SPARQL federated queries in Neptune using the SERVICE extension
Amazon Neptune fully supports the SPARQL federated query extension that uses the
SERVICE keyword. (For more information, see SPARQL 1.1 Federated
Query
The SERVICE keyword instructs the SPARQL query engine to execute a
portion of the query against a remote SPARQL endpoint and compose the final query result. Only
READ operations are possible. WRITE and DELETE
operations are not supported. Neptune can only run federated queries against SPARQL endpoints
that are accessible within its virtual private cloud (VPC). However, you can also use
a reverse proxy in the VPC to make an external data source accessible within the VPC.
Note
When SPARQL SERVICE is used to federate a query to two or more
Neptune clusters in the same VPC, the security groups must be configured to allow
all those Neptune clusters to talk to each another.
Important
SPARQL 1.1 Federation makes service requests on your behalf when passing queries and parameters to external SPARQL endpoints. It is your responsibility to verify that the external SPARQL endpoints satisfy your application's data handling and security requirements.
Example of a Neptune federated query
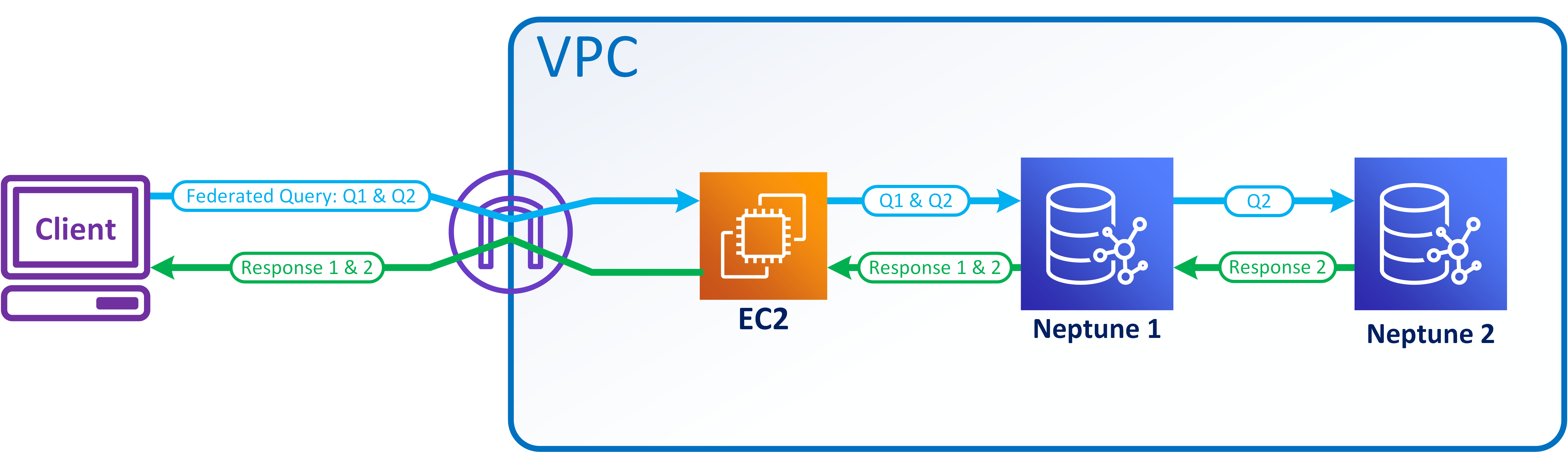
The following simple example shows how SPARQL federated queries work.
Suppose that a customer sends the following query to Neptune-1 at
http://neptune-1:8182/sparql.
SELECT * WHERE { ?person rdf:type foaf:Person . SERVICE <http://neptune-2:8182/sparql> { ?person foaf:knows ?friend . } }
Neptune-1 evaluates the first query pattern (Q-1) which is
?person rdf:type foaf:Person, uses the results to resolve?personin Q-2 (?person foaf:knows ?friend), and forwards the resulting pattern to Neptune-2 athttp://neptune-2:8182/sparql.Neptune-2 evaluates Q-2 and sends the results back to Neptune-1.
Neptune-1 joins the solutions for both patterns and sends the results back to the customer.
This flow is shown in the following diagram.
Note
"By default, the optimizer determines at what point in query execution that the
SERVICE instruction is executed. You can override this placement using the
joinOrder
query hint.
Access control for federated queries in Neptune
Neptune uses Amazon Identity and Access Management (IAM) for authentication and authorization. Access control for a federated query can involve more than one Neptune DB instance. These instances might have different requirements for access control. In certain circumstances, this can limit your ability to make a federated query.
Consider the simple example presented in the previous section. Neptune-1 calls Neptune-2 with the same credentials it was called with.
If Neptune-1 requires IAM authentication and authorization, but Neptune-2 does not, all you need is appropriate IAM permissions for Neptune-1 to make the federated query.
If Neptune-1 and Neptune-2 both require IAM authentication and authorization, you need to attach IAM permissions for both databases to make the federated query. Both clusters must also be in the same Amazon account and in the same region. Cross-region and/or cross-account federated query architectures are not currently supported.
However, in the case where Neptune-1 is not IAM-enabled but Neptune-2 is, you can't make a federated query. The reason is that Neptune-1 can't retrieve your IAM credentials and pass them on to Neptune-2 to authorize the second part of the query.