将 Auto Scaling 用于 Amazon Glue
自动扩缩现在可用于使用 Amazon Glue 版本 3.0 或更高版本的 Amazon Glue ETL、交互式会话和流作业。
启用 Auto Scaling 后,您将获得以下优势:
-
Amazon Glue 将根据各个阶段的并行性或任务运行的微批处理,向集群中自动添加工件,以及从集群中自动删除工件。
-
这会减少您在为 Amazon Glue ETL 作业分配工作线程数量时进行试验和决策的需求。
-
在给定的最大工作线程数量下,Amazon Glue 将为工作负载选择适当大小的资源。
-
您可以通过查看 Amazon Glue Studio 中任务运行详细信息页面上的 CloudWatch 指标,了解集群大小在任务运行过程中如何变化。
Amazon Glue ETL 的自动扩缩和流式传输作业可使您的 Amazon Glue 作业的计算资源实现按需横向扩展和横向缩减。按需纵向扩展可帮助您最初只在任务运行启动时分配所需的计算资源,还可以在任务期间根据需求预配所需的资源。
自动扩缩还支持在作业过程中动态横向缩减 Amazon Glue 作业资源。在任务运行过程中,当 Spark 应用程序请求更多执行程序时,将向集群添加更多工件。当执行程序在没有活动计算任务的情况下处于空闲状态时,则将删除该执行程序和相应的工件。
自动扩缩帮助您的 Spark 应用程序降低成本和提高利用率的常见场景包括:
-
Spark 驱动程序在 Amazon S3 中列出大量文件或在执行程序处于非活动状态时执行加载
-
由于过度预置,Spark 阶段仅使用少量执行程序运行
-
数据偏差或 Spark 各阶段间的计算需求不均衡
要求
Auto Scaling 仅适用于 Amazon Glue 版本 3.0 或更高版本。要使用 Auto Scaling,您可以按照迁移指南将现有任务迁移到 Amazon Glue 版本 3.0 或更高版本,或者使用 Amazon Glue 版本 3.0 或更高版本创建新作业。
Auto Scaling 可用于兼有 G.1X、G.2X、G.4X、G.8X、G.12X、G.16X、R.1X、R.2X、R.4X、R.8X 或 G.025X(仅用于流式处理作业)Worker 类型的 Amazon Glue 作业。Auto Scaling 不支持标准 DPU。
