要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
什么是适用于 InfluxDB 的 Timestream?
适用于InfluxDB的Amazon Timestream是一个托管的时间序列数据库引擎,它使应用程序开发人员和 DevOps 团队可以轻松地使用开源 Amazon 为实时时间序列应用程序运行InfluxDB数据库。 APIs借助适用于 InfluxDB 的 Amazon Timestream,可以轻松设置、操作和扩展时间序列工作负载,这些工作负载能够以个位数毫秒的查询响应时间应答查询。
借助适用于 InfluxDB 的 Amazon Timestream,您可以在其 2.x 分支上访问熟悉的 InfluxDB 开源版本功能。这意味着您当前在现有 InfluxDB 开源数据库中使用的代码、应用程序和工具应能与适用于 InfluxDB 的 Amazon Timestream 无缝协作。适用于 InfluxDB 的 Amazon Timestream 可自动备份数据库,并确保数据库软件始终保持最新版本。此外,适用于 InfluxDB 的 Amazon Timestream 可轻松使用复制,增强数据库可用性并提升数据持久性。与所有 Amazon 服务一样,无需前期投资,您只需为使用的资源付费。
数据库实例数
数据库实例是在云中运行的独立数据库环境。这是适用于 InfluxDB 的 Amazon Timestream 的基本构建块。一个数据库实例可以包含多个用户创建的数据库(对于 InfluxDb 2.x数据库,则可以包含组织和存储桶),并且可以使用与访问独立的自管理的InfluxDB实例相同的客户端工具和应用程序进行访问。使用 Amazon 命令行工具、Amazon Timestream InfluxDB API 操作或 Amazon Web Services 管理控制台,可以方便地创建和修改数据库实例。
注意
适用于 InfluxDB 的 Amazon Timestream 支持使用 Influx API 操作和 Influx UI 访问数据库。适用于 InfluxDB 的 Amazon Timestream 不支持直接访问主机。
最多可设置 40 个适用于 InfluxDB 的 Amazon Timestream 实例。
每个数据库实例都有数据库实例 ID。在与 Amazon Timestream for InfluxDB API 和 CLI 命令交互时,此服务生成的名称可以唯一标识数据库实例。 Amazon 数据库实例 ID 对于该客户在某个 Amazon 区域中是唯一的。
数据库实例 ID 是适用于 InfluxDB 的 Timestream 分配给实例的 DNS 主机名的一部分。例如,如果将 influxdb1 指定为数据库实例名称,且服务生成实例 ID c5vasdqn0b,则 Timestream 将自动为实例分配 DNS 端点。示例端点是 c5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws,其中 c5vasdqn0b 是实例 ID。2024 年 12 月 9 日之前创建的所有实例都将保持旧结构,其端点类似于:influxdb1-3ksj4dla5nfjhi.us-east-1.timestream-influxdb.amazonaws.com,其中 influxdb1 是实例名称。
在示例端点中c5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws,字符串3ksj4dla5nfjhi是由生成的唯一账户标识符 Amazon。对于特定区域中的指定账户,示例中的标识符 3ksj4dla5nfjhi 不会发生更改。因此,由该账户创建的所有数据库实例都共享区域中相同的固定标识符。考虑固定标识符的以下特征:
-
目前,适用于 InfluxDB 的 Timestream 不支持数据库实例重命名。
-
对于 2024 年 12 月 9 日之后创建的所有实例,如果删除并使用相同的数据库实例名称重新创建数据库实例,则端点将发生更改,因为将为该实例分配新的实例 ID。在上述日期之前创建的实例将根据实例名称分配相同的端点。
-
如果您使用同一个账户在不同的区域创建数据库实例,则内部生成的标识符会有所不同,因为该区域不同,如在
zxlasoonhvd.4a3j5du5ks7md2.timestream-influxdb.us-east-1.on.aws中。
每个数据库实例仅支持一个适用于 InfluxDB 的 Timestream 数据库引擎。
创建数据库实例时,InfluxDB 需要指定的组织名称。数据库实例可托管多个组织,以及与每个组织关联的多个存储桶。
