本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon DocumentDB 弹性集群:工作原理
本节的主题提供有关支持 Amazon DocumentDB 弹性集群的机制和功能的信息。
Amazon DocumentDB 弹性集群分片
Amazon DocumentDB 弹性集群使用基于哈希的分片在分布式存储系统中对数据进行分区。分片(也称为分区)将大型数据集拆分为跨多个节点的小型数据集,使您能够横向扩展数据库超出垂直扩展限值。弹性集群使用 Amazon DocumentDB 中计算和存储的分离或“解耦”,使您能够相互独立地扩展。弹性集群不是通过在计算节点之间移动小块数据进行集合重新分区,而是在分布式存储系统中高效复制数据。
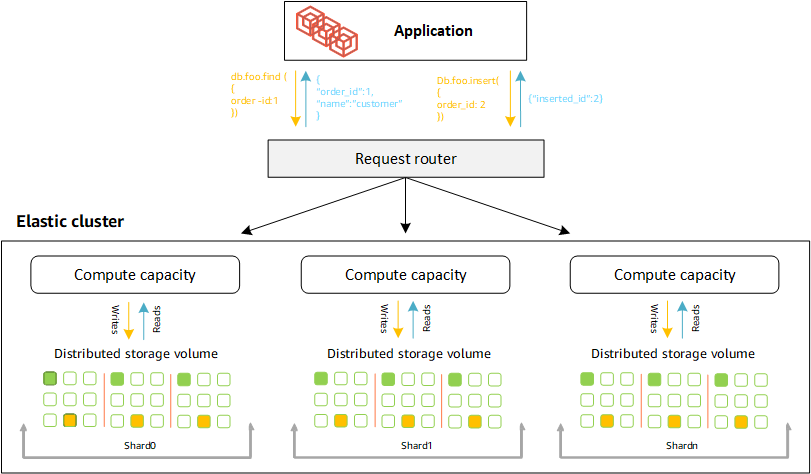
分片定义
分片命名法的定义:
分片:一个分片为弹性集群提供计算。分片将有一个写入器实例和 0 到 15 个只读副本。默认情况下,一个分片将有两个实例:一个写入器和一个只读副本。您最多可以配置 32 个分片,每个分片实例的最大值为 64 v。CPUs
分片密钥:分片密钥是已分片集合的 JSON 文档中的一个必填字段,弹性集群使用该字段向匹配的分片分配读写流量。
分片集合:分片集合是其数据跨数据分区中弹性集群分布的一个集合。
分区:分区是已分片数据的逻辑部分。创建已分片集合时,数据将根据分片密钥自动组织到每个分片内的分区中。每个分片都有多个分区。
跨已配置分片分配数据
创建具有许多唯一值的分片密钥。良好分片密钥可以将您的数据跨底层分片均匀分配,从而让您的工作负载有最佳吞吐量和性能。以下示例是使用名为“user_id”的分片密钥的员工姓名数据:
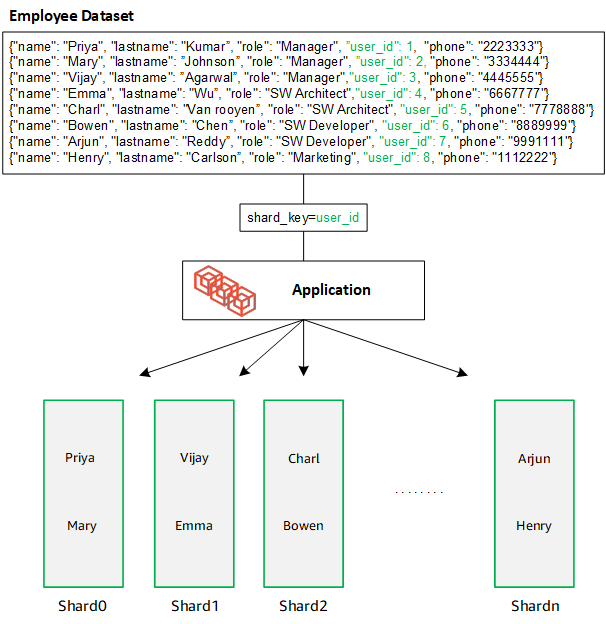
DocumentDB 使用哈希分片跨底层分片进行数据分区。其他数据按相同方式插入和分配:
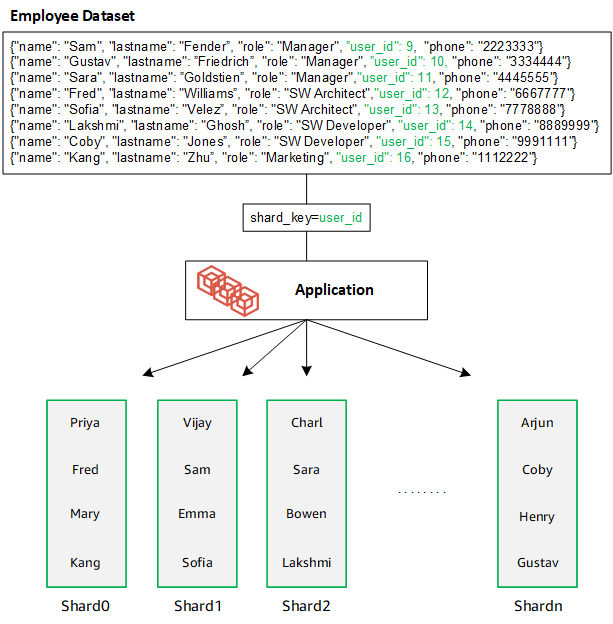
当您通过添加额外分片横向扩展数据库时,Amazon DocumentDB 会自动重新分配数据:

弹性集群迁移
Amazon DocumentDB 支持将分片的 MongoDB 数据迁移到弹性集群。支持离线、在线和混合迁移方法。有关更多信息,请参阅 迁移到 Amazon DocumentDB。
弹性集群扩展
Amazon DocumentDB 弹性集群能够增加弹性集群中的分片数量(横向扩展),以及CPUs 应用于每个分片的 v 数(向上扩展)。您还可以根据需要减少分片数量和计算容量 (vCPUs)。
有关扩展的最佳实践,请参阅 扩展弹性集群。
注意
还提供集群级的扩展。有关更多信息,请参阅 扩展 Amazon DocumentDB 集群。
弹性集群可靠性
Amazon DocumentDB 的设计具有可靠、持久和容错的特点。为提高可用性,弹性集群按每个分片部署两个节点,跨不同可用区布置。Amazon DocumentDB 包括多种自动功能,使其成为很可靠的数据库解决方案。有关更多信息,请参阅 Amazon DocumentDB 可靠性。
弹性集群存储和可用性
