Local secondary indexes
Some applications only need to query data using the base table's primary key. However,
there might be situations where an alternative sort key would be helpful. To give your
application a choice of sort keys, you can create one or more local secondary indexes on an
Amazon DynamoDB table and issue Query or Scan requests against these
indexes.
Scenario: Using a Local Secondary Index
As an example, consider the Thread table. This table is useful for an
application such as the Amazon discussion forums
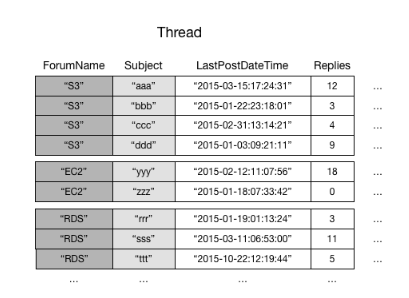
DynamoDB stores all of the items with the same partition key value continuously. In this
example, given a particular ForumName, a Query operation could
immediately locate all of the threads for that forum. Within a group of items with the
same partition key value, the items are sorted by sort key value. If the sort key
(Subject) is also provided in the query, DynamoDB can narrow down the
results that are returned—for example, returning all of the threads in the "S3"
forum that have a Subject beginning with the letter "a".
Some requests might require more complex data access patterns. For example:
-
Which forum threads get the most views and replies?
-
Which thread in a particular forum has the largest number of messages?
-
How many threads were posted in a particular forum within a particular time period?
To answer these questions, the Query action would not be sufficient.
Instead, you would have to Scan the entire table. For a table with millions
of items, this would consume a large amount of provisioned read throughput and take a
long time to complete.
However, you can specify one or more local secondary indexes on non-key attributes,
such as Replies or LastPostDateTime.
A local secondary index maintains an alternate sort key for a given partition key value. A local secondary index also contains a copy of some or all of the attributes from its base table. You specify which attributes are projected into the local secondary index when you create the table. The data in a local secondary index is organized by the same partition key as the base table, but with a different sort key. This lets you access data items efficiently across this different dimension. For greater query or scan flexibility, you can create up to five local secondary indexes per table.
Suppose that an application needs to find all of the threads that have been posted
within the last three months in a particular forum. Without a local secondary index, the application
would have to Scan the entire Thread table and discard any
posts that were not within the specified time frame. With a local secondary index, a Query
operation could use LastPostDateTime as a sort key and find the data
quickly.
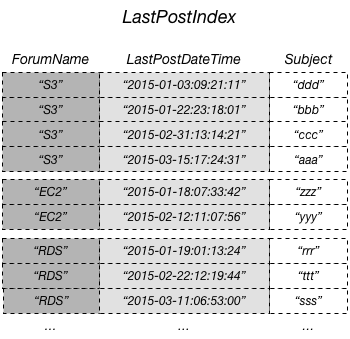
The following diagram shows a local secondary index named LastPostIndex. Note that the
partition key is the same as that of the Thread table, but the sort key is
LastPostDateTime.
Every local secondary index must meet the following conditions:
-
The partition key is the same as that of its base table.
-
The sort key consists of exactly one scalar attribute.
-
The sort key of the base table is projected into the index, where it acts as a non-key attribute.
In this example, the partition key is ForumName and the sort key of the
local secondary index is LastPostDateTime. In addition, the sort key value from the base
table (in this example, Subject) is projected into the index, but it is not
a part of the index key. If an application needs a list that is based on
ForumName and LastPostDateTime, it can issue a
Query request against LastPostIndex. The query results are
sorted by LastPostDateTime, and can be returned in ascending or descending
order. The query can also apply key conditions, such as returning only items that have a
LastPostDateTime within a particular time span.
Every local secondary index automatically contains the partition and sort keys from its base table; you can optionally project non-key attributes into the index. When you query the index, DynamoDB can retrieve these projected attributes efficiently. When you query a local secondary index, the query can also retrieve attributes that are not projected into the index. DynamoDB automatically fetches these attributes from the base table, but at a greater latency and with higher provisioned throughput costs.
For any local secondary index, you can store up to 10 GB of data per distinct partition key value. This figure includes all of the items in the base table, plus all of the items in the indexes, that have the same partition key value. For more information, see Item collections in Local Secondary Indexes.
