Evaluate your provisioned capacity for right-sized provisioning in your DynamoDB table
This section provides an overview of how to evaluate if you have right-sized provisioning on your DynamoDB tables. As your workload evolves, you should modify your operational procedures appropriately, especially when your DynamoDB table is configured in provisioned mode and you have the risk to over-provision or under-provision your tables.
The procedures described below require statistical information that should be captured from the DynamoDB tables that are supporting your production application. To understand your application behavior, you should define a period of time that is significant enough to capture the data seasonality from your application. For example, if your application shows weekly patterns, using a three week period should give you enough room for analysing application throughput needs.
If you don’t know where to start, use at least one month’s worth of data usage for the calculations below.
While evaluating capacity, DynamoDB tables can configure Read Capacity Units (RCUs) and Write Capacity Units (WCU) independently. If your tables have any Global Secondary Indexes (GSI) configured, you will need to specify the throughput that it will consume, which will be also independent from the RCUs and WCUs from the base table.
Note
Local Secondary Indexes (LSI) consume capacity from the base table.
Topics
How to retrieve consumption metrics on your DynamoDB tables
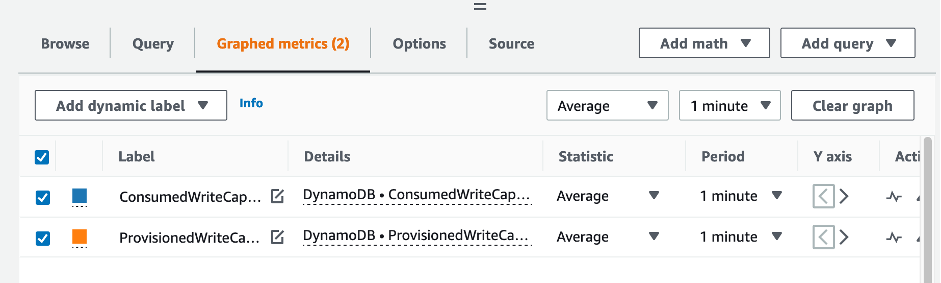
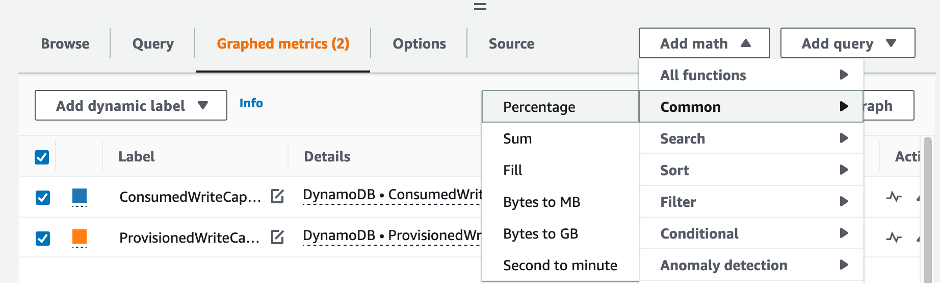
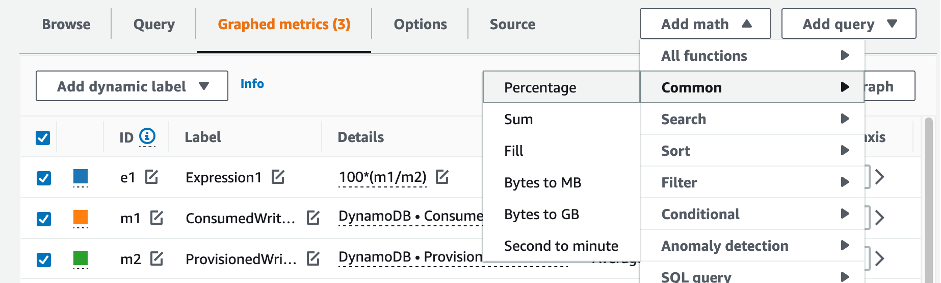
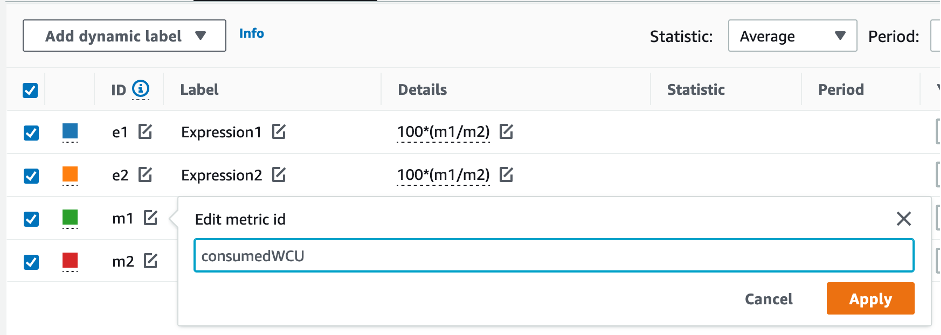
To evaluate the table and GSI capacity, monitor the following CloudWatch metrics and select the appropriate dimension to retrieve either table or GSI information:
| Read Capacity Units | Write Capacity Units |
|---|---|
|
|
|
|
|
|
|
|
|
You can do this either through the Amazon CLI or the Amazon Web Services Management Console.



