教程:在 Amazon Glue for Ray 中编写 ETL 脚本
重要
Amazon Glue for Ray 不再向新客户开放。现有客户可以继续正常使用该服务。有关更多信息,请参阅 Amazon Glue for Ray 终止支持。
Ray 让您能够在 Python 中以原生方式编写和扩展分布式任务。Amazon Glue for Ray 提供无服务器 Ray 环境,您可以从作业和交互式会话中访问这些环境(Ray 交互式会话以预览形式提供)。Amazon Glue 作业系统提供了一种一致的方式来管理和运行任务,可以按计划、通过触发器或 Amazon Glue 控制台执行任务。
结合使用这些 Amazon Glue 工具可创建功能强大的工具链,可用于提取、转换、加载(ETL)工作负载,这是 Amazon Glue 的一种受欢迎的用例。在本教程中,您将学习组合此解决方案的基础知识。
我们还支持将 for Spark Amazon Glue 用于您的 ETL 工作负载。有关编写 Amazon Glue for Spark 脚本的教程,请参阅 教程:编写 Amazon Glue for Spark 脚本。有关可用引擎的更多信息,请参阅 Amazon Glue for Spark 和 Amazon Glue for Ray。Ray 能够处理分析、机器学习(ML)和应用程序开发中的许多不同类型的任务。
在本教程中,您将提取、转换和加载一个托管在 Amazon Simple Storage Service(Amazon S3)中的 CSV 数据集。您将首先使用纽约市出租车和豪华轿车委员会(TLC)行程记录数据集,该数据集存储在一个公开的 Amazon S3 存储桶中。有关该数据集的更多信息,请参阅 Registry of Open Data on Amazon
您将使用 Ray Data 库中提供的预定义转换来转换数据。Ray Data 是一个由 Ray 设计的数据集准备库,默认包含在 Amazon Glue for Ray 环境中。有关默认情况下包含库的更多信息,请参阅 Ray 作业提供的模块。然后,将转换后的数据写入由您控制的 Amazon S3 存储桶。
先决条件 - 在本教程中,您需要一个有权访问 Amazon Glue 和 Amazon S3 的 Amazon 账户。
第 1 步:在 Amazon S3 中创建一个存储桶来保存您的输出数据
您需要一个由您控制的 Amazon S3 存储桶,以用作本教程中创建的数据的接收器。您可以按照以下步骤创建此存储桶。
注意
如果您想将数据写入由您控制的现有存储桶,则可以跳过此步骤。记下 yourBucketName(现有存储桶的名称),以便在后续步骤中使用。
为 Ray 作业输出创建存储桶
-
按照《Amazon S3 用户指南》中创建存储桶中的步骤创建存储桶。
-
选择存储桶名称时,请记下
yourBucketName,您将在后续步骤中参考该名称。 -
对于其他配置,Amazon S3 控制台中提供的建议设置在本教程中应该可以正常工作。
例如,Amazon S3 控制台中的存储桶创建对话框可能如下所示。
-
第 2 步:为 Ray 作业创建 IAM 角色