适用于 InfluxDB 的 Amazon Timestream 允许为数据库实例创建主用户账户和密码,这也是创建过程的一部分。此主用户具有创建组织、存储桶以及对数据执行读取、写入、删除和更新插入操作的权限。您还可以访问 InfluxUI,并在首次登录时检索运算符令牌。从那里,您可以管理所有访问令牌。创建数据库实例时,必须设置主用户密码,但可以随时使用 Influx API、Influx CLI 或 InfluxUI 进行更改。
数据库实例类
数据库实例类确定适用于 InfluxDB 的 Amazon Timestream 数据库实例的计算和内存容量。您需要的数据库实例类取决于您的处理能力和内存要求。
数据库实例类由数据库实例类类型和大小共同组成。例如,db.influx是一种内存优化的数据库实例类类型,适用于与正在运行 InfluxDb 的工作负载相关的高性能内存要求。在 db.influx 实例类类型中,db.influx.2xlarge 是数据库实例类。该类的大小为 2xlarge。
有关实例类定价的更多信息,请参阅适用于 InfluxDB 的 Amazon Timestream 定价
数据库实例类类型
适用于 InfluxDB 的 Amazon Timestream 支持以下使用案例的数据库实例类,这些使用案例针对 InfluxDB 使用案例进行优化。
-
db.influx:这些实例类非常适合在开源 InfluxDB 数据库中运行内存密集型工作负载。
数据库实例类的硬件规格
以下术语描述数据库实例类的硬件规格。
-
vCPU
虚拟中央处理单元的数量 (CPUs)。虚拟 CPU 是可用于比较数据库实例类的容量单位。
-
内存 (GiB)
为数据库实例分配的 RAM(GiB)。内存与 vCPU 之间通常具有一致的比率。举个例子,以 db.influx 实例类为例,它的内存与 vCPU 的比率类似于 r7g 实例类。 EC2
-
Influx 优化型
数据库实例使用优化的配置堆栈,为您的实例I/O. This optimization provides the best performance by minimizing contention between I/O和其他流量提供额外的专用容量。
-
网络带宽
与其他数据库实例类有关的网络速度。在下表中,可以找到有关适用于 InfluxDB 的 Amazon Timestream 实例类的硬件详细信息。
| 实例类 | vCPU | 内存(GiB) | 存储类型 | 网络带宽(Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | 已包含 Influx IOPS | 10 |
| db.influx.large | 2 | 16 | 已包含 Influx IOPS | 10 |
| db.influx.xlarge | 4 | 32 | 已包含 Influx IOPS | 10 |
| db.influx.2xlarge | 8 | 64 | 已包含 Influx IOPS | 10 |
| db.influx.4xlarge | 16 | 128 | 已包含 Influx IOPS | 10 |
| db.influx.8xlarge | 32 | 256 | 已包含 Influx IOPS | 12 |
| db.influx.12xlarge | 48 | 384 | 已包含 Influx IOPS | 20 |
| db.influx.16xlarge | 64 | 512 | 已包含 Influx IOPS | 25 |
| db.influx.24xlarge | 96 | 768 | 已包含 Influx IOPS | 40 |
InfluxDB 实例存储
适用于 InfluxDB 的 Amazon Timestream 的数据库实例使用已包含 Influx IOPS 的卷,以存储数据库和日志。
在某些情况下,您的数据库工作负载可能无法 100% 实现您预调配的 IOPS。有关更多信息,请参阅影响存储性能的因素。有关适用于 InfluxDB 的 Timestream 存储定价的更多信息,请参阅 Amazon Timestream 定价
适用于 InfluxDB 的 Amazon Timestream 存储类型
适用于 InfluxDB 的 Amazon Timestream 支持一种存储类型,已包含 Influx IOPS。您可以创建最多支持 16 太字节(TiB)存储空间的适用于 InfluxDB 的 Timestream 实例。
以下是对可用存储类型的简要说明:
-
Influx IO 包含存储:存储性能是每秒 I/O 操作数 (IOPS) 和存储卷执行读取和写入的速度(存储吞吐量)的组合。在已包含 Influx IOPS 的存储卷上,适用于 InfluxDB 的 Amazon Timestream 提供 3 个存储层,这些存储层已预置不同类型工作负载所需的最佳 IOPS 和吞吐量。
