本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon DocumentDB:工作方式
亚马逊 DocumentDB(兼容 MongoDB)是一项完全托管的数据库服务。 MongoDB-compatible 借助 Amazon DocumentDB,您可以运行与 MongoDB 相同的应用程序代码,并使用与 MongoDB 相同的驱动程序和工具。亚马逊 DocumentDB 与 MongoDB 3.6、4.0、5.0 和 8.0 兼容。
主题
使用 Amazon DocumentDB 时,首先要创建一个集群。集群由零个或多个数据库实例以及管理这些实例的数据的集群卷组成。Amazon DocumentDB 集群卷是一个跨多个可用区的虚拟数据库存储卷。每个可用区都有一个集群数据副本。
一个 Amazon DocumentDB 集群包含两个组件:
-
集群卷:使用云原生存储服务在三个可用区中复制数据六次,从而提供高度持久且可用的存储。一个 Amazon DocumentDB 集群只有一个集群卷,最多可存储 128 TiB 数据。
-
实例:提供数据库处理能力,以及向集群存储卷写入数据和从中读取数据的能力。一个 Amazon DocumentDB 集群可以有 0–16 个实例。
实例具有以下两种角色之一:
-
主实例:支持读写操作,并对集群卷执行所有数据修改。每个 Amazon DocumentDB 集群都有一个主实例。
-
副本实例:仅支持读取操作。除主实例之外,每个 Amazon DocumentDB 集群最多可拥有 15 个副本。拥有多个副本使您可以分配读取工作负载。此外,通过将副本置于单独的可用区中,您还可以提高集群可用性。
下图说明了 Amazon DocumentDB 集群中的集群卷、主实例和副本之间的关系:
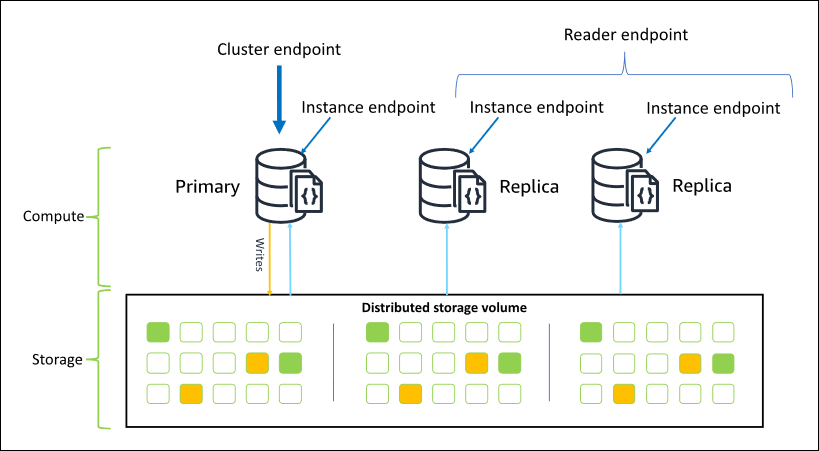
集群实例无需为相同的实例类,可以根据需要预置和终止它们。此体系结构允许您独立于集群的存储扩展集群的计算容量。
当您的应用程序将数据写入主实例时,主实例会执行对集群卷的持久写入。然后,它将这个写入的状态(而非数据)复制到每个活动副本。Amazon DocumentDB 副本不参与处理写入,因此 Amazon DocumentDB 副本有利于读取扩展。来自 Amazon DocumentDB 副本的读取最终具有一致性,且副本滞后时间最短:通常少于主实例写入更新后的 100 毫秒。保证按照将数据写入主实例的顺序读取副本中的数据。副本滞后取决于数据更改的速率,高写入活动的时间段可能会增加副本滞后。有关更多信息,请参阅Amazon DocumentDB 指标中的 ReplicationLag 指标。
Amazon DocumentDB 端点
Amazon DocumentDB 提供多种连接选项,以便为各种使用案例提供服务。要连接到 Amazon DocumentDB 集群中的实例,您需要指定实例的端点。终端节点 是主机地址和端口号,用冒号分隔。
我们建议您使用集群终端节点以副本集模式(请参阅 作为副本集连接到 Amazon DocumentDB)连接到集群,除非您有用于连接读取器终端节点或实例终端节点的特定使用案例。要将请求路由到您的副本,请选择一项驱动程序读取首选项设置,以便在满足应用程序的读取一致性要求的同时,最大程度地提高读取扩展能力。secondaryPreferred 读取首选项将启用副本读取,并释放主实例以执行更多工作。
可从 Amazon DocumentDB 集群使用以下端点。
集群端点
集群终端节点 连接到集群的当前主实例。集群终端节点可用于读写操作。一个Amazon DocumentDB 集群只有一个集群端点。
集群终端节点为集群的读取/写入连接提供故障转移支持。如果集群的当前主实例失败并且您的集群至少有一个活动的只读副本,则集群终端节点会自动将连接请求重定向到新的主实例。在连接到 Amazon DocumentDB 集群时,我们建议您使用集群端点并以副本集模式(请参阅 作为副本集连接到 Amazon DocumentDB)连接到您的集群。
以下是示例 Amazon DocumentDB 集群端点:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