Attribute projections
With LastPostIndex, an application could use ForumName and
LastPostDateTime as query criteria. However, to retrieve any additional
attributes, DynamoDB must perform additional read operations against the
Thread table. These extra reads are known as
fetches, and they can increase the total amount of provisioned
throughput required for a query.
Suppose that you wanted to populate a webpage with a list of all the threads in "S3" and the number of replies for each thread, sorted by the last reply date/time beginning with the most recent reply. To populate this list, you would need the following attributes:
-
Subject -
Replies -
LastPostDateTime
The most efficient way to query this data and to avoid fetch operations would be to
project the Replies attribute from the table into the local secondary index, as shown in
this diagram.

A projection is the set of attributes that is copied from a table into a secondary index. The partition key and sort key of the table are always projected into the index; you can project other attributes to support your application's query requirements. When you query an index, Amazon DynamoDB can access any attribute in the projection as if those attributes were in a table of their own.
When you create a secondary index, you need to specify the attributes that will be projected into the index. DynamoDB provides three different options for this:
-
KEYS_ONLY – Each item in the index consists only of the table partition key and sort key values, plus the index key values. The
KEYS_ONLYoption results in the smallest possible secondary index. -
INCLUDE – In addition to the attributes described in
KEYS_ONLY, the secondary index will include other non-key attributes that you specify. -
ALL – The secondary index includes all of the attributes from the source table. Because all of the table data is duplicated in the index, an
ALLprojection results in the largest possible secondary index.
In the previous diagram, the non-key attribute Replies is projected into
LastPostIndex. An application can query LastPostIndex
instead of the full Thread table to populate a webpage with
Subject, Replies, and LastPostDateTime. If
any other non-key attributes are requested, DynamoDB would need to fetch those attributes
from the Thread table.
From an application's point of view, fetching additional attributes from the base table is automatic and transparent, so there is no need to rewrite any application logic. However, such fetching can greatly reduce the performance advantage of using a local secondary index.
When you choose the attributes to project into a local secondary index, you must consider the tradeoff between provisioned throughput costs and storage costs:
-
If you need to access just a few attributes with the lowest possible latency, consider projecting only those attributes into a local secondary index. The smaller the index, the less that it costs to store it, and the less your write costs are. If there are attributes that you occasionally need to fetch, the cost for provisioned throughput may well outweigh the longer-term cost of storing those attributes.
-
If your application frequently accesses some non-key attributes, you should consider projecting those attributes into a local secondary index. The additional storage costs for the local secondary index offset the cost of performing frequent table scans.
-
If you need to access most of the non-key attributes on a frequent basis, you can project these attributes—or even the entire base table— into a local secondary index. This gives you maximum flexibility and lowest provisioned throughput consumption, because no fetching would be required. However, your storage cost would increase, or even double if you are projecting all attributes.
-
If your application needs to query a table infrequently, but must perform many writes or updates against the data in the table, consider projecting KEYS_ONLY. The local secondary index would be of minimal size, but would still be available when needed for query activity.
Creating a Local Secondary Index
To create one or more local secondary indexes on a table, use the LocalSecondaryIndexes
parameter of the CreateTable operation. Local secondary indexes on a table
are created when the table is created. When you delete a table, any local secondary
indexes on that table are also deleted.
You must specify one non-key attribute to act as the sort key of the local secondary index. The
attribute that you choose must be a scalar String, Number, or
Binary. Other scalar types, document types, and set types are not
allowed. For a complete list of data types, see Data types.
Important
For tables with local secondary indexes, there is a 10 GB size limit per partition key value. A table with local secondary indexes can store any number of items, as long as the total size for any one partition key value does not exceed 10 GB. For more information, see Item collection size limit.
You can project attributes of any data type into a local secondary index. This includes scalars, documents, and sets. For a complete list of data types, see Data types.
Reading data from a Local Secondary Index
You can retrieve items from a local secondary index using the Query and Scan
operations. The GetItem and BatchGetItem operations can't be
used on a local secondary index.
Querying a Local Secondary Index
In a DynamoDB table, the combined partition key value and sort key value for each
item must be unique. However, in a local secondary index, the sort key value does not need to be
unique for a given partition key value. If there are multiple items in the local secondary index
that have the same sort key value, a Query operation returns all of the
items that have the same partition key value. In the response, the matching items
are not returned in any particular order.