InfluxDB 实例大小调整
适用于 InfluxDB 的 Timestream 实例的最佳配置取决于多种因素,包括摄取速率、批处理大小、时间序列基数、并发查询以及查询类型。为提供大小调整建议,请考虑具有以下特征的示例性工作负载:
-
数据由 Telegraf 代理实例集收集和写入,这些代理从数据中心收集系统、CPU、内存、磁盘、IO 等。
每个写入请求包含 5000 行。
-
在系统上执行的查询被归类为“中等复杂度”查询,具有以下特征:
-
这些查询具有多个函数和一两个正则表达式
-
这些查询可能包括按子句分组或时间范围为数周的样本。
-
这些查询通常需要几百毫秒到几千毫秒才能执行。
-
CPU 主要有利于查询性能。
-
| 最大系列数量 | 写入(每秒行数) | 读取(每秒查询数) | 实例类 | 存储类型 |
|---|---|---|---|---|
| <100K | ~50000 | <10 | db.influx.large | 已包含 3K 的 Influx IO |
| <1MM | ~150000 | <25 | db.influx.2xlarge | 已包含 3K 的 Influx IO |
| ~1MM | ~200000 | ~25 | db.influx.4xlarge | 已包含 3K 的 Influx IO |
| <5MM | ~250000 | ~35 | db.influx.4xlarge | 已包含 12K 的 Influx IO |
| <10MM | ~500000 | ~50 | db.influx.8xlarge | 已包含 12K 的 Influx IO |
| ~10MM | <750000 | <100 | db.influx.12xlarge | 已包含 12K 的 Influx IO |
Amazon Web Services 区域 和可用区
Amazon 云计算资源在全球多个位置托管。这些位置由 Amazon Web Services 区域 和组成。每个 Amazon 区域都是一个独立的地理区域。每个 Amazon 区域都有多个被称为可用区的隔离位置。
注意
有关查找某个 Amazon 区域的信息,请参阅 Amazon EC2 用户指南中的区域和区域。
借助适用于 InfluxDB 的 Amazon Timestream,可将资源(如数据库实例)和数据放置在多个位置。
Amazon 运营着 state-of-the-art高度可用的数据中心。数据中心有时会发生影响托管于同一位置的所有数据库实例的可用性的故障,虽然这种故障极少发生。如果您将所有数据库实例都托管在受此类故障影响的同一个位置,则您的所有数据库实例都将不可用。
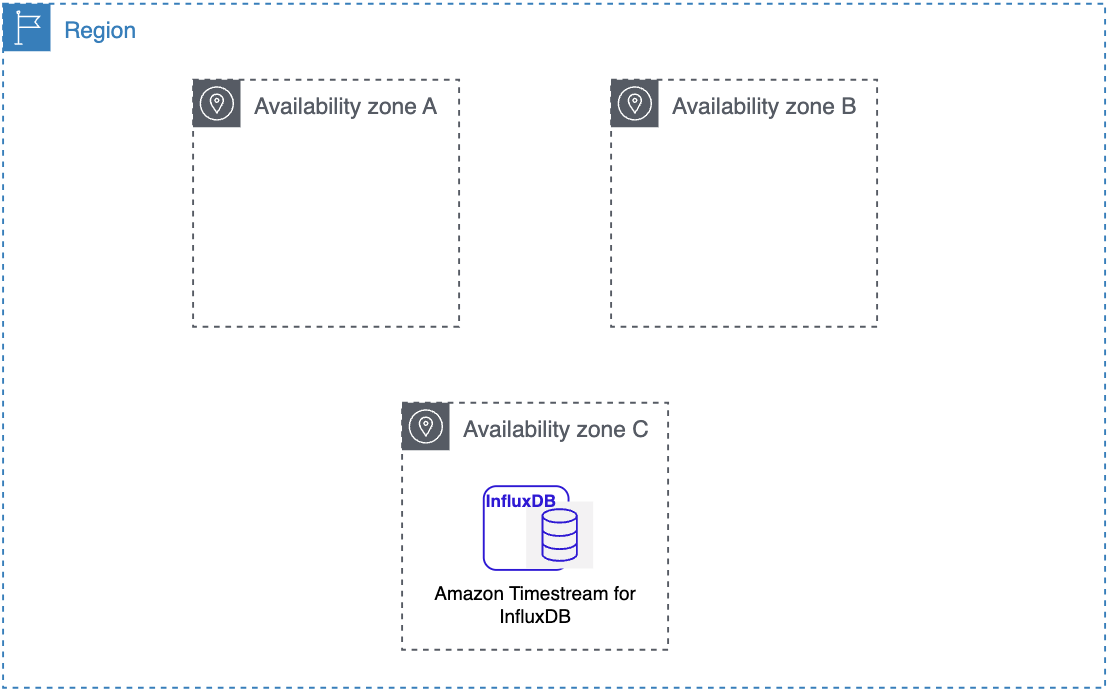
请务必记住,每个 Amazon 区域都是完全独立的。您启动的任何 Amazon Timestream for InfluxDB 活动(例如,创建数据库实例或列出可用的数据库实例)都只能在您当前的默认区域中运行。 Amazon 可以在控制台中或通过设置 AWS_DEFAULT_REGION 环境变量更改默认的 Amazon 区域。或者可以通过使用带有 Amazon Command Line Interface ()Amazon CLI的--region参数来覆盖它。有关更多信息,请参阅配置 Amazon Command Line Interface,特别是有关环境变量和命令行选项的部分。
要在特定 Amazon 区域中创建或使用适用于 InfluxDB 的 Amazon Timestream 数据库实例,请使用相应的区域服务端点。
Amazon 地区可用性
下表显示了目前提供适用于 InfluxDB 的 Amazon Timestream 的 Amazon 区域以及每个区域的终端节点。
| Amazon 区域名称 | 区域 | 端点 | 协议 |
|---|---|---|---|
| 美国东部 (弗吉尼亚北部) | us-east-1 | timestream-influxdb.us-east-1.amazonaws.com | HTTPS |
| 美国东部(俄亥俄州) | us-east-2 | timestream-influxdb.us-east-2.amazonaws.com | HTTPS |
| 美国西部(俄勒冈州) | us-west-2 | timestream-influxdb.us-west-2.amazonaws.com | HTTPS |
| 亚太地区(孟买) | ap-south-1 | timestream-influxdb.ap-south-1.amazonaws.com | HTTPS |