以下是使用此集群终端节点的示例连接字符串:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
有关查找集群终端节点的信息,请参阅查找集群的端点。
读取器端点
读取器终端节点 跨集群中的所有可用副本对只读连接进行负载平衡。如果通过 replicaSet 模式进行连接,则集群读取器端点将以集群端点发挥作用,这意味着在连接字符串中,副本集参数为 &replicaSet=rs0。在这种情况下,可以在主实例上执行写入操作。但是,如果连接指定 directConnection=true 的集群,则尝试通过与读取器端点的连接执行写入操作会导致错误。一个 Amazon DocumentDB 集群只有一个读取器端点。
如果集群只包含一个(主)实例,则读取器终端节点将连接到该主实例。将副本实例添加到 Amazon DocumentDB 集群时,读取器端点会在新副本处于活动状态后打开与新副本的只读连接。
以下是 Amazon DocumentDB 集群的示例读取器端点:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
以下是使用读取器终端节点的示例连接字符串:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
读取器终端节点对只读连接而不是读取请求进行负载平衡。如果某些读取器终端节点连接的使用频率高于其他连接,则读取请求可能无法在集群实例之间以相同方式取得平衡。建议以副本集形式连接到集群终端节点并利用 secondaryPreferred 读取首选项来分发请求。
有关查找集群终端节点的信息,请参阅查找集群的端点。
实例端点
实例终端节点 连接到集群中的特定实例。当前主实例的实例终端节点可用于读取和写入操作。但是,尝试对只读副本的实例终端节点执行写入操作会导致错误。Amazon DocumentDB 集群的每个活动实例有一个实例端点。
对于可能不适合使用集群终端节点或读取器终端节点的场景,实例终端节点提供对特定实例的连接的直接控制。示例使用案例是配置周期性只读分析工作负载。您可以配置大于普通副本实例的实例,使用其实例终端节点直接连接到新的较大实例,运行分析查询,然后终止实例。使用实例终端节点可防止分析流量影响其他集群实例。
下面是 Amazon DocumentDB 集群中单个实例的示例实例端点:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
下面是使用此实例终端节点的示例连接字符串:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
注意
由于故障转移事件,实例的主要角色或副本角色可能会发生变化。您的应用程序永远不应该假设特定的实例终端节点是主实例。我们不建议连接到生产应用程序的实例终端节点。相反,我们建议您使用集群终端节点以副本集模式(请参阅 作为副本集连接到 Amazon DocumentDB)连接到您的集群。要想对实例故障转移优先级进行更高级的控制,请参阅了解 Amazon DocumentDB 集群容错能力。
有关查找集群终端节点的信息,请参阅查找实例的端点。
副本集模式
您可以通过指定副本集名称 rs0 以副本集模式连接到 Amazon DocumentDB 集群端点。在副本集模式下连接可以指定“Read Concern (读取问题)”、“Write Concern (写入问题)”和“Read Preference (读取首选项)”选项。有关更多信息,请参阅 读取一致性。
下面是以副本集模式连接的示例连接字符串:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
在副本集模式下连接时,您的 Amazon DocumentDB 集群将作为副本集显示给您的驱动程序和客户端。在 Amazon DocumentDB 集群中添加和删除的实例会自动反映在副本集配置中。
每个 Amazon DocumentDB 集群均包含一个默认名称为 rs0 的副本集。该副本集名称无法修改。
在副本集模式下连接到集群终端节点是常规用途的推荐方法。
注意
Amazon DocumentDB 集群中的所有实例都在同一 TCP 端口上侦听连接。
TLS Support
有关使用传输层安全性协议(TLS)连接到 Amazon DocumentDB 的更多详细信息,请参阅 加密传输中数据。
