Using switchover or failover in Amazon Aurora Global Database
The Aurora Global Database feature provides more business continuity and disaster recovery (BCDR) protection than the standard high availability provided by an Aurora DB cluster in a single Amazon Web Services Region. By using Aurora Global Database, you can plan for faster recovery from rare, unplanned Regional disasters or complete service-level outages quickly.
You can consult the following guidance and procedures to plan, test, and implement your BCDR strategy using the Aurora Global Database feature.
Topics
Planning for business continuity and disaster recovery
To plan your business continuity and disaster recovery strategy, it's helpful to understand the following industry terminology and how those terms relate to Aurora Global Database features.
Recovery from disaster is typically driven by the following two business objectives:
-
Recovery time objective (RTO) – The time it takes a system to return to a working state after a disaster or service outage. In other words, RTO measures downtime. For Aurora Global Database, RTO can be in the order of minutes.
-
Recovery point objective (RPO) – The amount of data that can be lost (measured in time) after a disaster or service outage. This data loss is usually due to asynchronous replication lag. For an Aurora global database, RPO is typically measured in seconds. With an Aurora PostgreSQL–based global database, you can use the
rds.global_db_rpoparameter to set and track the upper bound on RPO, but doing so might affect transaction processing on the primary cluster's writer node. For more information, see Managing RPOs for Aurora PostgreSQL–based global databases.
Performing a switchover or failover with Aurora Global Database involves promoting a secondary DB cluster to be the primary DB cluster. The term "regional outage" is often used to describe a variety of failure scenarios. A worst case scenario could be a wide-spread outage from a catastrophic event that affects hundreds of square miles. However, most outages are much more localized, affecting only a small subset of cloud services or customer systems. Consider the full scope of the outage to make sure cross-Region failover is the proper solution and to choose the appropriate failover method for the situation. Whether you should use the failover or switchover approach depends on the specific outage scenario:
-
Failover – Use this approach to recover from an unplanned outage. With this approach, you perform a cross-Region failover to one of the secondary DB clusters in your Aurora global database. The RPO for this approach is typically a non-zero value measured in seconds. The amount of data loss depends on the Aurora global database replication lag across the Amazon Web Services Regions at the time of the failure. To learn more, see Recovering an Amazon Aurora global database from an unplanned outage.
-
Switchover – This operation was previously called "managed planned failover". Use this approach for controlled scenarios, such as operational maintenance and other planned operational procedures where all the Aurora clusters and other services they interact with are in a healthy state. Because this feature synchronizes secondary DB clusters with the primary before making any other changes, RPO is 0 (no data loss). To learn more, see Performing switchovers for Amazon Aurora global databases.
Note
Before you can perform a switchover or failover to a headless secondary Aurora DB cluster, you must add a DB instance to it. For more information about headless DB clusters, see Creating a headless Aurora DB cluster in a secondary Region.
Performing switchovers for Amazon Aurora global databases
Note
Switchovers were previously called managed planned failovers.
By using switchovers, you can change the Region of your primary cluster on a routine basis. This approach is intended for controlled scenarios, such as operational maintenance and other planned operational procedures.
There are three common use cases for using switchovers.
-
For "regional rotation" requirements imposed on specific industries. For example, financial service regulations might want tier-0 systems to switch to a different Region for several months to ensure that disaster recovery procedures are regularly exercised.
-
For multi-Region "follow-the-sun" applications. For example, a business might want to provide lower latency writes in different Regions based on business hours across different time zones.
-
As a zero-data-loss method to fail back to the original primary Region after a failover.
Note
Switchovers are designed to be used on a an Aurora global database where all the Aurora clusters and other services they interact with are in a healthy state. To recover from an unplanned outage, follow the appropriate procedure in Recovering an Amazon Aurora global database from an unplanned outage.
You can perform managed cross-Region switchovers with Aurora Global Database only if the primary and secondary DB clusters have the same major and minor engine versions. Depending on the engine and engine versions, the patch levels might need to be identical or the patch levels can be different. For a list of engines and engine versions that allow these operations between primary and secondary clusters with different patch levels, see Patch level compatibility for managed cross-Region switchovers and failovers. Before you begin the switchover, check the engine versions in your global cluster to make sure that they support managed cross-Region switchover, and upgrade them if needed.
During a switchover, Aurora makes the cluster in your chosen secondary Region be your primary cluster. The switchover mechanism maintains your global database's existing replication topology: it still has the same number of Aurora clusters in the same Regions. Before Aurora starts the switchover process, it waits for the target secondary Region clusters to be fully synchronized with the primary Region cluster. Then, the DB cluster in the primary Region becomes read-only. The chosen secondary cluster promotes one of its read-only nodes to full writer status, which allows that secondary cluster to assume the role of primary cluster. Because the target secondary cluster was synchronized with the primary at the beginning of the process, the new primary continues operations for the Aurora global database without losing any data. Your database is unavailable for a short time while the primary and selected secondary clusters are assuming their new roles.
Note
To manage replication slots for Aurora PostgreSQL after performing a switchover, see Managing logical slots for Aurora PostgreSQL.
To optimize application availability, we recommend that you do the following before using this feature:
-
Perform this operation during nonpeak hours or at another time when writes to the primary DB cluster are minimal.
-
Check lag times for all secondary Aurora DB clusters in the Aurora global database. For all Aurora PostgreSQL-based global databases and for Aurora MySQL-based global databases starting with engine versions 3.04.0 and higher or 2.12.0 and higher, use Amazon CloudWatch to view the
AuroraGlobalDBRPOLagmetric for all secondary DB clusters. For lower minor versions of Aurora MySQL-based global databases, view theAuroraGlobalDBReplicationLagmetric instead. These metrics show you how far behind (in milliseconds) replication to a secondary cluster is to the primary DB cluster. This value is directly proportional to the time it takes for Aurora to complete the switchover. Therefore, the larger the lag value, the longer the switchover will take. When you examine these metrics, do so from the current primary cluster.For more information about CloudWatch metrics for Aurora, see Cluster-level metrics for Amazon Aurora.