| 亚太地区(新加坡) | ap-southeast-1 | timestream-influxdb.ap-southeast-1.amazonaws.com | HTTPS |
| 亚太地区(悉尼) | ap-southeast-2 | timestream-influxdb.ap-southeast-2.amazonaws.com | HTTPS |
| 亚太地区(东京) | ap-northeast-1 | timestream-influxdb.ap-northeast-1.amazonaws.com | HTTPS |
| 欧洲地区(法兰克福) | eu-central-1 | timestream-influxdb.eu-central-1.amazonaws.com | HTTPS |
| 欧洲地区(爱尔兰) | eu-west-1 | timestream-influxdb.eu-west-1.amazonaws.com | HTTPS |
| 欧洲地区(斯德哥尔摩) | eu-north-1 | timestream-influxdb.eu-north-1.amazonaws.com | HTTPS |
| 加拿大(中部) | ca-central-1 | timestream-influxdb.ca-central-1.amazonaws.com | HTTPS |
| 欧洲地区(伦敦) | eu-west-2 | timestream-influxdb.eu-west-2.amazonaws.com | HTTPS |
| 欧洲地区(巴黎) | eu-west-3 | timestream-influxdb.eu-west-3.amazonaws.com | HTTPS |
| 亚太地区(雅加达) | ap-southeast-3 | timestream-influxdb.ap-southeast-3.amazonaws.com | HTTPS |
| 欧洲地区(米兰) | eu-south-1 | timestream-influxdb.eu-south-1.amazonaws.com | HTTPS |
| 欧洲(西班牙) | eu-south-2 | timestream-influxdb.eu-south-2.amazonaws.com | HTTPS |
| 中东(阿联酋): | me-central-1 | timestream-influxdb.me-central-1.amazonaws.com | HTTPS |
| 中国(北京) | cn-north-1 | timestream-influxdb.cn-north-1.on.amazonwebservices.com.cn | HTTPS |
| 中国(宁夏) | cn-northwest-1 | timestream-influxdb.cn-northwest-1.on.amazonwebservices.com.cn | HTTPS |
有关目前提供适用于 InfluxDB 的 Amazon Timestream 的 Amazon 区域以及每个区域的终端节点的更多信息,请参阅 Amazon Timestream 终端节点和配额。
Amazon 区域设计
每个 Amazon 区域都设计为与其他 Amazon 区域隔离。此设计可实现最大程度的容错能力和稳定性。
当您查看您的资源时,您只能看到与您指定的 Amazon 区域相关的资源。这是因为 Amazon 区域彼此隔离,而且我们不会自动跨 Amazon 区域复制资源。
Amazon 可用区
创建数据库实例时,适用于 InfluxDB 的 Amazon Timestream 会根据子网配置为您随机选择实例。可用区由 Amazon 区域代码和字母标识符(例如us-east-1a)表示。
使用如下所示的 describe-availability-zones Amazon EC2 命令来描述指定区域内为您的账户启用的内容。
aws ec2 describe-availability-zones --region region-name
例如,要描述在美国东部(弗吉尼亚州北部)区域(us-east-1)内为账户启用的可用区,请运行以下命令:
aws ec2 describe-availability-zones --regionus-east-1
不能为多可用区数据库部署中的主数据库实例和辅助数据库实例选择可用区。适用于 InfluxDB 的 Amazon Timestream 会随机为您选择实例。有关多可用区部署的更多信息,请参阅配置和管理多可用区部署。
适用于 InfluxDB 的 Amazon Timestream 的数据库实例计费
适用于 InfluxDB 的 Amazon Timestream 实例根据以下组件进行计费:
