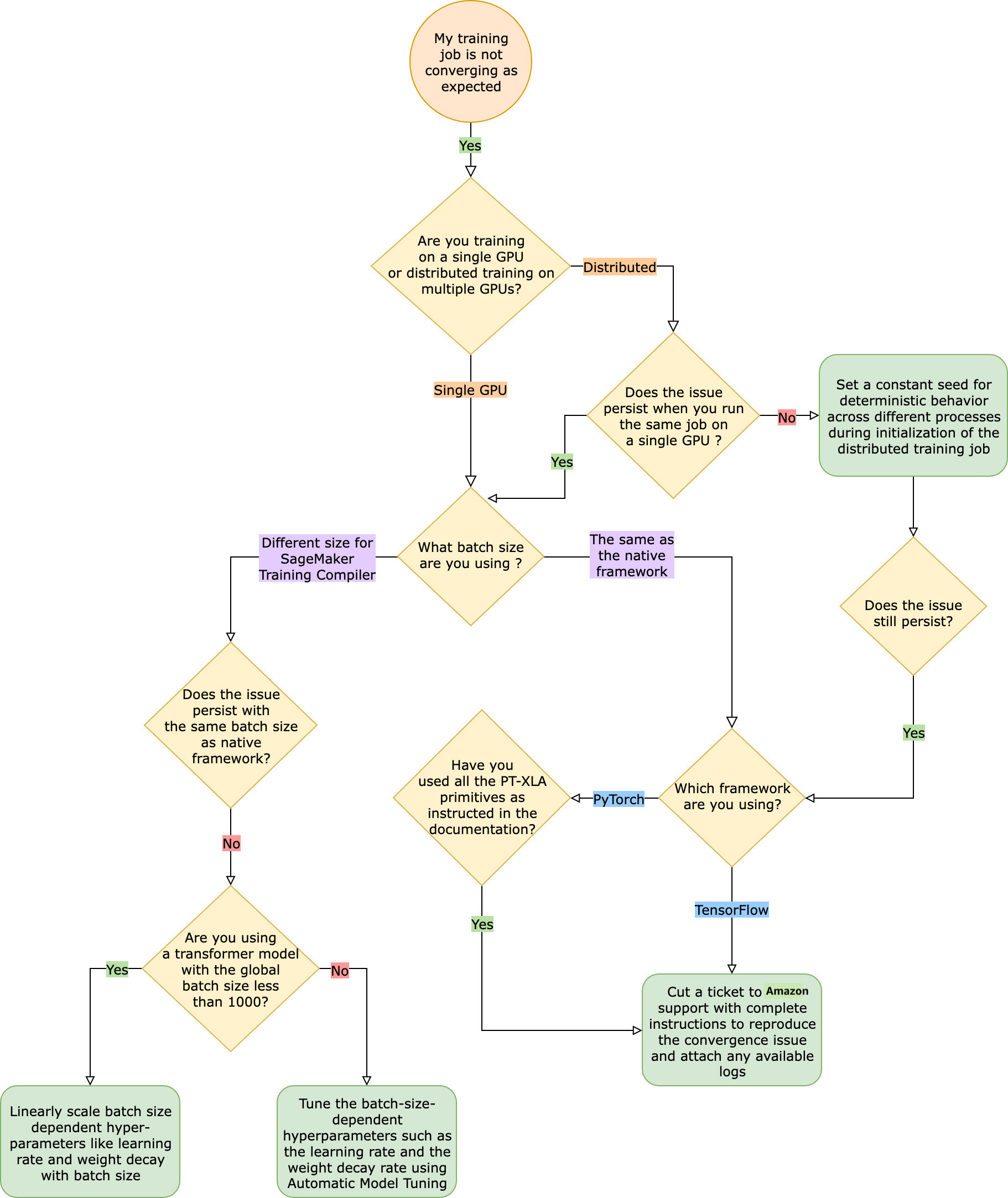
单 GPU 训练中出现的收敛问题
如果您的收敛问题源于单 GPU 训练,则可能是由于超参数或 torch_xla API 的设置不当所致。
检查超参数
使用 SageMaker 训练编译器进行训练会导致模型的内存占用量发生变化。编译器会智能地在重用和重新计算之间进行仲裁,从而相应地增加或减少内存使用量。要利用这一点,在将训练作业迁移到 Training Compiler 时,必须重新调整批次大小和相关的超参数。 SageMaker 但是,错误的超参数设置通常会导致训练损失振荡,并可能最终导致较慢的收敛速度。在极少数情况下,激进的超参数可能会导致模型无法学习(训练损失指标不会减少或返回 NaN)。要确定收敛问题是否是由超参数引起的,请对使用和不使用 Training Compiler 的两个训练作业进行并排测试,同时保持所有超参数不 SageMaker 变。
检查是否已针对单 GPU 训练正确设置 torch_xla API
如果基准超参数仍存在收敛问题,则需要检查是否存在不当使用 torch_xla API 的情况,特别是用于更新模型的 API。基本上,torch_xla 继续以图表形式累积指令(延迟执行),直到明确指示它运行累积的图表。torch_xla.core.xla_model.mark_step() 函数可推进累积图的执行。每次模型更新后以及打印和记录任何变量前,都应使用此函数同步图表的执行。如果它缺少同步步骤,模型可能会在打印、记录和后续正向传递过程中使用内存中的旧值,而不是使用每次迭代和模型更新后都必须同步的最新值。
将 SageMaker 训练编译器与梯度缩放(可能来自使用 AMP)或渐变剪辑技术结合使用时,情况可能会更加复杂。使用 AMP 进行梯度计算的相应顺序如下。
-
使用扩展进行梯度计算
-
梯度取消扩展、梯度裁剪,然后扩展
-
模型更新
-
使用
mark_step()同步图表执行
要为列表中提到的操作找到正确的 API,请参阅将训练脚本迁移到 Training Compil SageMaker er 的指南。
考虑使用自动模型调整
如果在使用 SageMaker Training Compiler 时重新调整批次大小和相关的超参数(例如学习率)时出现收敛问题,请考虑使用自动模型调整来调整超参数。您可以参考示例笔记本,了解如何使用 T SageMaker raining Compiler 调整超参数
分布式训练中出现的收敛问题
如果分布式训练中仍存在收敛问题,则可能是由于权重初始化或 torch_xla API 的设置不当所致。
检查跨工作线程的权重初始化
如果在运行包含多个工作线程的分布式训练作业时出现收敛问题,请通过在适用时设置恒定种子来确保所有工作线程的确定性行为一致。请注意权重初始化等涉及随机掩码的技术。在没有恒定种子的情况下,每个工作线程最终可能会训练不同的模型。
检查是否已针对分布式训练正确设置 torch_xla API
如果问题仍然存在,则可能是因不当使用 torch_xla API 进行分布式训练所致。请务必在估算器中添加以下内容,以便使用 Training Compiler 为分布式 SageMaker 训练设置集群。
distribution={'torchxla': {'enabled': True}}
这应在训练脚本中附带函数 _mp_fn(index),为每个工作线程调用该函数一次。如果没有 mp_fn(index) 函数,您最终可能会让每个工作线程单独训练模型,而不共享模型更新。