You can query a local secondary index using either eventually consistent or strongly consistent
reads. To specify which type of consistency you want, use the
ConsistentRead parameter of the Query operation. A
strongly consistent read from a local secondary index always returns the latest updated values. If
the query needs to fetch additional attributes from the base table, those attributes
will be consistent with respect to the index.
Example
Consider the following data returned from a Query that requests
data from the discussion threads in a particular forum.
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
In this query:
-
DynamoDB accesses
LastPostIndex, using theForumNamepartition key to locate the index items for "EC2". All of the index items with this key are stored adjacent to each other for rapid retrieval. -
Within this forum, DynamoDB uses the index to look up the keys that match the specified
LastPostDateTimecondition. -
Because the
Repliesattribute is projected into the index, DynamoDB can retrieve this attribute without consuming any additional provisioned throughput. -
The
Tagsattribute is not projected into the index, so DynamoDB must access theThreadtable and fetch this attribute. -
The results are returned, sorted by
LastPostDateTime. The index entries are sorted by partition key value and then by sort key value, andQueryreturns them in the order they are stored. (You can use theScanIndexForwardparameter to return the results in descending order.)
Because the Tags attribute is not projected into the local secondary index, DynamoDB
must consume additional read capacity units to fetch this attribute from the
base table. If you need to run this query often, you should project
Tags into LastPostIndex to avoid fetching from the
base table. However, if you needed to access Tags only
occasionally, the additional storage cost for projecting Tags into
the index might not be worthwhile.
Scanning a Local Secondary Index
You can use Scan to retrieve all of the data from a local secondary index. You must
provide the base table name and the index name in the request. With a
Scan, DynamoDB reads all of the data in the index and returns it to
the application. You can also request that only some of the data be returned, and
that the remaining data should be discarded. To do this, use the
FilterExpression parameter of the Scan API. For more
information, see Filter expressions for scan.
Item writes and Local Secondary Indexes
DynamoDB automatically keeps all local secondary indexes synchronized with their respective base tables. Applications never write directly to an index. However, it is important that you understand the implications of how DynamoDB maintains these indexes.
When you create a local secondary index, you specify an attribute to serve as the sort key for the
index. You also specify a data type for that attribute. This means that whenever you
write an item to the base table, if the item defines an index key attribute, its type
must match the index key schema's data type. In the case of LastPostIndex,
the LastPostDateTime sort key in the index is defined as a
String data type. If you try to add an item to the Thread
table and specify a different data type for LastPostDateTime (such as
Number), DynamoDB returns a ValidationException because of
the data type mismatch.
There is no requirement for a one-to-one relationship between the items in a base table and the items in a local secondary index. In fact, this behavior can be advantageous for many applications.
A table with many local secondary indexes incurs higher costs for write activity than tables with fewer indexes. For more information, see Provisioned throughput considerations for Local Secondary Indexes.
Important
For tables with local secondary indexes, there is a 10 GB size limit per partition key value. A table with local secondary indexes can store any number of items, as long as the total size for any one partition key value does not exceed 10 GB. For more information, see Item collection size limit.
Provisioned throughput considerations for Local Secondary Indexes
When you create a table in DynamoDB, you provision read and write capacity units for the table's expected workload. That workload includes read and write activity on the table's local secondary indexes.
To view the current rates for provisioned throughput capacity, see Amazon DynamoDB pricing
Read capacity units
When you query a local secondary index, the number of read capacity units consumed depends on how the data is accessed.
As with table queries, an index query can use either eventually consistent or
strongly consistent reads depending on the value of ConsistentRead. One
strongly consistent read consumes one read capacity unit; an eventually consistent
read consumes only half of that. Thus, by choosing eventually consistent reads, you
can reduce your read capacity unit charges.
For index queries that request only index keys and projected attributes, DynamoDB calculates the provisioned read activity in the same way as it does for queries against tables. The only difference is that the calculation is based on the sizes of the index entries, rather than the size of the item in the base table. The number of read capacity units is the sum of all projected attribute sizes across all of the items returned; the result is then rounded up to the next 4 KB boundary. For more information about how DynamoDB calculates provisioned throughput usage, see DynamoDB provisioned capacity mode.