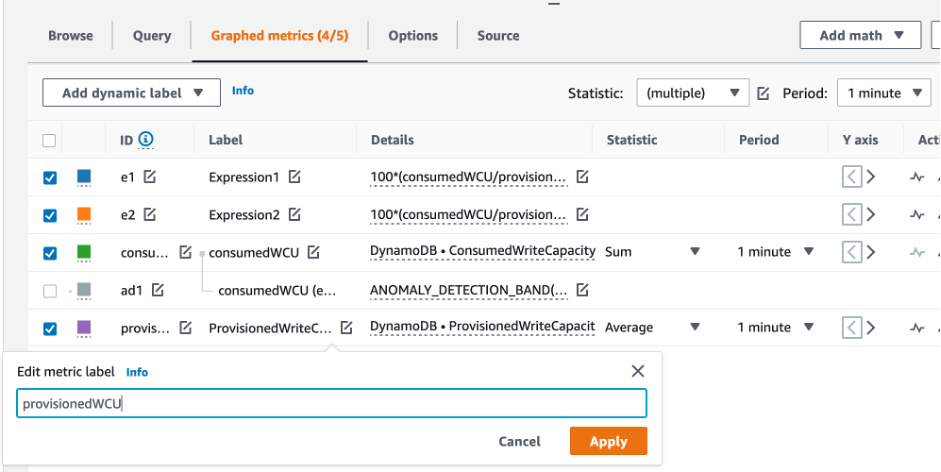

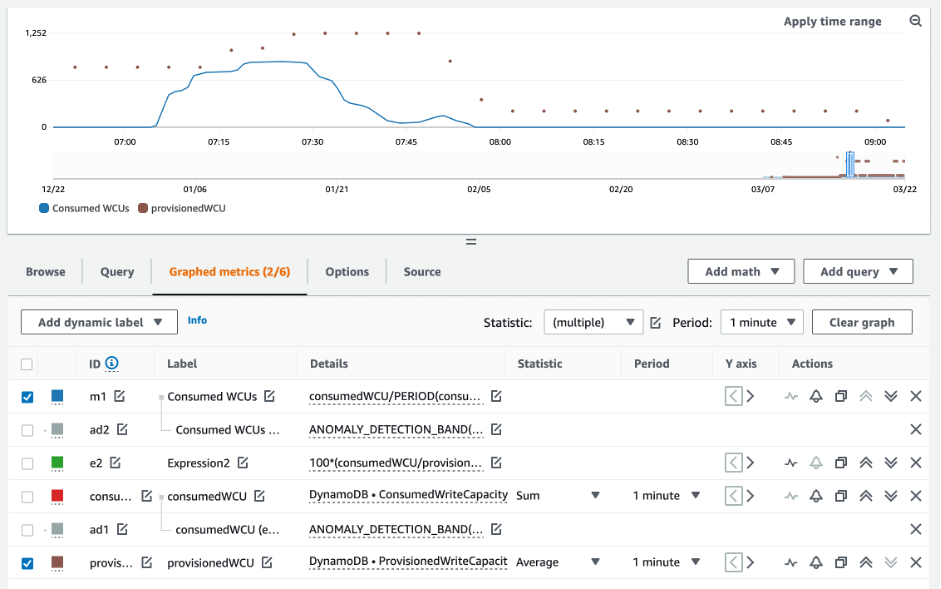
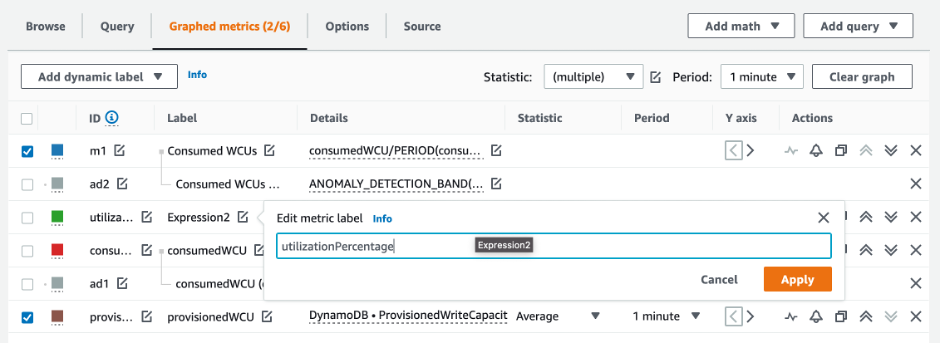
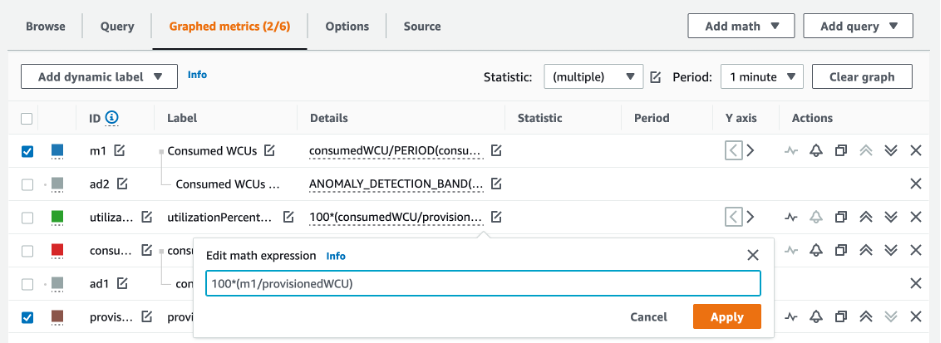

How to identify under-provisioned DynamoDB tables
For most workloads, a table is considered under-provisioned when it constantly consumes more than 80% of their provisioned capacity.
Burst capacity is a DynamoDB feature that allow customers to temporarily consume more RCUs/WCUs than originally provisioned (more than the per-second provisioned throughput that was defined in the table). The burst capacity was created to absorb sudden increases in traffic due to special events or usage spikes. This burst capacity doesn’t last forever. As soon as the unused RCUs and WCUs are depleted, you will get throttled if you try to consume more capacity than provisioned. When your application traffic is getting close to the 80% utilization rate, your risk of throttling is significantly higher.
The 80% utilization rate rule varies from the seasonality of your data and your traffic growth. Consider the following scenarios:
-
If your traffic has been stable at ~90% utilization rate for the last 12 months, your table has just the right capacity
-
If your application traffic is growing at a rate of 8% monthly in less than 3 months, you will arrive at 100%
-
If your application traffic is growing at a rate of 5% in a little more than 4 months, you will still arrive at 100%
The results from the queries above provide a picture of your utilization rate. Use them as a guide to further evaluate other metrics that can help you choose to increase your table capacity as required (for example: a monthly or weekly growth rate). Work with your operations team to define what is a good percentage for your workload and your tables.