-
The secondary DB cluster that's promoted during a switchover might have different configuration settings than the old primary DB cluster. We recommend that you keep the following types of configuration settings consistent across all the clusters in your Aurora global database clusters. Doing so helps to minimize performance issues, workload incompatibilities, and other anomalous behavior after a switchover.
-
Configure Aurora DB cluster parameter group for the new primary, if necessary – When you promote a secondary DB cluster to take over the primary role, the parameter group from the secondary might be configured differently than for the primary. If so, modify the promoted secondary DB cluster's parameter group to conform to your primary cluster's settings. To learn how, see Modifying parameters for an Aurora global database.
-
Configure monitoring tools and options, such as Amazon CloudWatch Events and alarms – Configure the promoted DB cluster with the same logging ability, alarms, and so on as needed for the global database. As with parameter groups, configuration for these features isn't inherited from the primary during the switchover process. Some CloudWatch metrics, such as replication lag, are only available for secondary Regions. Thus, a switchover changes how to view those metrics and set alarms on them, and could require changes to any predefined dashboards. For more information about Aurora DB clusters and monitoring, see Monitoring Amazon Aurora metrics with Amazon CloudWatch.
-
Configure integrations with other Amazon services – If your Aurora global database integrates with Amazon services, such as Amazon Secrets Manager, Amazon Identity and Access Management, Amazon S3, and Amazon Lambda, make sure to configure your integrations with these services as needed. For more information about integrating Aurora global databases with IAM, Amazon S3 and Lambda, see Using Amazon Aurora global databases with other Amazon services. To learn more about Secrets Manager, see How to automate replication of secrets in Amazon Secrets Manager across Amazon Web Services Regions
.
-
If you are using the Aurora Global Database writer endpoint, you don't need to change the connection settings in your application. Verify that the DNS changes have propagated and that you can connect and perform write operations on the new primary cluster. Then you can resume full operation of your application.
Suppose that your application connections use the cluster endpoint of the old primary cluster, instead of the
global writer endpoint. In that case, make sure to change the your application connection settings to use the
cluster endpoint of the new primary cluster. If you accepted the provided names when you created the Aurora
global database, you can change the endpoint by removing the -ro from the promoted cluster's
endpoint string in your application. For example, the secondary cluster's endpoint
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com
becomes my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com when that cluster is promoted to
primary.
If you're using RDS Proxy, make sure to redirect your application's write operations to the appropriate read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write endpoint. For more information see How RDS Proxy endpoints work with global databases.
You can perform an Aurora Global Database switchover using the Amazon Web Services Management Console, the Amazon CLI, or the RDS API.
To perform the switchover on your Aurora global database
Sign in to the Amazon Web Services Management Console and open the Amazon RDS console at https://console.amazonaws.cn/rds/
. -
Choose Databases and find the Aurora global database where you intend to perform the switchover.
-
Choose Switch over or fail over global database from the Actions menu.
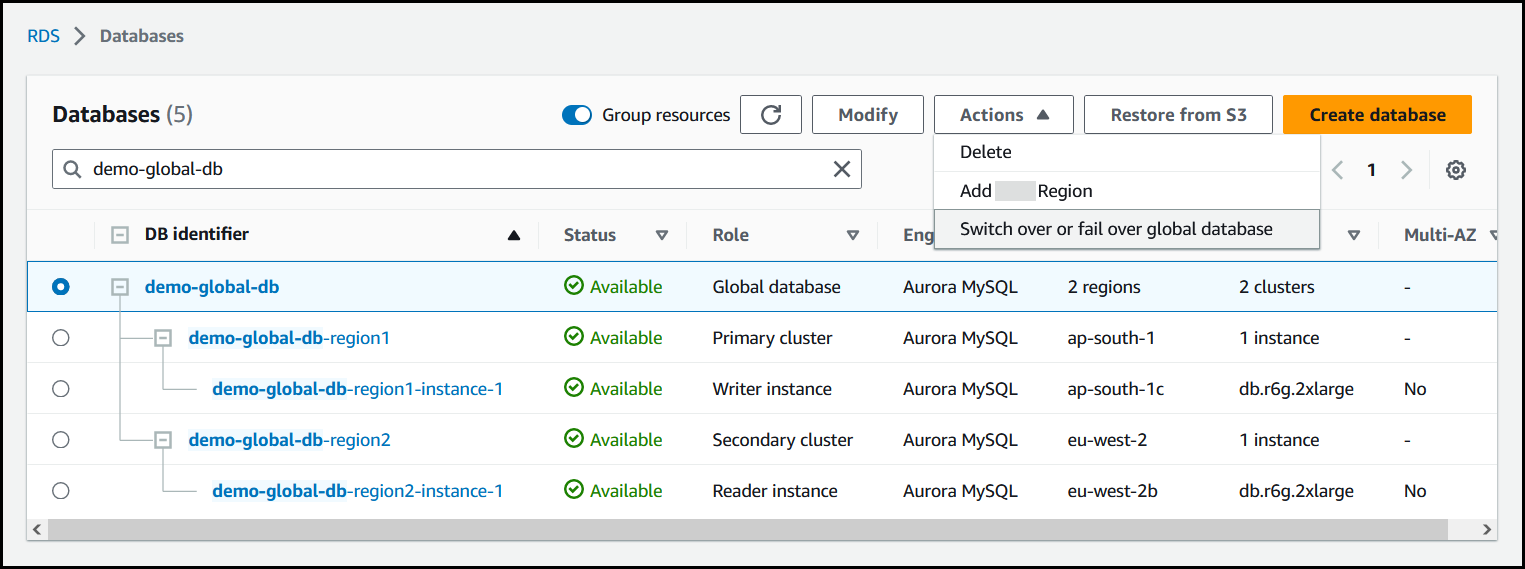
-
Choose Switchover.
