要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
架构
适用于 LiveAnalytics 的 Amazon Timestream 从头开始设计,旨在大规模收集、存储和处理时间序列数据。其无服务器架构支持完全解耦的数据摄取、存储和查询处理系统,这些系统能够独立扩展。此设计通过简化每个子系统,使系统更易于实现稳定可靠性、消除扩展瓶颈,并降低相关系统故障的发生概率。随着系统的扩展,这些因素的重要性日益增加。
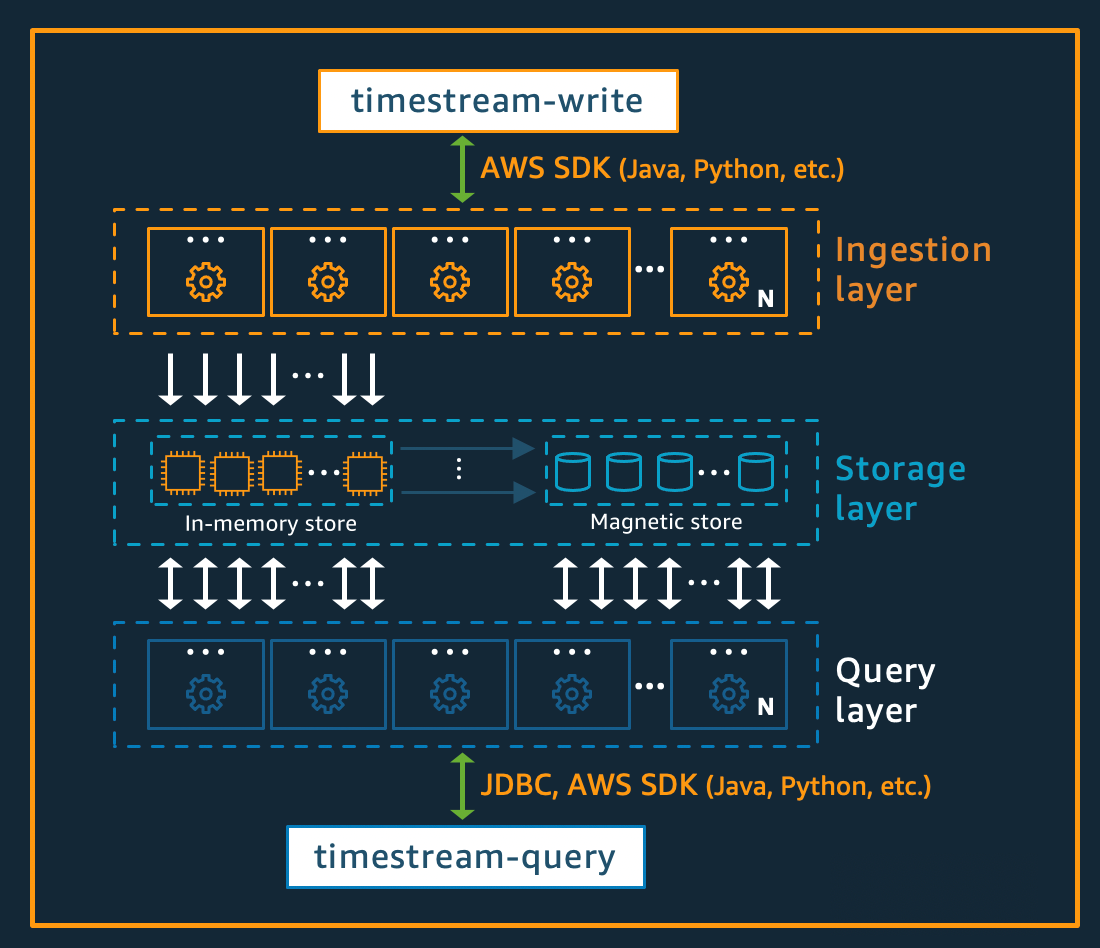
写入架构
在写入时间序列数据时,适用于 LiveAnalytics 的 Amazon Timestream 会将表、分区的写入路由到处理高吞吐量数据写入的容错内存存储实例。反过来,内存存储在独立的存储系统中实现了持久性,该存储系统将数据复制到三个可用区(AZs)。复制基于仲裁,因此节点或整个可用区的丢失均不会中断写入可用性。其他内存存储节点会近乎实时地同步到数据,以便响应查询。读取器副本节点 AZs 也跨越多个节点,以确保高读取可用性。
适用于 LiveAnalytics 的 Timestream 支持将数据直接写入磁性存储,适用于生成吞吐量较低且延迟到达数据的应用程序。延迟到达的数据是指时间戳早于当前时间的数据。与内存存储中的高吞吐量写入类似,写入磁存储的数据将跨三次复制, AZs 并且复制基于法定人数。
无论数据是写入内存还是磁性存储,适用于 LiveAnalytics 的 Timestream 都会在写入存储之前自动对数据进行索引和分区。单个适用于 LiveAnalytics 的 Timestream 表可能有数百、数千甚至数百万个分区。各个分区之间不直接通信,也不共享任何数据(无共享架构)。相反,表的分区通过高度可用的分区跟踪和索引服务进行跟踪。这提供另一种关注点分离,其设计旨在最大限度地降低系统故障的影响,并显著降低相关故障发生的概率。
存储架构
当数据存储在适用于 LiveAnalytics 的 Timestream 中时,数据不仅按时间顺序组织,还会根据随数据写入的上下文属性进行跨时间维度的组织。在时间序列系统实现大规模扩展时,采用能够同时划分“空间”与时间的分区方案至关重要。这是因为大多数时间序列数据都在当前时间或其附近时间点写入。因此,仅基于时间进行分区无法有效分配写入流量,也无法在查询时实现高效的数据修剪。这对极大规模的时间序列处理至关重要,这使适用于 LiveAnalytics 的 Timestream 能够以无服务器方式实现比当前其他常用系统高出数个数量级的扩展能力。由此形成的分区称为“磁贴”,这是因为其代表二维空间的分区(设计为大小相似)。适用于 LiveAnalytics 的 Timestream 表从单个分区(磁贴)开始,然后根据吞吐量需求在空间维度中进行拆分。当磁贴达到特定大小时,会在时间维度上进行拆分,以在数据规模增长时实现更优的读取并行性。