There are special scenarios where the data is skewed when we analyse it on a daily or weekly basis. For example, with seasonal applications that have spikes in usage during working hours (but then drops to almost zero outside of working hours), you could benefit by scheduling auto scaling where you specify the hours of the day (and the days of the week) to increase the provisioned capacity and when to reduce it. Instead of aiming for higher capacity so you can cover the busy hours, you can also benefit from DynamoDB table auto scaling configurations if your seasonality is less pronounced.
Note
When you create a DynamoDB auto scaling configuration for your base table, remember to include another configuration for any GSI that is associated with the table.
How to identify over-provisioned DynamoDB tables
The query results obtained from the scripts above provide the data points required to perform some initial analysis. If your data set presents values lower than 20% utilization for several intervals, your table might be over-provisioned. To further define if you need to reduce the number of WCUs and RCUS, you should revisit the other readings in the intervals.
When your tables contain several low usage intervals, you can really benefit from using auto scaling policies, either by scheduling auto scaling or just configuring the default auto scaling policies for the table that are based on utilization.
If you have a workload with low utilization to high throttle ratio (Max(ThrottleEvents)/Min(ThrottleEvents) in the interval), this could happen when you have a very spiky workload where traffic increases a lot during some days (or hours), but in general the traffic is consistently low. In these scenarios it might be beneficial to use scheduled auto scaling.