-
数据库实例小时数(每小时):根据数据库实例的数据库实例类,例如 db.influx.large。定价以每小时为单位列出,但账单向下计算至秒,并以十进制形式显示时间。适用于 InfluxDB 的 Amazon Timestream 使用量以 1 秒的增量进行计费,时长最少 10 分钟。有关更多信息,请参阅数据库实例类数据库实例类。
-
存储(每月每 GiB):为数据库实例预置的存储容量。有关更多信息,请参阅 InfluxDB 实例存储。
-
数据传输(每 GB)-从您的数据库实例传入和传出互联网和其他 Amazon 地区的数据。
有关适用于 InfluxDB 的 Amazon Timestream 定价信息,请参阅适用于 InfluxDB 的 Amazon Timestream 定价页面
设置适用于 InfluxDB 的 Amazon Timestream
首次使用适用于 InfluxDB 的 Amazon Timestream 之前,请完成以下任务:
如果您已经有一个 Amazon 账户,请了解您的 Amazon Timestream for InfluxDB 要求,并且更喜欢使用 IAM 和 Amazon VPC 的默认设置。开始使用适用于 InfluxDB 的 Timestream
注册一个 Amazon 账号
如果您没有 Amazon 帐户,请完成以下步骤来创建一个帐户。
要注册一个 Amazon 账户
-
转到 Amazon 登录
页面。 -
选择创建新帐户,并按照说明操作。
注意
在注册时,将接到电话,要求使用电话键盘输入一个验证码。
当你注册一个 Amazon 账户时,会创建一个 Amazon 账户 root 用户。root 用户有权访问账户中的所有 Amazon 服务和资源。作为安全最佳实践,请为管理用户分配管理访问权限,并且只使用根用户执行需要根用户访问权限的任务。
Amazon 注册过程完成后会向您发送一封确认电子邮件。您可以随时前往 https://aws.amazon.com/
User management
创建管理用户
创建管理用户
注册 Amazon 帐户后,请创建一个管理用户,这样您就不会使用 root 用户执行日常任务。
保护您的 Amazon 账户 root 用户
选择 Root 用户并输入您的账户电子邮件地址,以 Amazon 账户所有者的身份登录。 Amazon Web Services 管理控制台 在下一页上,输入您的密码。要获取使用根用户登录方面的帮助,请参阅《Amazon 登录用户指南》中的以根用户身份登录
为您的根用户启用多重身份验证(MFA)。有关说明,请参阅 I A M 用户指南中的为您的 Amazon 账户根用户(控制台)启用虚拟 MFA 设备。
授予编程访问权限
如果用户想在 Amazon 外部进行交互,则需要编程访问权限 Amazon Web Services 管理控制台。授予编程式访问权限的方法取决于访问 Amazon的用户类型。
要向用户授予编程式访问权限,请选择以下选项之一:
| 哪个用户需要编程式访问权限? | 目的 | 方式 |
|---|---|---|
| 员工身份(在 IAM Identity Center 中管理的用户) | 使用临时证书签署向 Amazon CLI 发出的编程请求 Amazon SDKs、或 Amazon APIs。 |
按照您希望使用的界面的说明进行操作。 有关信息 Amazon CLI,请参阅Amazon Command Line Interface 用户指南 Amazon CLI中的使用配置 IAM 身份中心身份验证。 有关工具和 Amazon SDKs Amazon APIs,请参阅和工具参考指南中的使用 IAM Identity Center 对 Amazon SDK Amazon SDKs 和工具进行身份验证。 |
| IAM | 使用临时证书签署向 Amazon CLI 提出的编程请求 SDKs、和 APIs。 | 按照Amazon Identity and Access Management 用户指南中的将临时证书与 Amazon 资源配合使用中的说明进行操作。 |
| IAM | (不推荐)使用长期证书签署向 Amazon CLI SDKs、和 APIs。 |
按照您希望使用的界面的说明进行操作。 有关的 Amazon CLI,请参阅用户指南 Amazon CLI中的使用 IAM 用户证书进行身份验证。Amazon Command Line Interface 有关 Amazon SDKs 和工具,请参阅Amazon SDKs 和工具参考指南中的使用长期凭证进行身份验证AmazonSDKs 和工具。 有关信息 Amazon APIs,请参阅用户指南中的管理 IAM Amazon Identity and Access Management 用户的访问密钥。 |
