本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
作为副本集连接到 Amazon DocumentDB
在针对 Amazon DocumentDB(与 MongoDB 兼容)进行开发时,我们建议您以副本集形式连接到集群,并使用驱动程序的内置读取首选项功能将读取操作分布到副本实例。本节将更深入地探讨其含义,并介绍如何使用适用于 Python 的软件开发工具包作为副本集连接到您的 Amazon DocumentDB 集群。
Amazon DocumentDB 有三个可用于连接集群的端点:
-
集群端点
-
读取器端点
-
实例端点
在大多数情况下,当您连接到 Amazon DocumentDB 时,我们建议使用集群端点。这是指向集群中主实例的 CNAME,如下图所示。
使用 SSH 隧道时,我们建议您使用集群端点连接到集群,而不要尝试以副本集模式(即在连接字符串中指定 replicaSet=rs0)进行连接,因为这会导致错误。
注意
有关 Amazon DocumentDB 网站端点的更多信息,请参阅 Amazon DocumentDB 端点。
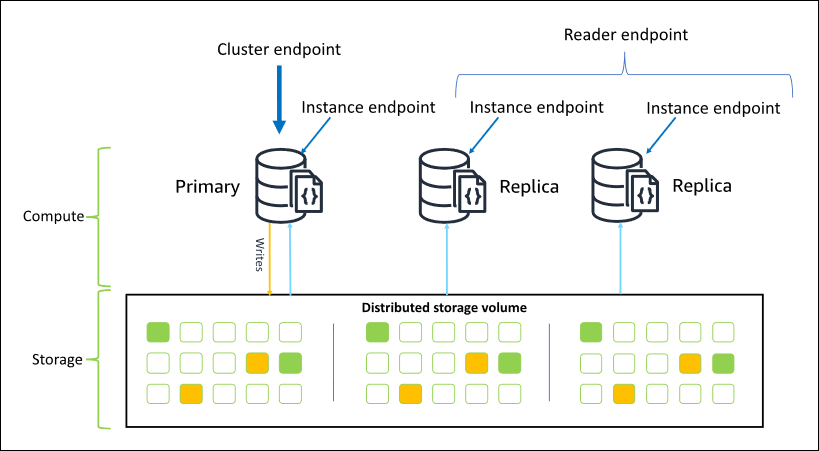
使用集群端点,可以以副本集模式连接到您的集群。然后,您可以使用内置的读取首选项驱动程序功能。在以下示例中,指定 /?replicaSet=rs0 表示要作为副本集连接到软件开发工具包。如果省略 /?replicaSet=rs0',则客户端会将所有请求路由到集群端点,即您的主实例。
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
作为副本集连接的优势在于,它使您的软件开发工具包能够自动发现集群地形,包括何时在集群中增加或移除实例。然后,您可以通过将读取请求路由到副本实例,从而更高效地使用集群。
作为副本集连接时,可以指定连接的 readPreference。如果您将读取首选项指定为 secondaryPreferred,则客户端会将读取查询路由到您的副本,并将写入查询路由到您的主实例(如下图所示)。这样可以更好地利用您的集群资源。有关更多信息,请参阅 读取首选项选项。
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
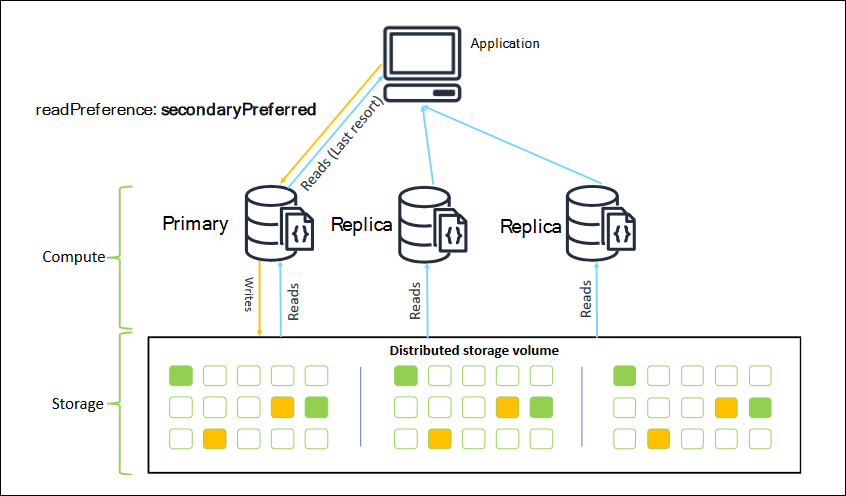
从 Amazon DocumentDB 副本中读取的内容具有最终一致性。它们返回数据的顺序与在主实例上写入数据的顺序相同,而且复制延迟时间通常不到 50 毫秒。您可以使用 Amazon CloudWatch 指标 DBInstanceReplicaLag 和 DBClusterReplicaLagMaximum 监控集群的副本延迟。有关更多信息,请参阅 使用以下方式监控亚马逊 DocumentDB CloudWatch。
与传统的单体数据库架构不同,Amazon DocumentDB 将存储和计算分离开来。鉴于这种现代架构,我们鼓励您在副本实例上进行读取扩展。对副本实例的读取不会阻止从主实例复制写入。您可以在集群中增加多达 15 个只读副本实例,并横向扩展到每秒数百万次读取。