Amazon DocumentDB 存储
Amazon DocumentDB 数据存储在集群卷中,该集群卷是使用固态驱动器 (SSD) 的单个虚拟卷。集群卷由六个数据副本组成,可在单个 Amazon Web Services 区域的多个可用区之间自动复制。此复制有助于确保您的数据具有高持久性,减少数据丢失的可能性。它还有助于确保在故障转移期间您的集群具有更高可用性,因为您的数据副本已存在于其他可用区中。这些副本可以继续向 Amazon DocumentDB 集群中的实例提供数据请求服务。
数据存储的计费方式
随着数据量的增加,Amazon DocumentDB 会自动增加集群卷的大小。Amazon DocumentDB 集群卷可以增长到 128 TiB 的最大容量;但是,您只需为 Amazon DocumentDB 集群卷中您使用的空间付费。从 Amazon DocumentDB 4.0 开始,当移除数据(例如,通过丢弃集群或索引)时,整个分配的空间按相当的数量减少。因此,您可以通过删除不再需要的系列、索引、数据库等来减少存储费用。在 Amazon DocumentDB 版本 3.6 中,集群卷可以重复使用删除数据后释放的空间,但卷本身的大小从不会减小。因此,在版本 3.6 中,即使释放的空间被重复使用,在删除集合或索引后,您也可能不会看到存储空间的任何变化。
注意
在 Amazon DocumentDB 3.6 中,存储成本基于存储“高水位线”(在任何时间点分配给 Amazon DocumentDB 集群的最大数量)。您可以通过避免创建大量临时信息或者在移除不需要的较旧数据之前加载大量新数据的 ETL 实践来管理成本。如果从 Amazon DocumentDB 集群中删除数据导致分配大量未使用的空间,则重置高水位需要使用 mongodump 或 mongorestore 之类的工具执行逻辑数据转储和还原以转储和还原到新集群。创建和还原快照不会 减少分配的存储,因为基础存储的物理布局在还原的快照中保持不变。
注意
使用诸如mongodump和mongorestore之类的实用程序会根据正在读取和写入存储卷的数据的大小收 I/O 费。
有关亚马逊 DocumentDB 数据存储和 I/O 定价的信息,请参阅亚马逊 DocumentDB(兼容 MongoDB)定价和定价常见问题解答
Amazon DocumentDB 复制
在 Amazon DocumentDB 集群中,每个副本实例都公开一个独立的端点。这些副本终端节点提供对集群卷中数据的只读访问。它们使您能够在多个复制实例上扩展数据的读取工作负载。它们还有助于在您的 Amazon DocumentDB 集群中改进数据读取性能并提高数据可用性。Amazon DocumentDB 副本也是失效转移目标,如果您的 Amazon DocumentDB 集群的主实例失效,则迅速升级这些副本。
Amazon DocumentDB 可靠性
Amazon DocumentDB 的设计具有可靠、持久和容错的特点。(为了改进可用性,您应配置您的 Amazon DocumentDB 集群,使其在不同的可用区拥有多个副本实例。) Amazon DocumentDB 包括多种自动功能,使其成为很可靠的数据库解决方案。
存储自动修复
Amazon DocumentDB 在三个可用区中维护数据的多个副本,从而大大降低了因存储故障而丢失数据的可能性。Amazon DocumentDB 会自动检测集群卷中的故障。如果集群卷的某个区段发生故障,Amazon DocumentDB 会立即修复该区段。它使用集群卷包含的其他卷中的数据以帮助确保已修复区段中的数据是最新的。因此,Amazon DocumentDB 将避免数据丢失,并减少执行时间点还原以从实例故障恢复的需求。
自动恢复缓存预热
Amazon DocumentDB 在与数据库不同的进程中管理其页面缓存,以便页面缓存可以独立于数据库而存在。万一发生数据库故障,页面缓存仍保留在内存中。这可确保在数据库重新启动时使用最新状态对缓冲池进行预热。
崩溃恢复
Amazon DocumentDB 设计为几乎可以立即从崩溃中恢复,并继续为您的应用程序数据提供服务。Amazon DocumentDB 在并行线程上异步执行崩溃恢复,以便在发生崩溃后使数据库能够打开并几乎立即恢复使用。
资源管理