接下来,请确保按照有关将训练脚本迁移到 Training Compiler 的文档中的指导,将 torch_xla.distributed.parallel_loader.MpDeviceLoader API 与分布式数据采样器一起使用,如以下示例所示。 SageMaker
torch.utils.data.distributed.DistributedSampler()
这可确保输入数据在所有工作线程之间正确分配。
最后,要同步所有工作线程的模型更新,请使用 torch_xla.core.xla_model._fetch_gradients 收集所有工作线程的梯度,并使用 torch_xla.core.xla_model.all_reduce 将所有收集到的梯度合并为一个更新。
将 SageMaker 训练编译器与梯度缩放(可能来自使用 AMP)或渐变剪辑技术一起使用时,情况可能会更加复杂。使用 AMP 进行梯度计算的相应顺序如下。
-
使用扩展进行梯度计算
-
跨所有工作线程的梯度同步
-
梯度取消扩展、梯度裁剪,然后梯度扩展
-
模型更新
-
使用
mark_step()同步图表执行
请注意,与单 GPU 训练的清单相比,此清单还有一个用于同步所有工作线程的额外项目。
由于缺少 PyTorch/XLA 配置,训练作业失败
如果训练作业失败,且出现 Missing XLA configuration 错误消息,则可能是因错误配置了所使用的每实例 GPU 数导致的。
XLA 需要额外的环境变量来编译训练作业。缺少的最常见环境变量是 GPU_NUM_DEVICES。要使编译器正常工作,您必须将此环境变量的值设置为每实例 GPU 数。
可以通过三种方法设置 GPU_NUM_DEVICES 环境变量:
-
方法 1 — 使用 SageMaker AI 估算器类的
environment参数。例如,如果您使用具有四个 GPU 的ml.p3.8xlarge实例,请执行以下操作:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
方法 2 — 使用 SageMaker AI 估算器类的
hyperparameters参数并在训练脚本中对其进行解析。-
要指定 GPU 的数量,请将键值对添加到
hyperparameters参数。例如,如果您使用具有四个 GPU 的
ml.p3.8xlarge实例,请执行以下操作:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
在您的训练脚本中,解析
n_gpus超参数并将其指定为GPU_NUM_DEVICES环境变量的输入。# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
方法 3 — Hard-code 训练脚本中的
GPU_NUM_DEVICES环境变量。例如,如果您使用的实例具有四个 GPU,请将以下内容添加到脚本中。# train.py import os os.environ["GPU_NUM_DEVICES"] =4
提示
要查找机器学习实例上要使用的 GPU 设备数量,请参阅 Amazon EC2 实例类型页面中的加速计算
SageMaker 训练编译器不会减少总训练时间
如果使用 Training Compiler 的总 SageMaker 训练时间没有缩短,我们强烈建议您仔细检查您的训练配置、输入张量形状的填充策略以及超参数。SageMaker 训练编译器最佳实践和注意事项