您的作业将需要一个具有以下内容的 Amazon Identity and Access Management(IAM)角色:
-
AWSGlueServiceRole托管式策略授予的权限。这些是运行 Amazon Glue 作业所需的基本权限。 -
针对
nyc-tlc/*Amazon S3 资源的Read访问级别权限。 -
针对
yourBucketName/*Write访问级别权限。 -
一种允许
glue.amazonaws.com主体担任角色的信任关系。
您可以按照以下步骤创建此角色。
为您的 Amazon Glue for Ray 作业创建 IAM 角色
注意
您可以按照许多不同的步骤创建 IAM 角色。有关如何预置 IAM 资源的更多信息或选项,请参阅 Amazon Identity and Access Management 文档。
-
按照《IAM 用户指南》中使用可视化编辑器创建 IAM 策略(控制台)中的步骤,创建定义前面概述的 Amazon S3 权限的策略。
-
选择服务时,请选择 Amazon S3。
-
为策略选择权限时,请为以下资源(如前所述)附加以下几组操作:
-
针对
nyc-tlc/*Amazon S3 资源的读取访问级别权限。 -
针对
yourBucketName/*
-
-
选择策略名称时,请记下
YourPolicyName,您将在后续步骤中参考该名称。
-
-
按照《IAM 用户指南》中为 Amazon 服务(控制台)创建角色中的步骤,为您的 Amazon Glue for Ray 作业创建角色。
-
选择可信 Amazon 服务实体,请选择
Glue。这将自动填充您的作业所需的信任关系。 -
为权限策略选择策略时,请附加以下策略:
-
AWSGlueServiceRole -
YourPolicyName
-
-
选择角色名称时,请记下
YourRoleName,您将在后续步骤中参考该名称。
-
第 3 步:创建并运行 Amazon Glue for Ray 作业
在此步骤中,您将使用 Amazon Web Services 管理控制台 创建 Amazon Glue 作业,为其提供示例脚本,然后运行该作业。创建作业时,它会在控制台中创建一个位置供您存储、配置和编辑 Ray 脚本。有关创建任务的信息,请参阅 在 Amazon 控制台中管理 Amazon Glue 作业。
本教程将介绍以下 ETL 场景:您需要从纽约市 TLC行程记录数据集中读取 2022 年 1 月的记录,通过合并现有列中的数据向数据集添加一个新列(tip_rate),然后移除某些当前分析无关的列,最后将结果写入 yourBucketName。以下 Ray 脚本执行以下步骤:
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
创建并运行 Amazon Glue for Ray 作业
-
在 Amazon Web Services 管理控制台 中,导航到 Amazon Glue 登录页面。
-
在侧面的导航窗格中,选择 ETL 作业。
-
在创建作业中,选择 Ray 脚本编辑器,然后选择创建,如下图所示。
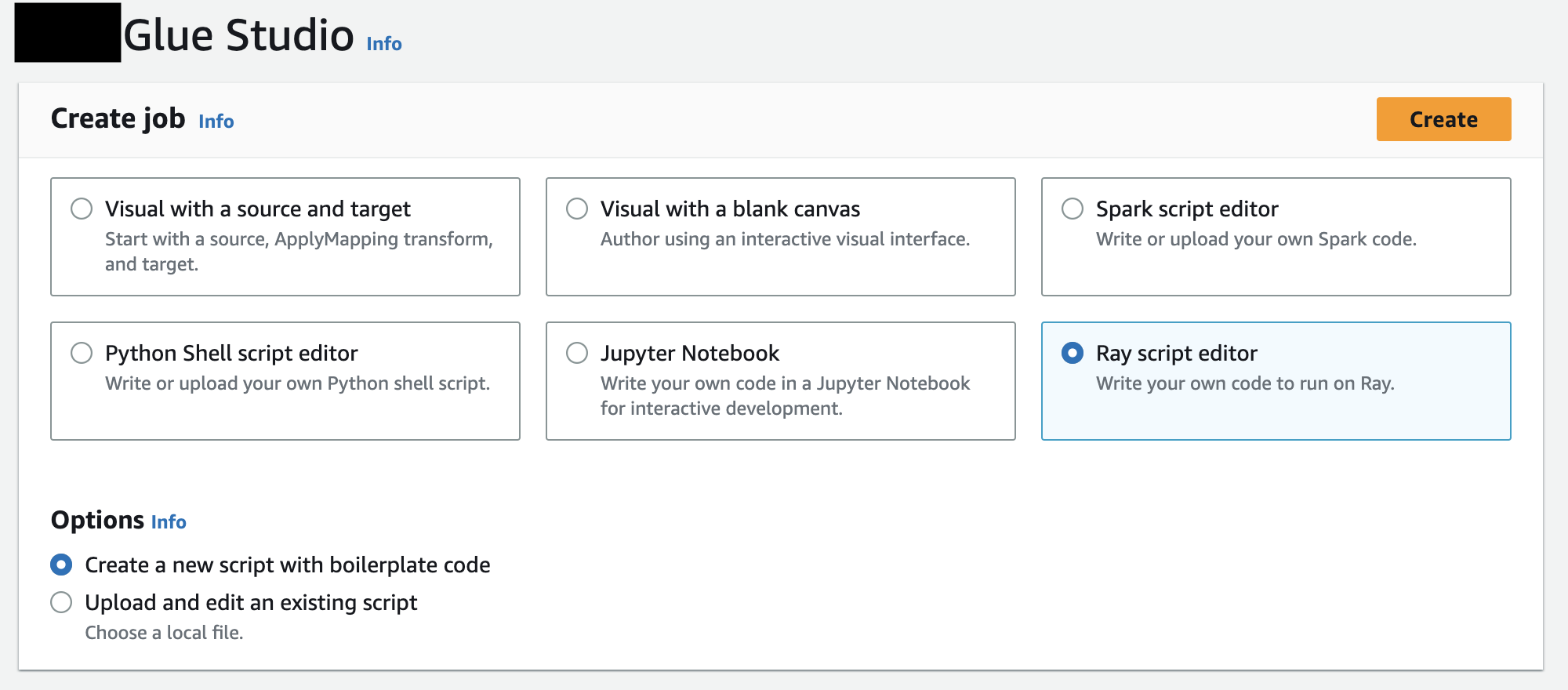