适用于 LiveAnalytics 的 Timestream 旨在自动管理时间序列数据的生命周期。适用于 LiveAnalytics 的 Timestream 提供两种数据存储:内存存储以及经济高效的磁性存储。其还支持配置表级策略,以自动跨存储传输数据。传入的高吞吐量数据写入会存储在内存存储区中,该区域不仅针对写入操作进行数据优化,还针对当前时间点进行的读取操作进行优化,以支持控制面板和警报类查询的运行。当写入、警报和控制面板需求的主要时间段结束后,允许数据自动从内存存储流向磁性存储,以优化成本。适用于 LiveAnalytics 的 Timestream 允许在内存存储上设置数据留存政策,以实现此目的。延迟到达的数据写入操作会直接写入磁性存储。
数据在磁性存储中可用后(因内存存储保留期到期或直接写入磁性存储),就会将其重组为一种高度优化的格式,以实现大容量数据读取。磁性存储还具备数据留存策略,当数据超过其有效期时,可根据时间阈值进行配置。如果数据超过为磁性存储保留策略定义的时间范围,会自动将其删除。因此,使用适用于 LiveAnalytics 的 Timestream,除某些配置以外,数据生命周期管理将在后台无缝完成。
查询架构
适用于 LiveAnalytics 的 Timestream 查询以 SQL 语法表示,该语法扩展时间序列特有的支持功能(包括时间序列专用数据类型和函数),因此对已熟悉 SQL 的开发人员而言,其学习曲线较为平缓。随后,查询将由自适应的分布式查询引擎进行处理。该引擎利用磁贴跟踪和索引服务提供的元数据,在查询发出时无缝访问并整合跨数据存储的数据。这能与客户产生强烈共鸣,因为其将 Rube Goldberg 的诸多复杂机制简化为简单而熟悉的数据库抽象层。
查询由专用的工作节点实例集执行,其中调用执行特定查询的工作节点数量取决于查询复杂度和数据大小。通过在查询运行时实例集和系统存储实例集上实现大规模并行处理,实现对大型数据集的复杂查询性能。快速高效地分析海量数据的能力,正是适用于 LiveAnalytics 的 Timestream 的最大优势之一。单次查询处理 TB 级甚至 PB 级数据时,可能需要数千台计算机同时协同工作。
蜂窝架构
为确保适用于 LiveAnalytics 的 Timestream 能够为应用程序提供几乎无限的扩展能力,同时确保 99.99% 的可用性,该系统还使用蜂窝架构进行设计。与整体扩展系统不同,适用于 LiveAnalytics 的 Timestream 会将自身拆分为多个较小的副本,称为单元格。这允许对单元格进行全面测试,并防止单个单元格中的系统问题影响给定区域中任何其他单元格的活动。虽然适用于 LiveAnalytics 的 Timestream 旨在支持每个区域的多个单元格,但请考虑以下虚构场景,即某个区域存在 2 个单元格。

在上述场景中,数据摄取和查询请求分别由发现端点进行处理,前者用于数据摄取,后者用于查询。随后,发现端点识别出包含客户数据的单元格,并将请求转发至该单元格对应的摄取或查询端点。使用时 SDKs,这些端点管理任务将以透明方式为您处理。