For index queries that read attributes that are not projected into the local secondary index,
DynamoDB needs to fetch those attributes from the base table, in addition to reading
the projected attributes from the index. These fetches occur when you include any
non-projected attributes in the Select or
ProjectionExpression parameters of the Query
operation. Fetching causes additional latency in query responses, and it also incurs
a higher provisioned throughput cost: In addition to the reads from the local secondary index
described previously, you are charged for read capacity units for every base table
item fetched. This charge is for reading each entire item from the table, not just
the requested attributes.
The maximum size of the results returned by a Query operation is
1 MB. This includes the sizes of all the attribute names and values
across all of the items returned. However, if a Query against a local secondary index causes DynamoDB
to fetch item attributes from the base table, the maximum size of the data in the
results might be lower. In this case, the result size is the sum of:
-
The size of the matching items in the index, rounded up to the next 4 KB.
-
The size of each matching item in the base table, with each item individually rounded up to the next 4 KB.
Using this formula, the maximum size of the results returned by a Query operation is still 1 MB.
For example, consider a table where the size of each item is 300 bytes. There is a
local secondary index on that table, but only 200 bytes of each item is projected into the index.
Now suppose that you Query this index, that the query requires table
fetches for each item, and that the query returns 4 items. DynamoDB sums up the
following:
-
The size of the matching items in the index: 200 bytes × 4 items = 800 bytes; this is then rounded up to 4 KB.
-
The size of each matching item in the base table: (300 bytes, rounded up to 4 KB) × 4 items = 16 KB.
The total size of the data in the result is therefore 20 KB.
Write capacity units
When an item in a table is added, updated, or deleted, updating the local secondary indexes consumes provisioned write capacity units for the table. The total provisioned throughput cost for a write is the sum of write capacity units consumed by writing to the table and those consumed by updating the local secondary indexes.
The cost of writing an item to a local secondary index depends on several factors:
-
If you write a new item to the table that defines an indexed attribute, or you update an existing item to define a previously undefined indexed attribute, one write operation is required to put the item into the index.
-
If an update to the table changes the value of an indexed key attribute (from A to B), two writes are required: one to delete the previous item from the index and another write to put the new item into the index.
-
If an item was present in the index, but a write to the table caused the indexed attribute to be deleted, one write is required to delete the old item projection from the index.
-
If an item is not present in the index before or after the item is updated, there is no additional write cost for the index.
All of these factors assume that the size of each item in the index is less than or equal to the 1 KB item size for calculating write capacity units. Larger index entries require additional write capacity units. You can minimize your write costs by considering which attributes your queries need to return and projecting only those attributes into the index.
Storage considerations for Local Secondary Indexes
When an application writes an item to a table, DynamoDB automatically copies the correct subset of attributes to any local secondary indexes in which those attributes should appear. Your Amazon account is charged for storage of the item in the base table and also for storage of attributes in any local secondary indexes on that table.
The amount of space used by an index item is the sum of the following:
-
The size in bytes of the base table primary key (partition key and sort key)
-
The size in bytes of the index key attribute
-
The size in bytes of the projected attributes (if any)
-
100 bytes of overhead per index item
To estimate the storage requirements for a local secondary index, you can estimate the average size of an item in the index and then multiply by the number of items in the index.
If a table contains an item where a particular attribute is not defined, but that attribute is defined as an index sort key, then DynamoDB does not write any data for that item to the index.
Item collections in Local Secondary Indexes
Note
This section pertains only to tables that have local secondary indexes.
In DynamoDB, an item collection is any group of items that have the
same partition key value in a table and all of its local secondary indexes. In the
examples used throughout this section, the partition key for the Thread
table is ForumName, and the partition key for LastPostIndex is
also ForumName. All the table and index items with the same
ForumName are part of the same item collection. For example, in the
Thread table and the LastPostIndex local secondary index, there is an item
collection for forum EC2 and a different item collection for forum
RDS.
The following diagram shows the item collection for forum S3.