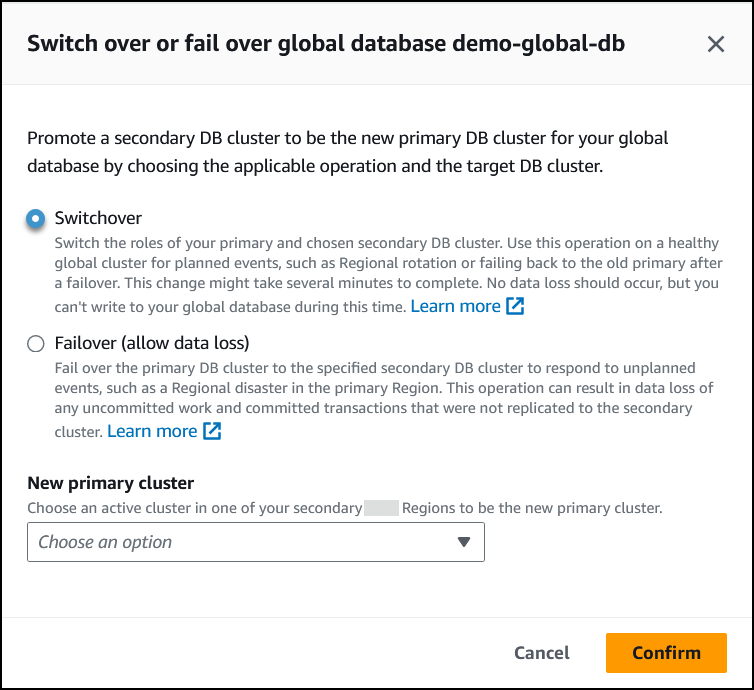
-
For New primary cluster, choose an active cluster in one of your secondary Amazon Web Services Regions to be the new primary cluster.
-
Choose Confirm.
When the switchover completes, you can see the Aurora DB clusters and their current roles in the Databases list, as shown in the following image.
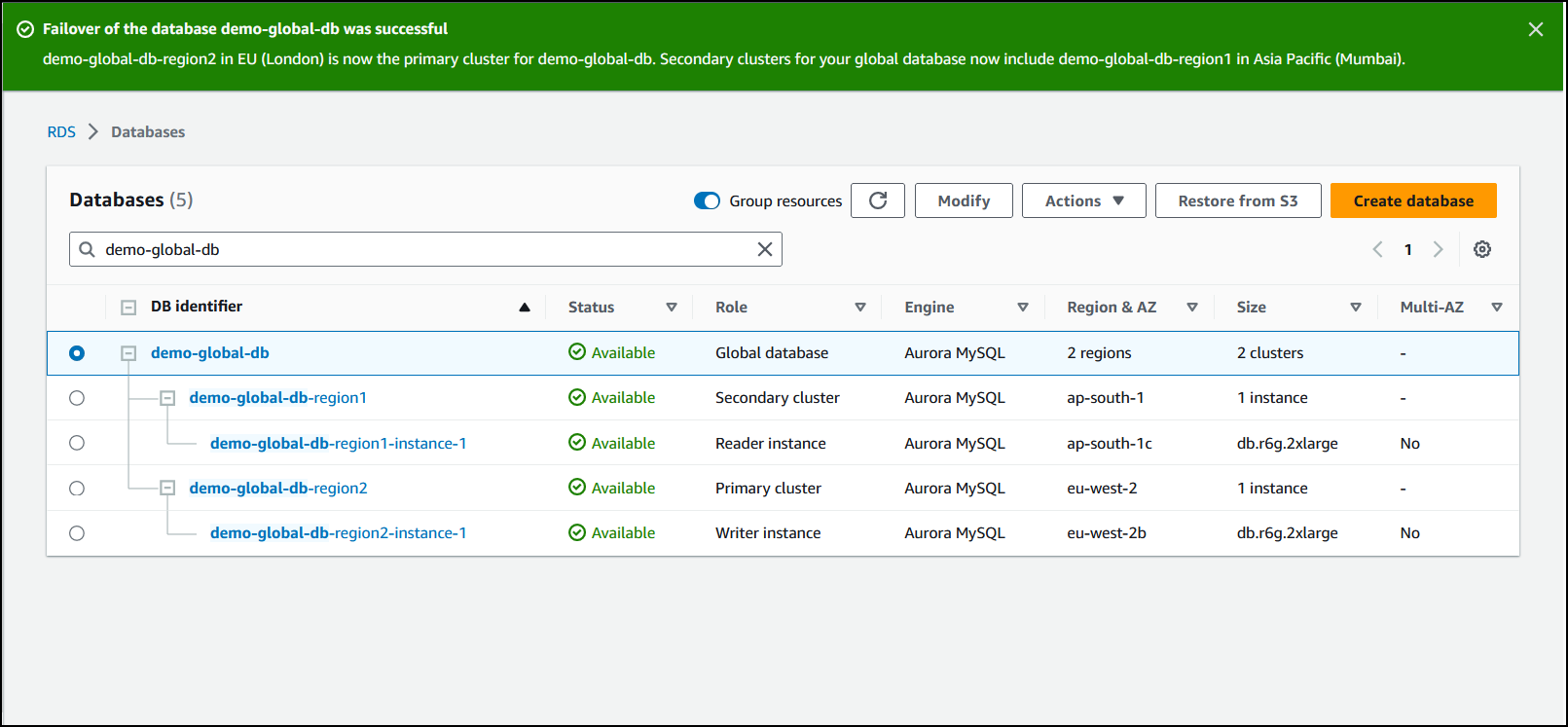
To perform the switchover on an Aurora global database
Use the
switchover-global-cluster
CLI command to perform a switchover for Aurora Global Database. With the command, pass values for the
following parameters.