-
将脚本的全文粘贴到脚本窗格中,然后替换所有现有文本。
-
导航到任务详细信息,然后将 IAM 角色属性设置为
YourRoleName。 -
选择保存,然后选择运行。
第 4 步:检查输出
运行 Amazon Glue 作业后,您应验证输出是否符合此场景的预期。可以使用以下步骤来做到这一点。
验证您的 Ray 作业是否成功运行
-
在作业详细信息页面上,导航到运行。
-
几分钟后,您应该会看到运行状态为成功的运行。
-
通过 https://console.aws.amazon.com/s3/
导航到 Amazon S3 控制台,然后检查 yourBucketName。您应该会看到写入输出存储桶的文件。 -
读取 Parquet 文件并验证其内容。您可以用您现有的工具来做到这一点。如果您没有验证 Parquet 文件的流程,则可以在 Amazon Glue 控制台中使用 Spark 或 Ray(预览版)通过 Amazon Glue 交互式会话完成此操作。
在交互式会话中,您可以访问 Ray Data、Spark 或 Pandas 库,这些库是默认提供的(取决于您选择的引擎)。要验证文件内容,您可以使用这些库中可用的常用检查方法,例如
count、schema和show。有关控制台中交互式会话的更多信息,请参阅 Using notebooks with Amazon Glue Studio and Amazon Glue。由于您已确认文件已写入存储桶,因此可以相对肯定地说,如果您的输出有问题,则它们与 IAM 配置无关。使用
yourRoleName配置您的会话以访问相关文件。
如果您看不到预期结果,请查看本指南中的故障排除内容,找出并修复错误的根源。您可以在 排除 Amazon Glue 问题 章节中找到故障排除的内容。有关与 Ray 作业相关的特定错误,请参阅故障排除章节中的 对日志中的 Amazon Glue for Ray 错误进行故障排除。
后续步骤
现在,您已经看到并执行了使用 Amazon Glue for Ray 的端到端的 ETL 过程。您可以使用以下资源来了解 Amazon Glue for Ray 提供了哪些工具来大规模转换和解释数据。
-
有关 Ray 任务模型的更多信息,请参阅 在 Amazon Glue for Ray 中使用 Ray Core 和 Ray Data。要获得使用 Ray 任务的更多体验,请按照 Ray Core 文档中的示例进行操作。请参阅 Ray 文档中的 Ray Core: Ray Tutorials and Examples (2.4.0)
。 -
有关 Amazon Glue for Ray 中可用数据管理库的指南,请参阅 连接 Ray 作业中的数据。要获得使用 Ray Data 转换和写入数据集的更多经验,请按照 Ray Data 文档中的示例进行操作。请参阅 Ray Data: Examples (2.4.0)
。 -
有关配置 Amazon Glue for Ray 作业的更多信息,请查阅 在 Amazon Glue 中处理 Ray 作业。
-
有关编写 Amazon Glue for Ray 脚本的更多信息,请继续阅读文档的本节。