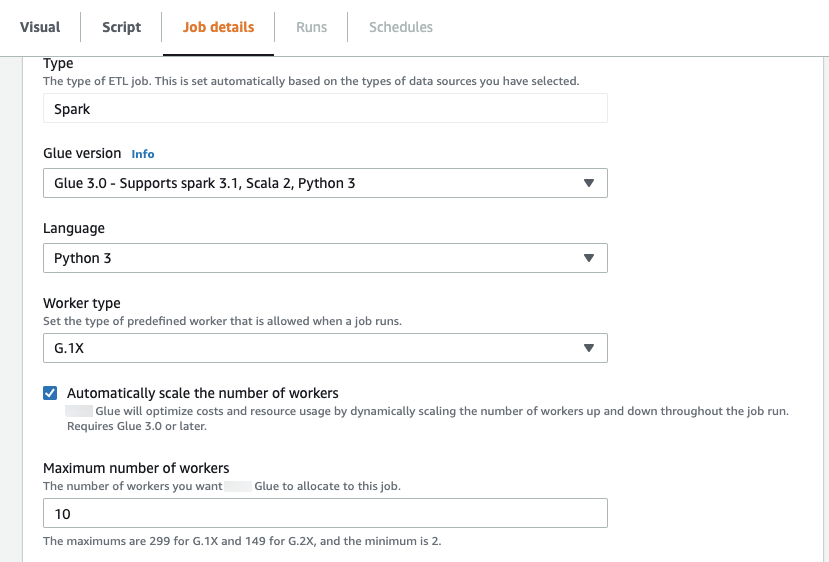
在 Amazon Glue Studio 中启用自动扩缩
在 Amazon Glue Studio 中的作业详细信息选项卡上,将类型选择为 Spark 或 Spark Streaming,并将 Glue 版本选择为 Glue 3.0 或更高版本。随后将在工作线程类型下方出现一个复选框。
-
选择 Automatically scale the number of workers(自动扩展工件数量)选项。
-
设置 Maximum number of workers(最大工件数量)以定义可提供给任务运行的最大工件数量。
使用 Amazon CLI 或开发工具包启用自动扩缩
要通过 Amazon CLI 为作业运行启用自动扩缩,请使用以下配置运行 start-job-run:
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
在 ETL 任务运行完成后,您还可以调用 get-job-run 以检查 DPU-seconds 内任务运行的实际资源使用情况。注意:新字段 DPUSeconds 仅针对启用了自动扩缩的 Amazon Glue 4.0 或更高版本上的批处理作业显示。流式处理任务不支持此字段。
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
您还可以使用具有相同配置的 Amazon Glue 开发工具包配置启用自动扩缩的任务运行。
使用交互式会话启用自动扩缩
要在构建 Amazon Glue 作业时使用交互式会话启用自动扩缩,请参阅 Configuring Amazon Glue interactive sessions。
提示和注意事项
微调 Amazon Glue 自动扩缩的提示和注意事项:
-
如果您不确定最大工作线程数量的初始值,则可以从估算 Amazon Glue DPU 中解释的粗略计算开始。对于数据量非常小的情况,不应配置过大的最大工作线程数值。
-
Amazon Glue 自动扩缩根据作业中配置的最大 DPU 数量(使用最大工作线程数量和工作线程类型计算)来配置