-
--region– Specify the Amazon Web Services Region where the primary DB cluster of the Aurora global database is running. -
--global-cluster-identifier– Specify the name of your Aurora global database. -
--target-db-cluster-identifier– Specify the Amazon Resource Name (ARN) of the Aurora DB cluster that you want to promote to be the primary for the Aurora global database.
For Linux, macOS, or Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
For Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
To perform a switchover for Aurora Global Database, run the SwitchoverGlobalCluster API operation.
Recovering an Amazon Aurora global database from an unplanned outage
On rare occasions, your Aurora global database might experience an unexpected outage in its primary Amazon Web Services Region. If this happens, your primary Aurora DB cluster and its writer node aren't available, and the replication between the primary and secondary DB clusters stops. To minimize both downtime (RTO) and data loss (RPO), you can work quickly to perform a cross-Region failover.
Aurora Global Database has two failover methods that you can use in a disaster recovery situation:
-
Managed failover – This method is recommended for disaster recovery. When you use this method, Aurora automatically adds back the old primary Region to the global database as a secondary Region when it becomes available again. Thus, the original topology of your global cluster is maintained. To learn how to use this method, see Performing managed failovers for Aurora global databases.
-
Manual failover – This alternative method can be used when managed failover isn't an option, for example, when your primary and secondary Regions are running incompatible engine versions. To learn how to use this method, see Performing manual failovers for Aurora global databases.
Important
Both failover methods can result in a loss of write transaction data that wasn't replicated to the chosen secondary before the failover event occurred. However, the recovery process that promotes a DB instance on the chosen secondary DB cluster to be the primary writer DB instance guarantees that the data is in a transactionally consistent state. Failovers are also susceptible to split-brain issues.
Performing managed failovers for Aurora global databases
This approach is intended for business continuity in the event of a true Regional disaster or complete service-level outage.
During a managed failover, the secondary cluster in your chosen secondary Region becomes the new primary cluster. The chosen secondary cluster promotes one of its read-only nodes to full writer status. This step allows the cluster to assume the role of primary cluster. Your database is unavailable for a short time while this cluster is assuming its new role. As soon as that old primary Region is healthy and available again, Aurora automatically adds it back to the global cluster as a secondary Region. Thus, your Aurora global database's existing replication topology is maintained.
Note
To manage replication slots for Aurora PostgreSQL after performing a failover, see Managing logical slots for Aurora PostgreSQL.
Note
You can perform managed cross-Region failovers with Aurora Global Database only if the primary and secondary DB clusters have the same major and minor engine versions. Depending on the engine and engine versions, the patch levels might need to be identical or the patch levels can be different. For a list of engines and engine versions that allow these operations between primary and secondary clusters with different patch levels, see Patch level compatibility for managed cross-Region switchovers and failovers. Before you begin the failover, check the engine versions in your global cluster to make sure that they support managed cross-Region switchover, and upgrade them if needed. If your engine versions require identical patch levels but are running different patch levels, you can perform the failover manually by following the steps in Performing manual failovers for Aurora global databases.
Managed failover doesn't wait for data to synchronize between the chosen secondary Region and the current primary Region. Because Aurora Global Database replicates data asynchronously, it's possible that not all transactions replicated to the chosen secondary Amazon Region before it's promoted to accept full read/write capabilities.
To ensure the data is in a consistent state, Aurora creates a new storage volume for the old primary Region
after it recovers. Before creating the new storage volume in the Amazon Region, Aurora attempts to take a
snapshot of the old storage volume at the point of failure. That way, you can restore the snapshot and recover
any of the missing data from it. If this operation is successful, Aurora places this snapshot named
rds:unplanned-global-failover-
in the snapshot section of the Amazon Web Services Management Console. You can also use the name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots
Amazon CLI command or the DescribeDBClusterSnapshots API operation to see details for the snapshot.
When you initiate a managed failover, Aurora also attempts to halt write traffic through the highly-available Aurora storage layer. We refer to this mechanism as "write fencing". If the process succeeds, Aurora emits an RDS Event letting you know that writes were stopped. In the unlikely event of multiple AZ failures in a Region, it's possible that the write fencing process doesn't succeed in a timely manner. In that case, Aurora emits an RDS event informing you that the process to stop writes timed out. If the old primary cluster is reachable on the network, Aurora records these events there. If not, Aurora records the events on the new primary cluster. To learn more about these events, see DB cluster events. Because fencing writes is a best-effort attempt, it's possible that writes might be momentarily accepted in the old primary Region, causing split-brain issues.
We recommend that you complete the following tasks before you perform a failover with Aurora Global Database. Doing so minimizes the possibility of split-brain issues, or recovering unreplicated data from the snapshot of the old primary cluster.
-
To prevent writes from being sent to the primary cluster of Aurora Global Database, take applications offline.
-
Make sure that any applications that connect to the primary DB cluster are using the global writer endpoint. This endpoint has a value that remains the same even when a new Region becomes the primary cluster because of switchover or failover. Aurora implements additional safeguards to minimize the possibility of data loss for write operations submitted through the global endpoint. For more information about global writer endpoints, see Connecting to Amazon Aurora Global Database.
-
If you are using the global writer endpoint and your application or networking layers cache DNS values, reduce the time-to-live (TTL) of your DNS cache to a low value such as 5 seconds. That way, your application quickly registers DNS changes with the global writer endpoint. Although Aurora attempts to block writes in the old primary Region, the action is not guaranteed to succeed. Reducing the DNS cache duration further reduces the likelihood of split-brain issues. As an alternative, you can check for the RDS event that informs you when Aurora observed the DNS changes for the global writer endpoint. That way, you can validate that your application also registered the DNS change before restarting your application write traffic.
-
Check lag times for all secondary Aurora DB clusters in the Aurora Global Database. Choosing the secondary Region with the least replication lag can minimize data loss with the current failed primary Region.