作为副本集连接并将读取分配给副本的主要好处是,它增加了集群中可用于应用程序工作的总体资源。作为最佳实践,我们建议以副本集的形式进行连接。此外,我们最常建议在以下情况下使用它:
-
您在主实例上使用了将近 100% 的 CPU。
-
缓冲区缓存命中率接近零。
-
您已达到单个实例的连接或光标限制。
扩展集群实例大小是一种选择,在某些情况下,这可能是纵向扩展集群的最佳方式。但是,您也应该考虑如何更好地使用集群中已有的副本。这使您可以扩展规模,而不会因为使用更大的实例类型而增加成本。我们还建议您使用 CloudWatch 警报监控这些限制(即 CPUUtilization、DatabaseConnections、和 BufferCacheHitRatio)并发出警报,以便知道资源何时被大量使用。
有关更多信息,请参阅以下主题:
使用集群连接
请考虑使用集群中所有连接的情况。例如,r5.2xlarge 实例的连接数限制为 4,500(以及 450 个打开的游标)。如果您创建了三个实例的 Amazon DocumentDB 集群,并且只使用集群端点连接到主实例,则打开的连接和游标的集群限制分别为 4,500 和 450。如果您正在构建的应用程序要使用许多在容器中启动的工作程序,那么可能会达到这些限制。容器同时打开多个连接并使集群饱和。
相反,您可以作为副本集连接到您的 Amazon DocumentDB 集群,并将读取分配给副本实例。然后,您可以有效地将集群中可用连接和光标数量增加三倍,分别达到 13,500 和 1,350。向集群增加更多实例只会增加读取工作负载的连接和光标数量。如果您需要增加写入集群的连接数量,我们建议您增加实例大小。
注意
large、xlarge、和 2xlarge 实例的连接数随实例大小上升到 4,500 而增加。对于 4xlarge 或更大的实例,每个实例的最大连接数为 4,500。有关不同实例类型限制的更多信息,请参阅 实例限制。
一般而言,我们不建议使用 secondary 的读取首选项连接到集群。这是因为如果您的集群中没有副本实例,则会读取失败。例如,假设您具有一个具有两个实例的 Amazon DocumentDB 集群,它具有一个主集和一个副本。如果副本出现问题,则从设置为 secondary 失败的连接池中读取请求。secondaryPreferred 的优点在于,如果客户端找不到合适的副本实例进行连接,则它会回退到主实例进行读取。
多个连接池
在某些情况下,应用程序中的读取需要具有先写后读的一致性,这只能从 Amazon DocumentDB 的主实例提供。在这些情况下,您可以创建两个客户端连接池:一个用于写入,另一个用于需要先写后读一致性的读取。为此,您的代码如下所示。
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
另一种选择是创建单个连接池,并覆盖给定集合的读取首选项。
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
摘要
为了更好地使用集群中的资源,我们建议您使用副本集模式连接到集群。如果它适合您的应用程序,则可以通过将读取分配给副本实例来扩展您的应用程序。