Amazon DocumentDB 数据存储在集群卷中,该卷是一个使用固态硬盘 () SSDs 的单个虚拟卷。一个集群卷由六个数据副本组成,这些副本会在单个 Amazon 区域的多个可用区之间自动复制。此复制有助于确保您的数据具有高持久性,减少数据丢失的可能性。它还有助于确保在故障转移期间您的集群具有更高可用性,因为您的数据副本已存在于其他可用区中。有关存储、高可用性和复制的更多详情,请参阅 Amazon DocumentDB:工作方式。
Amazon DocumentDB 4.0 与弹性集群之间的功能差异
Amazon DocumentDB 4.0 与弹性集群之间存在以下功能差异。
来自
top和collStats的结果按分片分区。对于分片集合,数据分布在多个分区之间,collStats报告了来自各分区的聚合collScans。当改变集群分片计数时,来自已分片集合的
top和collStats的集合统计数据将重置。备份内置角色现在支持
serverStatus。操作:具有备份角色的开发人员和应用程序可以收集有关 Amazon DocumentDB 集群状态的统计量。SecondaryDelaySecs字段替换replSetGetConfig输出中的slaveDelay。hello命令替换isMaster:hello返回描述弹性集群角色的一个文档。弹性集群中的
$elemMatch运算符仅匹配某数组第一个嵌套级别中的文档。在 Amazon DocumentDB 4.0 中,运算符在返回已匹配文档之前遍历所有级别。例如:
db.foo.insert( [ {a: {b: 5}}, {a: {b: [5]}}, {a: {b: [3, 7]}}, {a: [{b: 5}]}, {a: [{b: 3}, {b: 7}]}, {a: [{b: [5]}]}, {a: [{b: [3, 7]}]}, {a: [[{b: 5}]]}, {a: [[{b: 3}, {b: 7}]]}, {a: [[{b: [5]}]]}, {a: [[{b: [3, 7]}]]} ]); // Elastic clusters > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } // Docdb 4.0: traverse more than one level deep > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } { "a" : [ [ { "b" : [ 5 ] } ] ] }
Amazon DocumentDB 4.0 中的“$”投影返回带所有字段的所有文档。对于弹性集群,带“$”投影的
find命令返回匹配查询参数的文档,该参数仅含有匹配“$”投影的字段。在弹性集群中,带
$regex和$options查询参数的find命令返回一个错误:“无法同时在 $regex 和 $options 中设置选项。”
对于弹性集群,以下情况时,
$indexOfCP现在返回“-1”:未在
string expression中找到子字符串,或start是一个大于end的数字,或start是一个大于字符串字节长度的数字。
在 Amazon DocumentDB 4.0 中,当
start位置是一个大于end或字符串字符串字节长度的数字时,$indexOfCP返回“0”。对于弹性集群,
_id fields中的投影操作,例如{"_id.nestedField" : 1},返回仅包含所投影字段的文档。同时,在 Amazon DocumentDB 4.0 中,嵌套字段投影命令不会筛选掉任何文档。