For all versions of Aurora PostgreSQL-based global databases, and for Aurora MySQL-based global databases starting with engine versions 3.04.0 and higher or 2.12.0 and higher, use Amazon CloudWatch to view the
AuroraGlobalDBRPOLagmetric for all secondary DB clusters. For lower minor versions of Aurora MySQL-based global databases, view theAuroraGlobalDBReplicationLagmetric instead. These metrics show you how far behind (in milliseconds) replication to a secondary cluster is to the primary DB cluster.For more information about CloudWatch metrics for Aurora, see Cluster-level metrics for Amazon Aurora.
During a managed failover, the chosen secondary DB cluster is promoted to its new role as primary. However, it doesn't inherit the various configuration options of the primary DB cluster. A mismatch in configuration can lead to performance issues, workload incompatibilities, and other anomalous behavior. To avoid such issues, we recommend that you resolve differences between your Aurora global database clusters for the following:
-
Configure Aurora DB cluster parameter group for the new primary, if necessary – You can configure your Aurora DB cluster parameter groups independently for each Aurora cluster in your Aurora Global Database. Therefore, when you promote a secondary DB cluster to take over the primary role, the parameter group from the secondary might be configured differently than for the primary. If so, modify the promoted secondary DB cluster's parameter group to conform to your primary cluster's settings. To learn how, see Modifying parameters for an Aurora global database.
-
Configure monitoring tools and options, such as Amazon CloudWatch Events and alarms – Configure the promoted DB cluster with the same logging ability, alarms, and so on as needed for the global database. As with parameter groups, configuration for these features isn't inherited from the primary during the failover process. Some CloudWatch metrics, such as replication lag, are only available for secondary Regions. Thus, a failover changes how to view those metrics and set alarms on them, and could require changes to any predefined dashboards. For more information about monitoring Aurora DB clusters, see Monitoring Amazon Aurora metrics with Amazon CloudWatch.
-
Configure integrations with other Amazon services – If your Aurora Global Database integrates with other Amazon services, such as Amazon Secrets Manager, Amazon Identity and Access Management, Amazon S3, and Amazon Lambda, you need to make sure these are configured as required for access from any secondary Regions. For more information about integrating Aurora global databases with IAM, Amazon S3 and Lambda, see Using Amazon Aurora global databases with other Amazon services. To learn more about Secrets Manager, see How to automate replication of secrets in Amazon Secrets Manager across Amazon Web Services Regions
.
Typically, the chosen secondary cluster assumes the primary role within a few minutes. As soon as the new primary Region's writer DB instance is available, you can connect your applications to it and resume your workloads. After Aurora promotes the new primary cluster, it automatically rebuilds all additional secondary Region clusters.
Because Aurora global databases use asynchronous replication, the replication lag in each secondary Region can vary. Aurora rebuilds these secondary Regions to have the exact same point-in-time data as the new primary Region cluster. The duration of the complete rebuilding task can take a few minutes to several hours, depending on the size of the storage volume and the distance between the Regions. When the secondary Region clusters finish rebuilding from the new primary Region, they become available for read access.
As soon as the new primary writer is promoted and available, the new primary Region's cluster can handle read and write operations for the Aurora global database.
If you are using the global endpoint, you don't need to change the connection settings in your application. Verify that the DNS changes have propagated and that you can connect and perform write operations on the new primary cluster. Then you can resume full operation of your application.
If you aren't using the global endpoint, make sure to change the endpoint for your application to use the
cluster endpoint for the newly promoted primary DB cluster. If you accepted the provided names when you
created the Aurora global database, you can change the endpoint by removing the -ro from the
promoted cluster's endpoint string in your application.
For example, the secondary cluster's endpoint
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com
becomes my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com when that cluster is promoted
to primary.
If you are using RDS Proxy, make sure to redirect your application's write operations to the appropriate read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write endpoint. For more information see How RDS Proxy endpoints work with global databases.
To restore the global database cluster's original topology, Aurora monitors the availability of the old
primary Region. As soon as that Region is healthy and available again, Aurora
automatically adds it back to the global cluster as a secondary Region. Before creating the
new storage volume in the old primary Region, Aurora tries to take a snapshot of the old
storage volume at the point of failure. It does this so that you can use it to recover any of the missing
data. If this operation is successful, Aurora creates a snapshot named
rds:unplanned-global-failover-.
You can find this snapshot in the Snapshots section of the Amazon Web Services Management Console. You can also see
this snapshot listed in the information returned by the
DescribeDBClusterSnapshots API
operation.
name-of-old-primary-DB-cluster-timestamp
Note
The snapshot of the old storage volume is a system snapshot that's subject to the backup retention period configured on the old primary cluster. To preserve this snapshot outside of the retention period, you can copy it to save it as a manual snapshot. To learn more about copying snapshots, including pricing, see DB cluster snapshot copying.
After the original topology is restored, you can fail back your global database to the original primary Region by performing a switchover operation when it makes the most sense for your business and workload. To do so, follow the steps in Performing switchovers for Amazon Aurora global databases.
You can perform a failover with Aurora Global Database using the Amazon Web Services Management Console, the Amazon CLI, or the RDS API.
To perform the managed failover on your Aurora global database
Sign in to the Amazon Web Services Management Console and open the Amazon RDS console at https://console.amazonaws.cn/rds/
. -
Choose Databases and find the Aurora global database where you want to perform the failover.
-
Choose Switch over or fail over global database from the Actions menu.