Amazon DocumentDB 保护在服务中运行关键进程(例如运行状况检查)所需的资源。为做到这点且当实例正遭遇高内存压力时,Amazon DocumentDB 将对请求节流。因此,某些操作可能排队等候内存压力消退。如果内存压力持续存在,则排队的操作可能超时。您可以使用以下 CloudWatch 指标监控是否由于内存不足而导致的服务限制操作:LowMemThrottleQueueDepth、、LowMemThrottleMaxQueueDepth、LowMemNumOperationsThrottled。LowMemNumOperationsTimedOut有关更多信息,请参阅使用监控 Amazon DocumentDB。 CloudWatch如果 LowMem CloudWatch 指标导致您的实例持续承受内存压力,我们建议您扩大实例规模,为工作负载提供额外的内存。
读取首选项选项
Amazon DocumentDB 使用云原生共享存储服务,该服务跨三个可用区复制数据六次,以提供高水平持久性。Amazon DocumentDB 不依赖将数据复制到多个实例来实现持久性。无论集群是包含单个实例还是 15 个实例,集群的数据都具有持久性。
写入持久性
Amazon DocumentDB 使用一种独特的、分布式、容错、自我修复的存储系统。该系统跨三个 Amazon 可用区复制六个数据副本 (V=6),以提供高可用性和耐久性。在写入数据时,Amazon DocumentDB 在确认写入客户端之前,确保所有写入都已在大多数节点上持久记录。如果您运行的是三节点 MongoDB 副本集,则与 Amazon DocumentDB 相比,使用写入关注 {w:3, j:true} 将提供最佳配置。
对 Amazon DocumentDB 集群的写入必须由集群的写入器实例处理。尝试写入读取器会导致错误。来自 Amazon DocumentDB 主实例的已确认写入具有持久性,无法回滚。默认情况下,Amazon DocumentDB 有高度持久性并且不支持非持久写入选项。您无法修改持久性级别(即写关注)。Amazon DocumentDB 忽略 w=anything,并且有效的是 w: 3 和 j: true。您无法减少它。
在 Amazon DocumentDB 架构中,存储与计算是分离的,因此具有单个实例的集群拥有很高的持久性。持久性在存储层处理。因此,具有单个实例和具有三个实例的 Amazon DocumentDB 集群实现了相同级别的持久性。您可以根据特定用例配置集群,同时仍为数据提供高持久性。
对 Amazon DocumentDB 集群的写入操作在单个文档中是原子操作。
Amazon DocumentDB 不支持 wtimeout 选项,并且如果指定了值,将不会返回错误。对 Amazon DocumentDB 主实例的写入操作保证不会无限期阻塞。
读取隔离
从 Amazon DocumentDB 实例读取只返回查询开始之前已持久存在的数据。读取从不返回在查询开始执行后修改的数据,即,任何情况下都不会进行脏读取。
读取一致性
从 Amazon DocumentDB 集群读取的数据具有持久性,将不会回滚。您可以通过指定请求或连接的读取首选项来修改 Amazon DocumentDB读取的读取一致性。Amazon DocumentDB 不支持非持久读取选项。
从 Amazon DocumentDB 集群的主实例读取在正常操作条件下具有强一致性,并且具有先写后读一致性。如果在写入与后续读取之间发生故障转移事件,系统可能短暂返回不具有强一致性的读取。从只读副本的所有读取最终是一致的,以相同的顺序返回数据,并且通常具有小于 100 毫秒的副本滞后。
Amazon DocumentDB 读取首选项
仅当 Amazon DocumentDB 以副本集模式从集群端点读取数据时,才支持设置读取首选项。设置读取首选项会影响 MongoDB 客户端或驱动程序将读取请求路由到 Amazon DocumentDB 集群中的实例的方式。您可以为特定查询设置读取首选项,或者作为 MongoDB 驱动程序中的常规选项。(有关如何设置读取首选项的说明,请查阅客户端或驱动程序文档。)
如果您的客户端或驱动程序未在副本集模式下连接到 Amazon DocumentDB 集群端点,则指定读取首选项的结果并不明确。
Amazon DocumentDB 不支持将标记集设置为读取首选项。
支持的读取首选项
-