确定要求
适用于 InfluxDB 的 Amazon Timestream 的基本构建块是数据库实例。在数据库实例中,您可以创建存储桶。数据库实例提供称为端点的网络地址。您的应用程序使用此端点连接到您的数据库实例。您还将使用浏览器中的相同端点访问 InfluxUI。在创建数据库实例时,您指定存储、内存、数据库引擎和版本、网络配置及安全性等详细信息。您通过安全组控制对数据库实例的网络访问。
在创建数据库实例和安全组之前,您必须知道数据库实例和网络需求。下面是要考虑的一些重要事项:
-
资源要求:应用程序或服务的内存和处理器要求是什么? 您使用这些设置来帮助您确定要使用哪个数据库实例类。有关数据库实例类的规范,请参阅数据库实例类。
-
VPC 和安全组:您的数据库实例很可能在虚拟私有云(VPC)中。要连接到数据库实例,您需要设置安全组规则。根据您使用的 VPC 的类型和您使用它的方式,设置这些规则的方式有所不同。例如,您可以使用:默认 VPC 或用户定义的 VPC。
下面的列表说明每个 VPC 选项的规则:
-
默认 VPC — 如果您的 Amazon 账户在当前 Amazon 区域拥有默认 VPC,则该 VPC 已配置为支持数据库实例。如果在创建数据库实例时指定默认 VPC,请确保创建 VPC 安全组,该安全组用于授权从应用程序或服务到适用于 InfluxDB 的 Amazon Timestream 数据库实例的连接。使用 VPC 控制台或 Amazon CLI 上的安全组选项创建 VPC 安全组。有关更多信息,请参阅步骤 3:创建 VPC 安全组。
-
-
用户定义的 VPC:如果希望在创建数据库实例时指定用户定义的 VPC,请了解以下内容:
-
确保创建 VPC 安全组,该安全组用于授权从应用程序或服务到适用于 InfluxDB 的 Amazon Timestream 数据库实例的连接。使用 VPC 控制台或 Amazon CLI 上的安全组选项创建 VPC 安全组。有关信息,请参阅步骤 3:创建 VPC 安全组。
-
该 VPC 必须满足特定要求才能托管数据库实例,例如至少拥有两个子网,每个子网分别位于一个独立的可用区中。有关信息,请参阅 Amazon VPC 和适用于 InfluxDB 的 Amazon Timestream。
-
-
高可用性:是否需要失效转移支持? 在适用于 InfluxDB 的 Amazon Timestream 上,多可用区部署会创建一个主数据库实例,并在另一个可用区中创建第二个备用数据库实例,以支持失效转移。我们建议将多可用区部署用于生产工作负载以保持高可用性。对于开发和测试用途,您可以使用不是多可用区的部署。有关更多信息,请参阅 多可用区数据库实例部署。
-
IAM 政策 — 您的 Amazon 账户是否有授予执行 Amazon Timestream 对 InfluxDB 操作所需的权限的策略? 如果您 Amazon 使用 IAM 凭证进行连接,则您的 IAM 账户必须拥有 IAM 策略,这些策略授予对 InfluxDB 控制平面操作执行 Amazon Timestream 所需的权限。有关更多信息,请参阅 适用于 InfluxDB 的 Amazon Timestream 的 Identity and Access Management。
-
开放端口-您的数据库监听哪个 TCP/IP 端口? 有些公司的防火墙可能会阻止与您的数据库引擎的默认端口进行连接。适用于 InfluxDB 的 Timestream 的默认端口为 8086。
-
Amazon 区域-您希望您的数据库位于哪个 Amazon 区域? 通过让数据库紧邻应用程序或 Web 服务,可以减小网络延迟。有关更多信息,请参阅Amazon Web Services 区域 和可用区 。
-
数据库磁盘子系统:您的存储要求是什么? 适用于 InfluxDB 的 Amazon Timestream 为其提供三种配置,已包含 Influx IOPS 的存储类型:
-
已包含 3k IOPS 的 Influx Io(SSD)
-
已包含 12k IOPS 的 Influx Io(SSD)
-
已包含 16k IOPS 的 Influx Io(SSD)
有关适用于 InfluxDB 的 Amazon Timestream 存储的更多信息,请参阅适用于 InfluxDB 的 Amazon Timestream 数据库实例存储。在了解创建安全组和数据库实例所需的信息之后,请继续执行下一步。
-
通过创建安全组提供对 VPC 中的数据库实例的访问
VPC 安全组提供了对 VPC 中的数据库实例的访问权。它们充当关联数据库实例的防火墙,在数据库实例级别控制入站和出站流量。默认情况下,系统将创建带防火墙和默认安全组 (用于保护数据库实例) 的数据库实例。