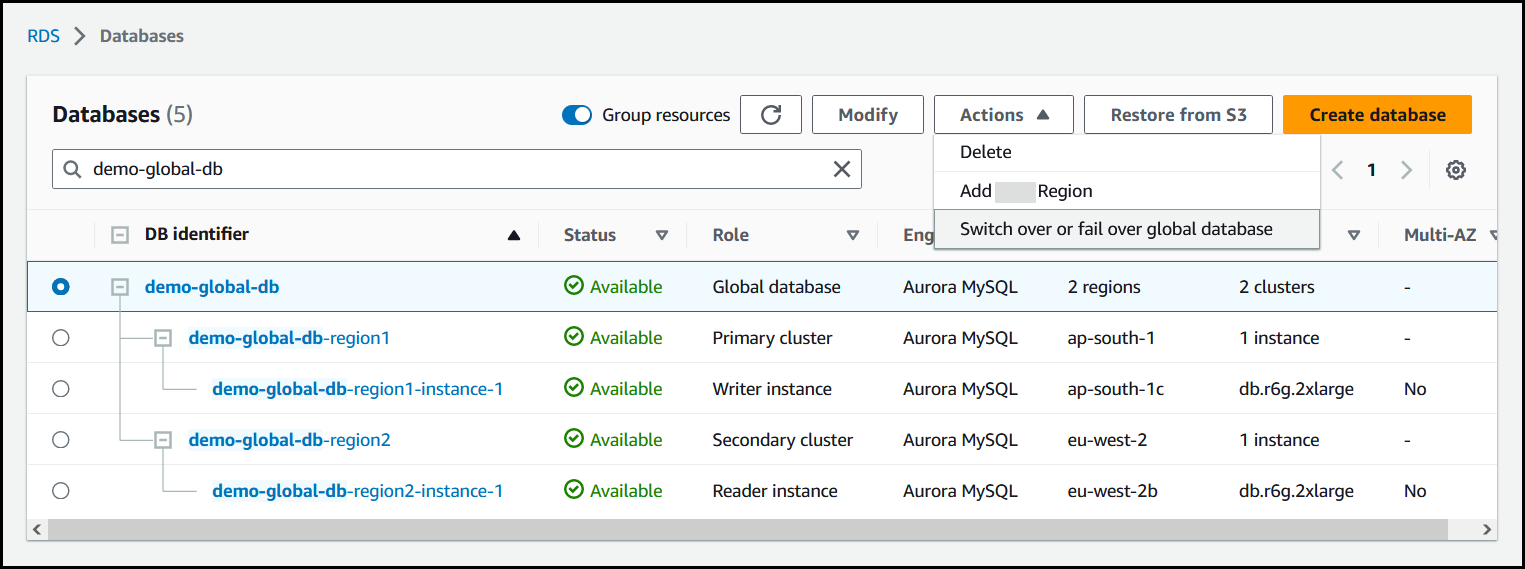
-
Choose Failover (allow data loss).
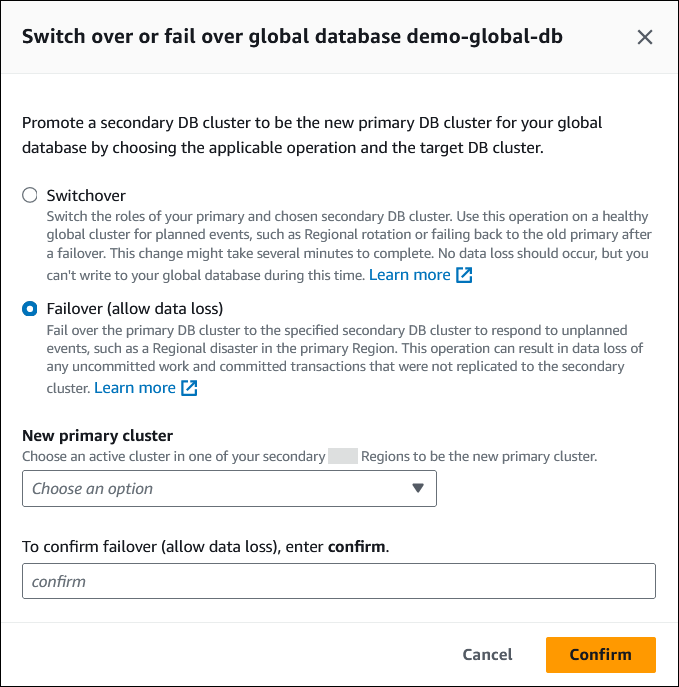
-
For New primary cluster, choose an active cluster in one of your secondary Amazon Web Services Regions to be the new primary cluster.
-
Enter
confirm, and then choose Confirm.
When the failover completes, you can view the Aurora DB clusters and their current state in the Databases list, as shown in the following image.
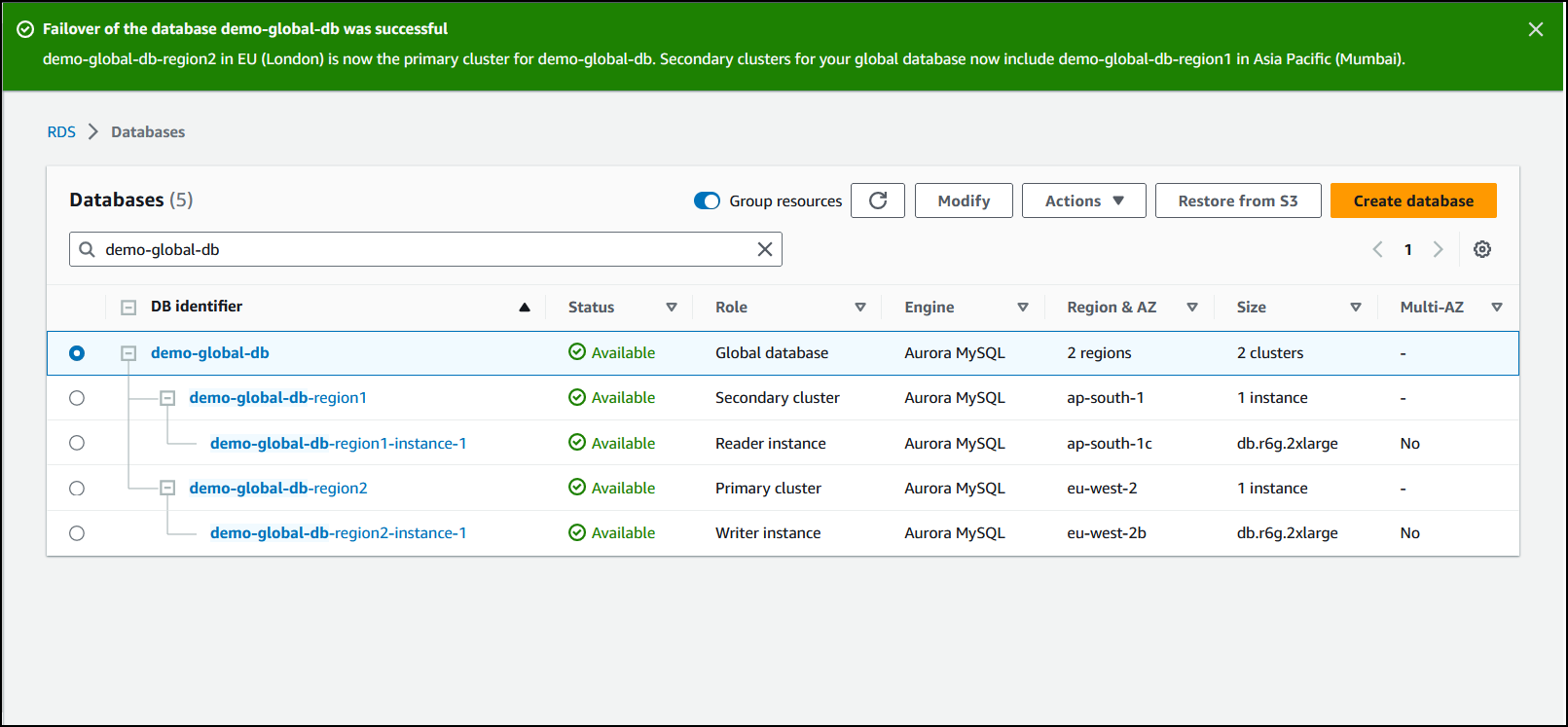
To perform the managed failover on an Aurora global database
Use the
failover-global-cluster
CLI command to perform a failover with Aurora Global Database. With the command, pass values for the
following parameters.
-
--region– Specify the Amazon Web Services Region where the secondary DB cluster that you want to be the new primary for the Aurora global database is running. -
--global-cluster-identifier– Specify the name of your Aurora global database. -
--target-db-cluster-identifier– Specify the Amazon Resource Name (ARN) of the Aurora DB cluster that you want to promote to be the new primary for the Aurora global database. -
--allow-data-loss– Explicitly make this a failover operation instead of a switchover operation. A failover operation can result in some data loss if the asynchronous replication components haven't completed sending all replicated data to the secondary Region.
For Linux, macOS, or Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
For Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
To perform a failover with Aurora Global Database, run the FailoverGlobalCluster API operation.
Performing manual failovers for Aurora global databases
In some scenarios, you might not be able to use the managed failover process. One example is if your primary and secondary DB clusters aren't running compatible engine versions. In this case, you can follow this manual process to perform a failover to your target secondary Region.
Tip
We recommend that you understand this process before using it. Have a plan ready to quickly proceed at the first sign of a Region-wide issue. You can be ready to identify the secondary Region with the least replication lag by using Amazon CloudWatch regularly to track lag times for the secondary clusters. Make sure to test your plan to check that your procedures are complete and accurate, and that staff are trained to perform a disaster recovery failover before it really happens.
To perform a manual failover to a secondary cluster after an unplanned outage in the primary Region
-
Stop issuing DML statements and other write operations to the primary Aurora DB cluster in the Amazon Web Services Region with the outage.
-
Identify an Aurora DB cluster from a secondary Amazon Web Services Region to use as a new primary DB cluster. If you have two or more secondary Amazon Web Services Regions in your Aurora global database, choose the secondary cluster that has the least replication lag.