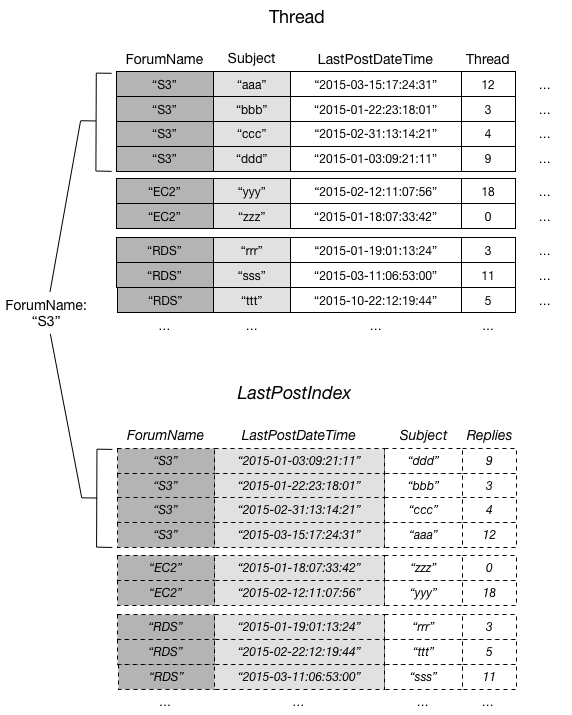
In this diagram, the item collection consists of all the items in Thread
and LastPostIndex where the ForumName partition key value is
"S3". If there were other local secondary indexes on the table, any items in those
indexes with ForumName equal to "S3" would also be part of the item
collection.
You can use any of the following operations in DynamoDB to return information about item collections:
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
Each of these operations supports the ReturnItemCollectionMetrics
parameter. When you set this parameter to SIZE, you can view information
about the size of each item collection in the index.
Example
The following is an example from the output of an UpdateItem
operation on the Thread table, with
ReturnItemCollectionMetrics set to SIZE. The item that
was updated had a ForumName value of "EC2", so the output includes
information about that item collection.
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
The SizeEstimateRangeGB object shows that the size of this item
collection is between 0 and 1 GB. DynamoDB periodically updates this size estimate, so
the numbers might be different next time the item is modified.
Item collection size limit
The maximum size of any item collection for a table which has one or more local secondary indexes is 10 GB. This does not apply to item collections in tables without local secondary indexes, and also does not apply to item collections in global secondary indexes. Only tables that have one or more local secondary indexes are affected.
If an item collection exceeds the 10 GB limit, DynamoDB may return an
ItemCollectionSizeLimitExceededException, and you may not be able to
add more items to the item collection or increase the sizes of items that are in the
item collection. (Read and write operations that shrink the size of the item
collection are still allowed.) You can still add items to other item
collections.
To reduce the size of an item collection, you can do one of the following:
-
Delete any unnecessary items with the partition key value in question. When you delete these items from the base table, DynamoDB also removes any index entries that have the same partition key value.
-
Update the items by removing attributes or by reducing the size of the attributes. If these attributes are projected into any local secondary indexes, DynamoDB also reduces the size of the corresponding index entries.
-
Create a new table with the same partition key and sort key, and then move items from the old table to the new table. This might be a good approach if a table has historical data that is infrequently accessed. You might also consider archiving this historical data to Amazon Simple Storage Service (Amazon S3).
When the total size of the item collection drops below 10 GB, you can once again add items with the same partition key value.
We recommend as a best practice that you instrument your application to monitor
the sizes of your item collections. One way to do so is to set the
ReturnItemCollectionMetrics parameter to SIZE whenever
you use BatchWriteItem, DeleteItem, PutItem,
or UpdateItem. Your application should examine the
ReturnItemCollectionMetrics object in the output and log an error
message whenever an item collection exceeds a user-defined limit (8 GB, for
example). Setting a limit that is less than 10 GB would provide an early
warning system so you know that an item collection is approaching the limit in time
to do something about it.
Item collections and partitions
In a table with one or more local secondary indexes, each item collection is stored in one partition. The total size of such an item collection is limited to the capability of that partition: 10 GB. For an application where the data model includes item collections which are unbounded in size, or where you might reasonably expect some item collections to grow beyond 10 GB in the future, you should consider using a global secondary index instead.
You should design your applications so that table data is evenly distributed across distinct partition key values. For tables with local secondary indexes, your applications should not create "hot spots" of read and write activity within a single item collection on a single partition.