在连接到数据库实例之前,必须先向允许连接的安全组添加规则。使用网络和配置信息来创建允许访问数据库实例的规则。
例如,假设您有一个访问 VPC 中的数据库实例上的数据库的应用程序。在这种情况下,您必须添加指定应用程序用于访问数据库的端口范围和 IP 地址的自定义 TCP 规则。如果您在 Amazon EC2 实例上有应用程序,则可以使用为该亚马逊 EC2实例设置的安全组。
为 VPC 访问创建安全组
要创建 VPC 安全组,请登录 Amazon Web Services 管理控制台 并选择 VPC。
注意
确保位于 VPC 控制台中,而不是适用于 InfluxDB 的 Amazon Timesteam 控制台。
-
在的右上角 Amazon Web Services 管理控制台,选择要在其中创建 VPC 安全组和数据库实例的Amazon 区域。在该 Amazon 区域的 Amazon VPC 资源列表中,您应该至少看到一个 VPC 和几个子网。如果没有,则 Amazon 该区域就没有默认 VPC。 。
-
在导航窗格中,选择 Security Groups(安全组)。
-
选择 Create security group(创建安全组)。
-
在安全组页面的基本详细信息部分,输入安全组名称及描述。对于 VPC,选择要在其中创建数据库实例的 VPC。
-
在入站规则中,请选择添加规则。
-
对于类型,选择自定义 TCP。
-
对于源,选择安全组名称或输入从中访问数据库实例的 IP 地址范围(CIDR 值)。如果您选择我的 IP,这会允许从浏览器中检测到的 IP 地址访问数据库实例。
对于源,选择安全组名称或键入您从中访问数据库实例的 IP 地址范围(CIDR 值)。如果您选择我的 IP,这会允许从浏览器中检测到的 IP 地址访问数据库实例。
-
-
(可选)在出站规则中,为出站流量添加规则。默认情况下,允许所有出站流量。
-
选择创建安全组。
创建数据库实例时,可使用此 VPC 安全组作为数据库实例的安全组。
注意
如果使用默认 VPC,则为您创建跨越该 VPC 所有子网的默认子网组。创建数据库实例时,可选择默认 eiifccntf VPC,并为数据库子网组选择默认。
完成所需的设置后,可以使用您的要求和安全组来创建数据库实例。为此,请遵循创建数据库实例中的说明。
适用于 InfluxDB 的 Timestream 安全最佳实践
优化对 InfluxDB 的写入
与其他任何时间序列数据库一样,InfluxDB 旨在能够实时摄取和处理数据。为使系统保持最佳性能,建议在向 InfluxDB 写入数据时进行以下优化:
批量写入:向 InfluxDB 写入数据时,请采用批量写入方式,以最大限度降低每次写入请求相关的网络开销。每个写入请求的最佳批量大小为 5000 行的行协议。要在单个请求中写入多行数据,行协议中的每行必须以换行符(\n)进行分隔。
按键对标签进行排序:在将数据点写入 InfluxDB 之前,根据字典顺序按键对标签进行排序。
measurement,tagC=therefore,tagE=am,tagA=i,tagD=i,tagB=think fieldKey=fieldValue 1562020262 # Optimized line protocol example with tags sorted by key measurement,tagA=i,tagB=think,tagC=therefore,tagD=i,tagE=am fieldKey=fieldValue 1562020262使用尽可能粗略的时间精度:InfluxDB 以纳秒精度写入数据,但如果您的数据并非以纳秒为单位进行采集,则无需以该精度写入。为获得更佳性能,请为时间戳使用尽可能粗略的精度。在以下情况下,可指定写入精度:
使用 SDK WritePrecision 时,您可以指定何时设置点的时间属性。有关 InfluxDB 客户端库的更多信息,请参阅 InfluxDB 文档
。 使用 Telegraf 时,可在 Telegraf 代理配置中配置时间精度。精度以整数 + 单位的形式表示为间隔(例如 0s、10ms、2us、4s)。有效的时间单位为“ns”、“us”、“ms”和“s”。
[agent] interval ="10s" metric_batch_size="5000" precision = "0s"
使用 gzip 压缩:使用 gzip 压缩,以加快写入 InfluxDB 的速度并减少网络带宽。基准测试显示,数据压缩后速度最高可提升 5 倍。
使用 Telegraf 时,需在 telegraf.conf 的 Influxdb_v2 输出插件配置中,将 content_encoding 选项设置为 gzip:
[[outputs.influxdb_v2]] urls = ["http://localhost:8086"] # ... content_encoding = "gzip"使用客户端库时,每个 InfluxDB 客户端库