-
Detach your chosen secondary DB cluster from the Aurora global database.
Removing a secondary DB cluster from an Aurora global database immediately stops the replication from the primary to this secondary and promotes it to a standalone provisioned Aurora DB cluster with full read/write capabilities. Any other secondary Aurora DB clusters associated with the primary cluster in the Region with the outage are still available and can accept calls from your application. They also consume resources. Because you're recreating the Aurora global database, remove the other secondary DB clusters before creating the new Aurora global database in the following steps. Doing this avoids data inconsistencies among the DB clusters in the Aurora global database (split-brain issues).
For detailed steps for detaching, see Removing a cluster from an Amazon Aurora global database.
-
Reconfigure your application to send all write operations to this now standalone Aurora DB cluster using its new endpoint. If you accepted the provided names when you created the Aurora global database, you can change the endpoint by removing the
-rofrom the cluster's endpoint string in your application.For example, the secondary cluster's endpoint
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.combecomesmy-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.comwhen that cluster is detached from the Aurora global database.This Aurora DB cluster becomes the primary cluster of a new Aurora global database when you start adding Regions to it in the next step.
If you are using RDS Proxy, make sure to redirect your application's write operations to the appropriate read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write endpoint. For more information see How RDS Proxy endpoints work with global databases.
-
Add an Amazon Web Services Region to the DB cluster. When you do this, the replication process from primary to secondary begins. For detailed steps to add a Region, see Adding an Amazon Web Services Region to an Amazon Aurora global database.
-
Add more Amazon Web Services Regions as needed to recreate the topology needed to support your application.
Make sure that application writes are sent to the correct Aurora DB cluster before, during, and after making these changes. Doing this avoids data inconsistencies among the DB clusters in the Aurora global database (split-brain issues).
If you reconfigured in response to an outage in an Amazon Web Services Region, you can make that Amazon Web Services Region the primary again after the outage is resolved. To do so, you add the old Amazon Web Services Region to your new global database, and then use the switchover process to switch its role. Your Aurora global database must use a version of Aurora PostgreSQL or Aurora MySQL that supports switchovers. For more information, see Performing switchovers for Amazon Aurora global databases.
