要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用适用于 InfluxDB 的 Amazon Timestream 的多可用区只读副本集群
只读副本集群部署是适用于 InfluxDB 的 Amazon Timestream 的一种异步部署模式,允许您配置连接到主数据库实例的只读副本。只读副本集群包含一个写入器数据库实例和一个读取器数据库实例,位于同一 Amazon Web Services 区域的不同可用区。与多可用区数据库实例部署相比,只读副本集群可提供高可用性以及增加读取工作负载容量。
只读副本集群的实例类可用性
只读副本集群部署支持与常规适用于 InfluxDB 的 Timestream 实例相同的实例类型。
| 实例类 | vCPU | 内存(GiB) | 存储类型 | 网络带宽(Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | 已包含 Influx IOPS | 10 |
| db.influx.large | 2 | 16 | 已包含 Influx IOPS | 10 |
| db.influx.xlarge | 4 | 32 | 已包含 Influx IOPS | 10 |
| db.influx.2xlarge | 8 | 64 | 已包含 Influx IOPS | 10 |
| db.influx.4xlarge | 16 | 128 | 已包含 Influx IOPS | 10 |
| db.influx.8xlarge | 32 | 256 | 已包含 Influx IOPS | 12 |
| db.influx.12xlarge | 48 | 384 | 已包含 Influx IOPS | 20 |
| db.influx.16xlarge | 64 | 512 | 已包含 Influx IOPS | 25 |
| db.influx.24xlarge | 96 | 768 | 已包含 Influx IOPS | 40 |
只读副本集群架构
对于只读副本集群,适用于 InfluxDB 的 Amazon Timestream 会使用 InfluxData许可的只读副本插件自动将写入器数据库实例的所有写入复制到所有读取器数据库实例。此复制为异步复制,所有写入操作在写入节点提交后立即得到确认。写入操作无需获得所有读取器节点的确认即可视为成功写入。写入器数据库实例提交数据后,几乎可以立即将数据复制到只读副本实例。如果写入器出现无法恢复的故障,则任何还未复制到至少一个读取器的数据都将丢失。
只读副本实例是写入器数据库实例的只读副本。您可以将从应用程序发出的部分或全部查询路由到只读副本,以减轻写入器数据库实例上的负载。通过这种方法,可以实现弹性横向扩展并超越单个数据库实例的容量限制,以处理读取密集型数据库工作负载。
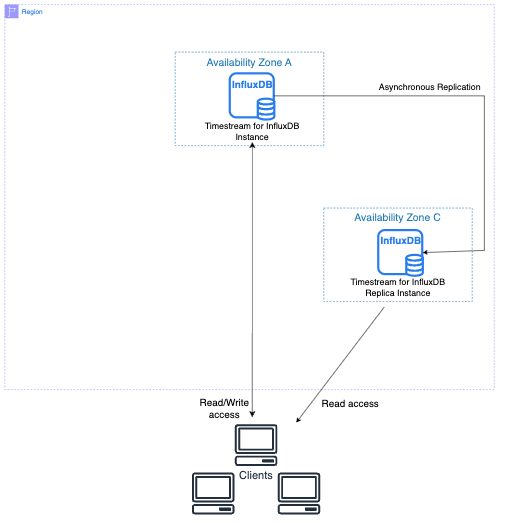
下图显示主数据库实例正在复制到不同可用区中的只读副本。客户端可以 read/write 访问主数据库实例,也可以对副本进行只读访问。
只读副本集群的参数组
在只读副本集群中,数据库集群参数组充当引擎配置值的容器,这些值可应用于只读副本集群中的每个数据库实例。默认数据库参数组基于数据库引擎和数据库引擎版本进行设置。数据库参数组中的设置用于集群中的所有数据库实例。
使用CreateDbCluster或UpdateDbCluster为多可用区数据库只读副本传递特定的数据库参数组时,请确保将持续时间设置storage-wal-max-write-delay为最少 1 小时。如果未指定数据库参数组,storage-wal-max-write-delay 默认为 1 小时。
只读副本集群中的副本滞后
尽管适用于 InfluxDB 的 Timestream 只读副本集群允许高写入性能,但基于引擎的异步复制的性质仍可能导致副本滞后。这种滞后可能导致失效转移时出现潜在数据丢失,因此必须进行监控。
您可以 CloudWatch 通过在 Amazon Web Services 管理控制台 导航窗格中选择所有指标来跟踪副本延迟。选择 timeStream/InfluxD B,然后选择 By。 DbCluster选择你的 DbClusterName,然后选择你的DbReaderInstanceName。在这里,除了为InfluxDB实例的所有Timestream跟踪的常规指标集(参见下面的列表)外,您还将看到 ReplicaLag以毫秒为单位表示的指标。
CPUUtilization
MemoryUtilization
DiskUtilization
ReplicaLag (仅适用于副本实例模式的数据库实例)
副本滞后的常见原因
一般来说,写入工作负载和读取工作负载过高时,导致读取器数据库实例无法有效应用事务时,就会出现副本滞后。各种工作负载都可能会产生临时或持续副本滞后。以下是一些常见示例:
写入器数据库实例的高写入并发或大量批处理更新,导致读取器数据库实例上的应用过程落后。
在一个或多个读取器数据库实例上使用资源的繁重的读取工作负载。运行速度慢或查询数量多都可能会影响应用进程,继而导致副本滞后。
由于数据库必须保留提交顺序,因此修改大量数据或 DDL 语句的事务有时会暂时加剧副本滞后问题。
有关介绍如何在副本延迟超过设定时间时创建 CloudWatch 警报的教程,请参阅教程:针对适用于 InfluxD CloudWatch B 的亚马逊 Timestream 的多可用区集群副本延迟创建亚马逊警报。
缓解副本滞后问题
对于适用于 InfluxDB 的 Timestream 只读副本集群,可通过减少写入器数据库实例的负载以缓解副本滞后问题。
可用性与持久性
只读副本集群可配置为:在写入器故障时自动切换至其中一个读取器实例以优先保障写入可用性,或避免切换以最大限度减少提示数据丢失。提示数据是指尚未复制到至少一个读取器节点的数据复制间隙(请参阅只读副本集群中的副本滞后)。只读副本集群的默认和推荐行为是在写入器发生故障时自动进行故障转移。然而,如果对于您的使用案例,提示数据丢失比写入可用性更为重要,则可通过更新集群覆盖默认值。
只读副本集群确保集群的所有数据库实例分布在至少两个可用区中,从而在可用区发生故障时提升写入可用性并增强数据持久性。