primary:指定primary读取首选项有助于确保将所有读取请求路由到集群的主实例。如果主实例不可用,则读取操作将失败。primary读取首选项可产生先写后读一致性,适用于先写后读一致性优先于高可用性和读取扩展的使用案例。以下示例指定
primary读取首选项:db.example.find().readPref('primary') -
primaryPreferred:指定primaryPreferred读取首选项会在正常操作期间将读取请求路由到主实例。如果发生主实例故障转移,则客户端会将请求路由到副本。primaryPreferred读取首选项会在正常操作期间产生先写后读一致性,并在故障转移事件期间产生最终一致性读取。primaryPreferred读取首选项适用于先写后读一致性优先于读取扩展但仍需要高可用性的使用案例。以下示例指定
primaryPreferred读取首选项:db.example.find().readPref('primaryPreferred') -
secondary:指定secondary读取首选项可确保只将读取请求路由到副本,不会路由到主实例。如果集群中没有副本实例,则读取请求将失败。secondary读取首选项会产生最终一致性读取,适用于主实例写入吞吐量优先于高可用性和先写后读一致性的使用案例。以下示例指定
secondary读取首选项:db.example.find().readPref('secondary') -
secondaryPreferred:指定secondaryPreferred读取首选项可确保在一个或多个副本处于活动状态时将读取路由到只读副本。如果集群中没有活动的副本实例,则读取请求将路由到主实例。当读取由只读副本提供服务时,secondaryPreferred读取首选项会产生最终一致性读取。当读取由主实例提供服务时,它会产生先写后读一致性(禁止故障转移事件)。secondaryPreferred读取首选项适用于读取扩展和高可用性优先于先写后读一致性的使用案例。以下示例指定
secondaryPreferred读取首选项:db.example.find().readPref('secondaryPreferred') -
nearest:指定nearest读取首选项将仅基于测量的客户端与 Amazon DocumentDB 集群中所有实例之间的延迟来路由读取请求。当读取由只读副本提供服务时,nearest读取首选项会产生最终一致性读取。当读取由主实例提供服务时,它会产生先写后读一致性(禁止故障转移事件)。nearest读取首选项适用于实现尽可能低的读取延迟和高可用性优先于先写后读取一致性和读取扩展的使用案例。以下示例指定
nearest读取首选项:db.example.find().readPref('nearest')
高可用性
Amazon DocumentDB 通过将副本用作主实例的失效转移目标来支持高度可用的集群配置。如果主实例失败,则一个 Amazon DocumentDB 副本将被提升为新的主实例,且出现短暂中断,在此期间,对主实例发出的读写请求将失败,并会出现异常。
如果您的 Amazon DocumentDB 集群不包含任何副本,则会在失败期间重新创建主实例。但是,提升 Amazon DocumentDB 副本要比重新创建主实例快得多。因此,我们建议您创建一个或多个 Amazon DocumentDB 副本作为失效转移目标。
旨在用作故障转移目标的副本应与主实例具有相同的实例类。它们应在不同于主实例的可用区中进行配置。您可以控制哪些副本作为首选故障转移目标。有关配置 Amazon DocumentDB 以实现高可用性的最佳实践,请参阅 了解 Amazon DocumentDB 集群容错能力。
扩展读取
Amazon DocumentDB 副本是读取扩展的理想选择。它们完全专用于集群卷上的读取操作,即副本不处理写入。数据复制发生在集群卷中,而不是在实例之间。因此,每个副本的资源都专用于处理查询,而不是复制和写入数据。
如果您的应用程序需要更多读取容量,则可以快速向集群添加副本(通常在不到十分钟的时间内完成)。如果您的读取容量要求减少,则可以删除不需要的副本。使用 Amazon DocumentDB 副本,您只需为所需的读取容量付费。
Amazon DocumentDB 通过使用“Read Preference (读取首选项)”选项支持客户端读取扩展。有关更多信息,请参阅 Amazon DocumentDB 读取首选项。