Managing RPOs for Aurora PostgreSQL–based global databases
With an Aurora PostgreSQL–based global database, you can manage the recovery point objective (RPO) for your
Aurora global database by using the rds.global_db_rpo parameter. RPO represents the maximum amount
of data that can be lost in the event of an outage.
When you set an RPO for your Aurora PostgreSQL–based global database, Aurora monitors the RPO lag time of all secondary clusters to make sure that at least one secondary cluster stays within the target RPO window. RPO lag time is another time-based metric.
The RPO is used when your database resumes operations in a new Amazon Web Services Region after a failover. Aurora evaluates RPO and RPO lag times to commit (or block) transactions on the primary as follows:
-
Commits the transaction if at least one secondary DB cluster has an RPO lag time less than the RPO.
-
Blocks the transaction if all secondary DB clusters have RPO lag times that are larger than the RPO. It also logs the event to the PostgreSQL log file and emits "wait" events that show the blocked sessions.
In other words, if all secondary clusters are behind the target RPO, Aurora pauses transactions on the primary cluster until at least one of the secondary clusters catches up. Paused transactions are resumed and committed as soon as the lag time of at least one secondary DB cluster becomes less than the RPO. The result is that no transactions can commit until the RPO is met.
The rds.global_db_rpo parameter is dynamic. If you decide that you don't want all write
transactions to stall until the lag decreases sufficiently, you can reset it quickly. In this case, Aurora
recognizes and implements the change after a short delay.
Important
In a global database with only two Amazon Regions, we recommend keeping the rds.global_db_rpo
parameter's default value in the secondary Region's parameter group. Otherwise, performing a failover
due to a loss of the primary Amazon Region could cause Aurora to pause transactions. Instead, wait until Aurora
completes rebuilding the cluster in the old failed Amazon Region before changing this parameter to enforce a
maximum RPO.
If you set this parameter as outlined in the following, you can also monitor the metrics that it
generates. You can do so by using psql or another tool to query the Aurora global database's
primary DB cluster and obtain detailed information about your Aurora PostgreSQL–based global
database's operations. To learn how, see
Monitoring Aurora PostgreSQL-based global databases.
Topics
Setting the recovery point objective
The rds.global_db_rpo parameter controls the RPO setting for a PostgreSQL database. This
parameter is supported by Aurora PostgreSQL. Valid values for rds.global_db_rpo range from 20
seconds to 2,147,483,647 seconds (68 years). Choose a realistic value to meet your business need and use
case. For example, you might want to allow up to 10 minutes for your RPO, in which case you set the value to
600.
You can set this value for your Aurora PostgreSQL–based global database by using the Amazon Web Services Management Console, the Amazon CLI, or the RDS API.
To set the RPO
Sign in to the Amazon Web Services Management Console and open the Amazon RDS console at https://console.amazonaws.cn/rds/
. -
Choose the primary cluster of your Aurora global database and open the Configuration tab to find its DB cluster parameter group. For example, the default parameter group for a primary DB cluster running Aurora PostgreSQL 11.7 is
default.aurora-postgresql11.Parameter groups can't be edited directly. Instead, you do the following:
-
Create a custom DB cluster parameter group using the appropriate default parameter group as the starting point. For example, create a custom DB cluster parameter group based on the
default.aurora-postgresql11. -
On your custom DB parameter group, set the value of the rds.global_db_rpo parameter to meet your use case. Valid values range from 20 seconds up to the maximum integer value of 2,147,483,647 (68 years).
-
Apply the modified DB cluster parameter group to your Aurora DB cluster.
-
For more information, see Modifying parameters in a DB cluster parameter groupin Amazon Aurora.
To set the rds.global_db_rpo parameter, use the
modify-db-cluster-parameter-group
CLI command. In the command, specify the name of your primary cluster's parameter group and values
for RPO parameter.
The following example sets the RPO to 600 seconds (10 minutes) for the primary DB cluster's
parameter group named my_custom_global_parameter_group.
For Linux, macOS, or Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
For Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
To modify the rds.global_db_rpo parameter, use the Amazon RDS
ModifyDBClusterParameterGroup
API operation.
Viewing the recovery point objective
The recovery point objective (RPO) of a global database is stored in the rds.global_db_rpo
parameter for each DB cluster. You can connect to the endpoint for the secondary cluster you want to view
and use psql to query the instance for this value.
show rds.global_db_rpo;db-name=>
If this parameter isn't set, the query returns the following:
rds.global_db_rpo
-------------------
-1
(1 row)This next response is from a secondary DB cluster that has 1 minute RPO setting.
rds.global_db_rpo
-------------------
60
(1 row)
You can also use the CLI to get values for find out if rds.global_db_rpo is active on any of
the Aurora DB clusters by using the CLI to get values of all user parameters for the cluster.
For Linux, macOS, or Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
For Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
The command returns output similar to the following for all user parameters. that aren't
default-engine or system DB cluster parameters.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
To learn more about viewing parameters of the cluster parameter group, see Viewing parameter values for a DB cluster parameter groupin Amazon Aurora.
Disabling the recovery point objective
To disable the RPO, reset the rds.global_db_rpo parameter. You can reset parameters using the
Amazon Web Services Management Console, the Amazon CLI, or the RDS API.
To disable the RPO
Sign in to the Amazon Web Services Management Console and open the Amazon RDS console at https://console.amazonaws.cn/rds/
. -
In the navigation pane, choose Parameter groups.
-
In the list, choose your primary DB cluster parameter group.
-
Choose Edit parameters.
-
Choose the box next to the rds.global_db_rpo parameter.
-
Choose Reset.
-
When the screen shows Reset parameters in DB parameter group, choose Reset parameters.
For more information on how to reset a parameter with the console, see Modifying parameters in a DB cluster parameter groupin Amazon Aurora.
To reset the rds.global_db_rpo parameter, use the
reset-db-cluster-parameter-group
command.
For Linux, macOS, or Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
For Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
To reset the rds.global_db_rpo parameter, use the Amazon RDS API
ResetDBClusterParameterGroup operation.