Creating a headless Aurora DB cluster in a secondary Region
Although an Aurora global database requires at least one secondary Aurora DB cluster in a different Amazon Web Services Region than the primary, you can use a headless configuration for the secondary cluster. A headless secondary Aurora DB cluster is one without a DB instance. This type of configuration can lower expenses for an Aurora global database. In an Aurora DB cluster, compute and storage are decoupled. Without the DB instance, you're not charged for compute, only for storage. If it's set up correctly, a headless secondary's storage volume is kept in-sync with the primary Aurora DB cluster.
You add the secondary cluster as you normally do when creating an Aurora global database. If you are creating all the clusters in the global database, follow the procedure in Creating an Amazon Aurora global database. If you already have a DB cluster to use as the primary cluster, follow the procedure in Adding an Amazon Web Services Region to an Amazon Aurora global database.
After the primary Aurora DB cluster begins replication to the secondary, you delete the Aurora read-only DB instance from the secondary Aurora DB cluster. This secondary cluster is now considered "headless" because it no longer has a DB instance. Even without any DB instance in the secondary cluster, Aurora keeps the storage volume in sync with the primary Aurora DB cluster.
Warning
With Aurora PostgreSQL, to create a headless cluster in a secondary Amazon Web Services Region, use the Amazon CLI or RDS API to add the secondary Amazon Web Services Region. Skip the step to create the reader DB instance for the secondary cluster. Currently, creating a headless cluster isn't supported in the RDS Console. For the CLI and API procedures to use, see Adding an Amazon Web Services Region to an Amazon Aurora global database.
If your global database is using an Aurora PostgreSQL engine version lower than 13.4, 12.8, or 11.13, creating a reader DB instance in a secondary Region and subsequently deleting it could lead to an Aurora PostgreSQL vacuum issue on the primary Region's writer DB instance. If you encounter this issue, restart the primary Region's writer DB instance after you delete the secondary Region's reader DB instance.
To add a headless secondary Aurora DB cluster to your Aurora global database
Sign in to the Amazon Web Services Management Console and open the Amazon RDS console at https://console.amazonaws.cn/rds/
. -
In the navigation pane of the Amazon Web Services Management Console, choose Databases.
-
Choose the Aurora global database that needs a secondary Aurora DB cluster. Ensure that the primary Aurora DB cluster is
Available. -
For Actions, choose Add Amazon Region.
-
On the Add a region page, choose the secondary Amazon Web Services Region.
You can't choose an Amazon Web Services Region that already has a secondary Aurora DB cluster for the same Aurora global database. Also, it can't be the same Region as the primary Aurora DB cluster.
-
Complete the remaining fields for the secondary Aurora cluster in the new Amazon Web Services Region. These are the same configuration options as for any Aurora DB cluster instance.
For an Aurora MySQL–based Aurora global database, disregard the Enable read replica write forwarding option. This option has no function after you delete the reader instance.
Choose Add Amazon Region. After you finish adding the Region to your Aurora global database, you can see it in the list of Databases in the Amazon Web Services Management Console as shown in the screenshot.
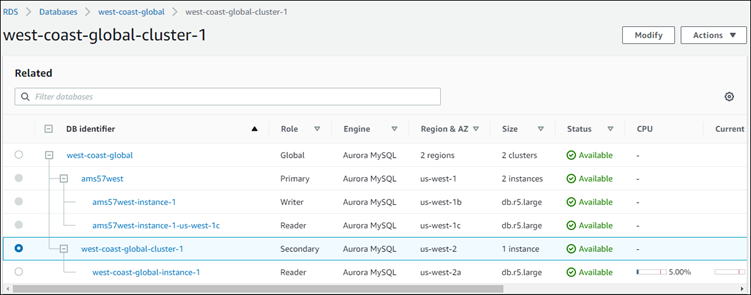
Check the status of the secondary Aurora DB cluster and its reader instance before continuing, by using the Amazon Web Services Management Console or the Amazon CLI. For example:
$aws rds describe-db-clusters --db-cluster-identifiersecondary-cluster-id--query '*[].[Status]' --output textIt can take several minutes for the status of a newly added secondary Aurora DB cluster to change from
creatingtoavailable. When the Aurora DB cluster is available, you can delete the reader instance.Select the reader instance in the secondary Aurora DB cluster, and then choose Delete.

After deleting the reader instance, the secondary cluster remains part of the Aurora global database. It has no instance associated with it, as shown following.
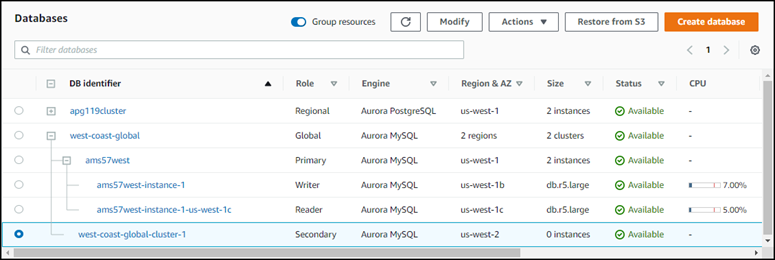
You can use this headless secondary Aurora DB cluster to manually recover your Amazon Aurora global database from an unplanned outage in the primary Amazon Web Services Region if such an outage occurs.