TTL 删除
在特定时间范围内无法保证从通过后台进程实现的 TTL 索引区域中进行删除,只能尽力而为。实例大小、实例资源利用率、文档大小和总体吞吐量等因素会影响 TTL 删除的时间。
TTL 监视器每次删除您的文档都会产生 IO 成本,这将增加您的账单费用。如果吞吐量和 TTL 删除率提高,您应预计到账单费用会因 IO 使用量的增加而增多。
您在现有集合上创建 TTL 索引时,必须删除所有过期文档,之后创建该索引。当前的 TTL 实现就删除集合中一小部分文档进行优化,如果从一开始就对集合启用 TTL,则这情况是常见的,并且如果需要一次性删除大量文档,则这可能导致比所需更高的 IOPS。
如果您不想创建 TTL 索引来删除文档,您也可以根据时间将文档归入各个集合中,并在不再需要文档时将这些集合删除。例如:您可以每周创建一个集合再删除,而不产生 IO 成本。这可能比使用 TTL 索引明显更具成本效益。
可计费资源
确定应计费的 Amazon DocumentDB 资源
作为一项完全托管的数据库服务,Amazon DocumentDB 会对实例、存储 I/Os、备份和数据传输收费。有关更多信息,请参阅 Amazon DocumentDB(与 MongoDB 兼容)定价
要发现您账户中的可计费资源并可能删除这些资源,您可以使用 Amazon Web Services 管理控制台 或 Amazon CLI。
使用 Amazon Web Services 管理控制台
使用 Amazon Web Services 管理控制台,您可以发现您为给定内容预配置的 Amazon DocumentDB 集群、实例和快照。 Amazon Web Services 区域
查找集群、实例和快照
登录并打开 Amazon DocumentDB 控制台,网址为。 Amazon Web Services 管理控制台https://console.aws.amazon.com/docdb
-
要查找默认区域以外的区域中的可计费资源,请在屏幕右上角选择要搜索 Amazon Web Services 区域 的资源。
-
在导航窗格中,选择您感兴趣的应计费资源类型:Clusters (集群)、Instances (实例) 或 Snapshots (快照)。
-
右侧窗格中列出了该区域的所有已预置的集群、实例或快照。您将需要为集群、实例和快照付费。
使用 Amazon CLI
使用 Amazon CLI,您可以发现您为给定内容预配置的 Amazon DocumentDB 集群、实例和快照。 Amazon Web Services 区域
查找集群和实例
以下代码将列出指定区域的所有集群和实例。如果要在默认区域中搜索集群和实例,可以省略 --region 参数。
例
对于 Linux、macOS 或 Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
对于 Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
此操作的输出将类似于下文。
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",查找快照
以下代码将列出指定区域的所有快照。如果要在默认区域中搜索快照,可以省略 --region 参数。
对于 Linux、macOS 或 Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
对于 Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
此操作的输出将类似于下文。
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]您只需要删除 manual 快照。Automated 快照会在您删除集群时删除。
删除不需要的应计费资源
要删除集群,必须先删除集群中的所有实例。
-
要删除实例,请参阅删除 Amazon DocumentDB 实例。
重要
即使您删除集群中的实例,仍需要为与该集群关联的存储和备份用量付费。要停止所有计费,您还必须删除集群和手动快照。
-
要删除集群,请参阅删除 Amazon DocumentDB 集群。
-
要删除手动快照,请参阅删除集群快照。