spark.sql.shuffle.partitions和spark.default.parallelism。如果您希望在这些配置中使用固定值,则可以使用以下作业参数覆盖这些参数:-
键:
--conf -
值:
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
对于流式传输作业,默认情况下,Amazon Glue 不会在微批次内自动扩缩,并且需要多个微批才能启动自动扩缩。如果您想在微批次内启用自动扩缩,请提供
--auto-scale-within-microbatch。有关更多信息,请参阅作业参数参考。
使用 Amazon CloudWatch 指标监控 Auto Scaling
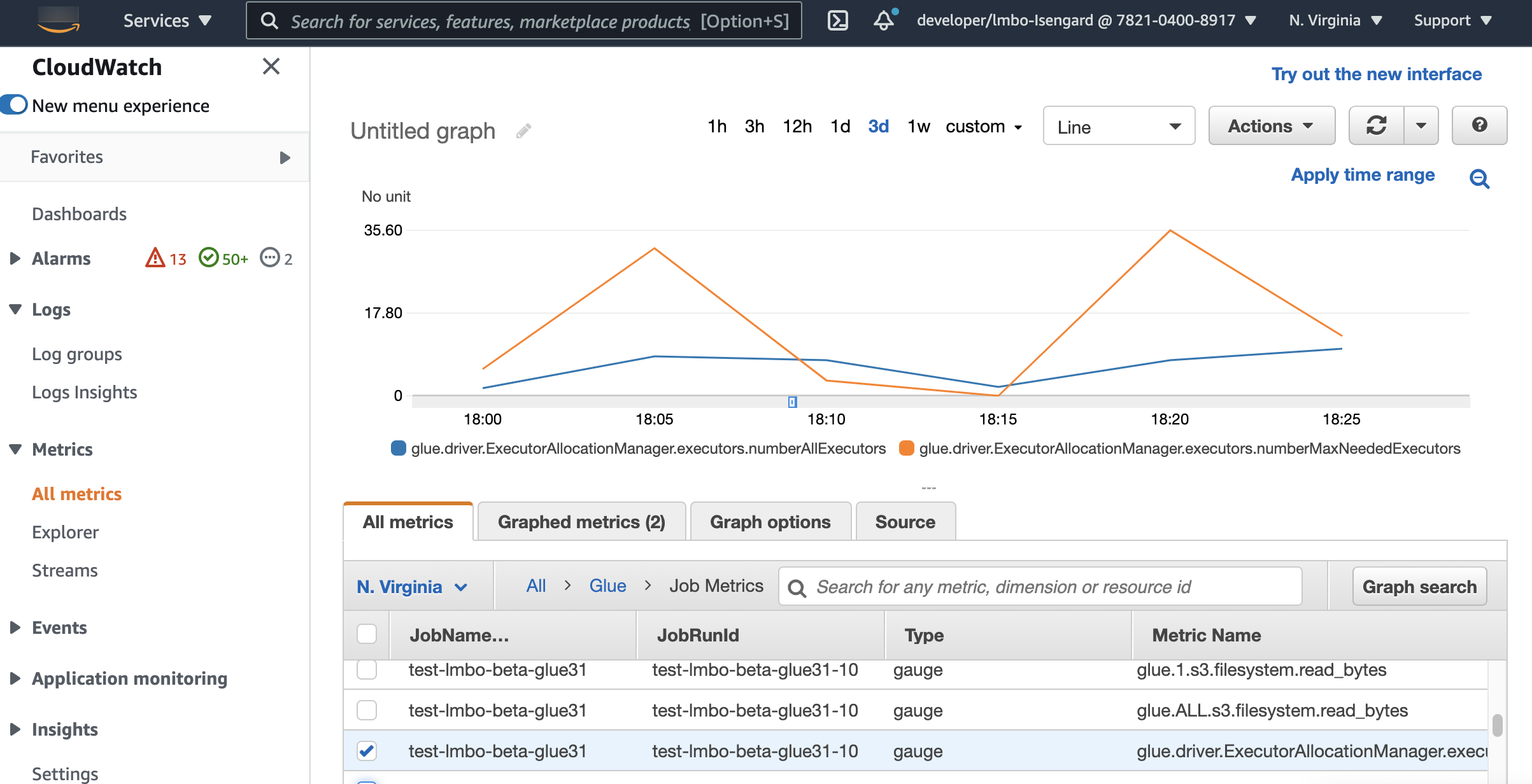
如果您启用了 Auto Scaling,则 CloudWatch 执行程序指标可用于您的 Amazon Glue 3.0 或更高版本任务。这些指标可以用于监控使用 Auto Scaling 启用的 Spark 应用程序中执行程序的需求和优化使用情况。有关更多信息,请参阅 使用 Amazon CloudWatch 指标监控 Amazon Glue。
您还可以利用 Amazon Glue 可观测性指标来深入了解资源利用率。例如,通过监控 glue.driver.workerUtilization,您可以监控在使用和不使用自动扩缩时实际分别使用了多少资源。再举一个例子,通过监控 glue.driver.skewness.job 和 glue.driver.skewness.stage,您可以了解数据的偏差情况。这些见解将帮助您决定是否启用自自动扩缩并微调配置。有关更多信息,请参阅使用 使用 Amazon Glue 可观测性指标进行监控进行监控。
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors
-
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
有关这些指标的更多详细信息,请参阅 监控 DPU 容量规划。
注意
CloudWatch 执行程序指标不可用于交互式会话。
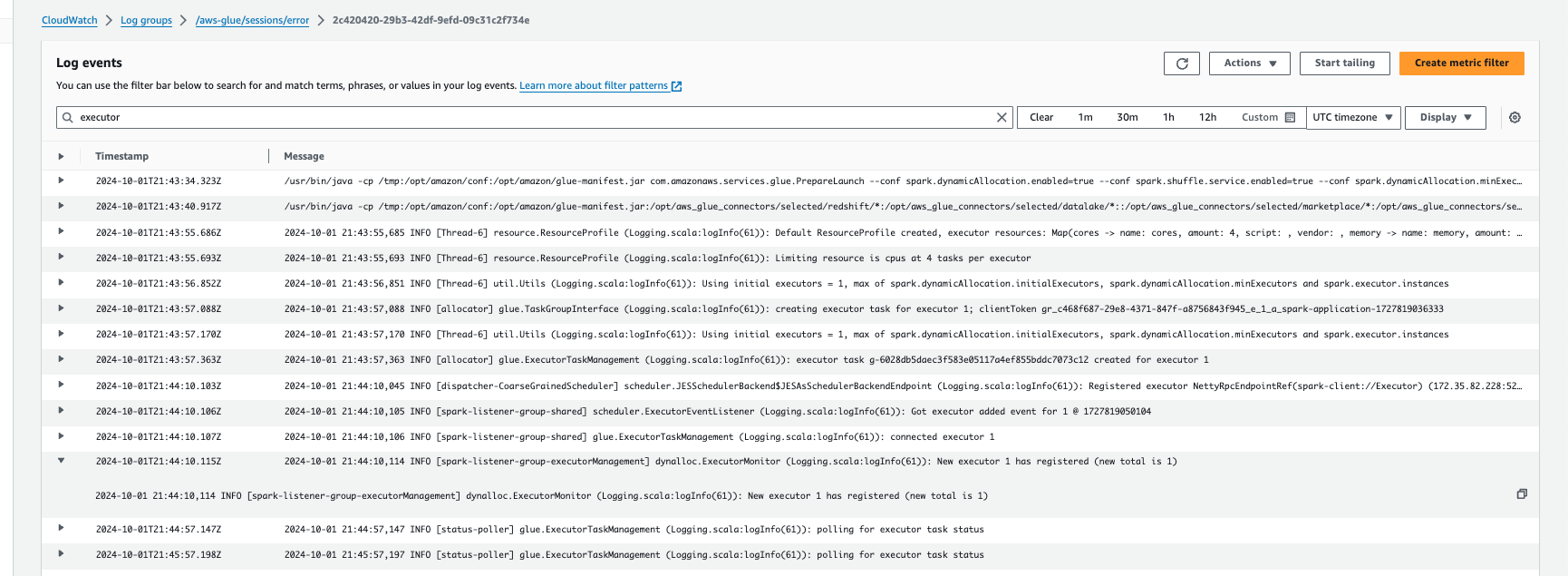