都提供用于压缩写入请求的选项,或默认强制执行压缩。启用压缩的方法因库而异。有关具体说明,请参阅 InfluxDB 文档 使用 InfluxDB API
/api/v2/write端点写入数据时,请使用 gzip 压缩数据,并将 Content-Encoding 标头设置为 gzip。
性能设计
设计架构,以实现更简单、更高效的查询。以下准则将确保您的架构易于查询并最大限度提升查询性能:
控制时间序列基数:高基数是导致 InfluxDB 写入和读取性能下降的主要原因之一。在 InfluxDB 的上下文中,高基数是指存在大量唯一标签值。在 InfluxDB 中对标签值进行索引,这意味着大量唯一值将生成更大的索引,从而降低数据摄取和查询性能。
为深入理解并解决潜在的高基数相关问题,可按照以下步骤操作:
了解高基数的原因
测量存储桶的基数
采取措施以解决高基数问题
高序列基数的原因:InfluxDB 基于测量值和标签对数据进行索引,从而加快数据读取速度。每组已进行索引的数据元素构成一个系列键
。包含高度可变的信息(例如唯一值 IDs、哈希值和随机字符串)的@@ 标签 会导致大量序列 ,也称为高序列基 数。高序列基数是 InfluxDB 中高内存使用率的主要驱动因素。 测量序列基数:如果在适用于 InfluxDB 的 Timestream 实例中遇到性能下降或内存使用量持续攀升的情况,建议测量存储桶的序列基数。
InfluxDB 提供可在 Flux 和 InfluxQL 中测量序列基数得函数。
在 Flux 中使用函数
influxdb.cardinality()在 FluxQL 中使用
SHOW SERIES CARDINALITY命令
在这两种情况下,引擎都会返回数据中的唯一序列键数量。请注意,不建议在任何适用于 InfluxDB 的 Timestream 实例中配置超过 1000 万个序列键。
高序列基数的原因:如果发现任何存储桶存在高基数问题,可采取以下纠正措施进行修复:
查看标签:确保工作负载不会生成大多数条目标签具有唯一值的情况。如果唯一标签值的数量总是随时间的推移而增加,或者日志类型的消息被写入数据库,其中每条消息都有时间戳、标签等的唯一组合,则可能会发生这种情况。可使用以下 Flux 代码,以帮助确定哪些标签对高基数问题影响最大:
// Count unique values for each tag in a bucketimport "influxdata/influxdb/schema" cardinalityByTag = (bucket) => schema.tagKeys(bucket: bucket) |> map( fn: (r) => ({ tag: r._value, _value: if contains(set: ["_stop", "_start"], value: r._value) then 0 else (schema.tagValues(bucket: bucket, tag: r._value) |> count() |> findRecord(fn: (key) => true, idx: 0))._value, }), ) |> group(columns: ["tag"]) |> sum() cardinalityByTag(bucket: "amzn-s3-demo-bucket")如果遇到非常高的基数,则上述查询可能会超时。如果遇到超时,请依次运行以下查询。
生成标签列表:
// Generate a list of tagsimport "influxdata/influxdb/schema" schema.tagKeys(bucket: "amzn-s3-demo-bucket")计算每个标签的唯一标签值:
// Run the following for each tag to count the number of unique tag valuesimport "influxdata/influxdb/schema" tag = "example-tag-key" schema.tagValues(bucket: "amzn-s3-demo-bucket1", tag: tag) |> count()我们建议您在不同的时间点运行这些查询,以确定哪个标签的增长速度更快。
改进架构:遵循 适用于 InfluxDB 的 Timestream 安全最佳实践 中讨论的建模建议。
移除或聚合旧数据以降低基数:考虑使用案例是否需要所有导致高基数问题的数据。如果不再需要这些数据或不经常访问这些数据,可将其聚合、删除或导出至其他引擎(如适用于 LiveAnalytics 的Timestream),以实现长期存储与分析。