使用 Amazon CloudWatch Logs 监控自动扩缩
如果您使用交互式会话,则可以通过启用连续的 Amazon CloudWatch Logs 并在日志中搜索“executor”,或者使用 Spark UI 来监控执行程序的数量。为此,请使用 %%configure 指令来启用连续日志记录并 enable auto scaling。
%%configure{ "--enable-continuous-cloudwatch-log": "true", "--enable-auto-scaling": "true" }
在 Amazon CloudWatch 日志事件中,在日志中搜索“executor”:
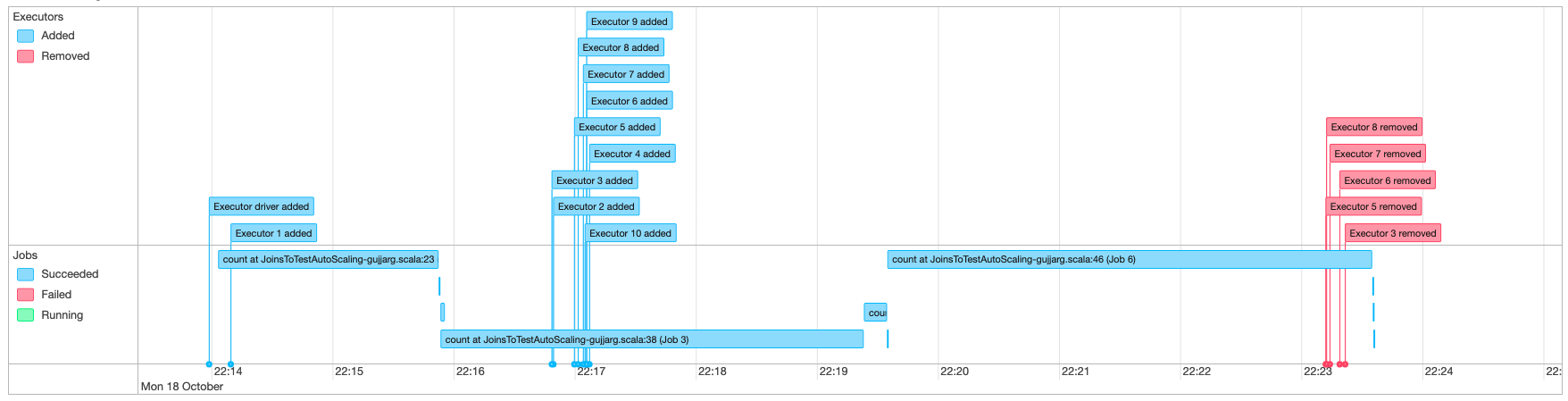
使用 Spark UI 监控 Auto Scaling
启用 Auto Scaling 后,您还可以使用 Glue Spark UI 监控根据 Amazon Glue 任务中的需求借助动态纵向扩展及缩减添加和删除的执行程序。有关更多信息,请参阅 为 Amazon Glue 作业启用 Apache Spark Web UI。
当您使用 Jupyter Notebook 中的交互式会话时,您可以运行以下指令来启用自动扩缩和 Spark UI:
%%configure{ "--enable-auto-scaling": "true", "--enable-continuous-cloudwatch-log": "true" }
监控弹性伸缩任务运行的 DPU 使用情况
您可以使用 Amazon Glue Studio 作业运行视图以检查自动扩缩作业的 DPU 使用情况。
-
从 Amazon Glue Studio 导航窗格中选择监控。此时将显示 Monitoring(监控)页面。
-
向下滚动到任务运行图表。
-
导航到您感兴趣的任务运行,然后滚动到 DPU 小时列以检查特定任务运行的使用情况。
限制
Amazon Glue 串流 Auto Scaling 目前不支持串流 DataFrame 与在 ForEachBatch 外部创建的静态 DataFrame 联接。在 ForEachBatch 内部创建的静态 DataFrame 将按预期方式工作。