经过仔细考虑,我们决定停用适用于 SQL 应用程序的 Amazon Kinesis Data Analytics:
1. 从 2025年9月1日起,我们将不再为适用于SQL应用程序的Amazon Kinesis Data Analytics Data Analytics提供任何错误修复,因为鉴于即将停产,我们对其的支持将有限。
2. 从 2025 年 10 月 15 日起,您将无法为 SQL 应用程序创建新的 Kinesis Data Analytics。
3. 从 2026 年 1 月 27 日起,我们将删除您的应用程序。您将无法启动或操作 Amazon Kinesis Data Analytics for SQL 应用程序。从那时起,将不再提供对 Amazon Kinesis Data Analytics for SQL 的支持。有关更多信息,请参阅 Amazon Kinesis Data Analytics for SQL 应用程序停用。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
示例:交错窗口
当窗口化查询处理每个唯一分区键的单独窗口时,从具有匹配键的数据到达时开始,该窗口被称为交错窗口。有关更多信息,请参阅 交错窗口。此 Amazon Kinesis Data Analytics 示例使用 EVENT_TIME 和 TICKER 列创建交错窗口。源流包含具有相同 EVENT_TIME 和 TICKER 值的六个记录组成的组,这些值在一分钟时间内到达,但不一定具有相同的分钟值(例如 18:41:xx)。
在本示例中,您在以下时间将以下记录写入到 Kinesis 数据流中。该脚本不会将时间写入流,但应用程序接收记录的时间将写入 ROWTIME 字段:
{"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:17:30 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:17:40 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:17:50 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:18:00 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:18:10 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:18:21 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:18:31 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:18:41 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:18:51 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:19:01 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:19:11 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:19:21 ...
然后,你可以在中 Amazon Web Services 管理控制台创建一个 Kinesis Data Analytics 应用程序,将 Kinesis 数据流作为流媒体源。发现过程读取流式传输源中的示例记录,并推断出具有两个列(EVENT_TIME 和 TICKER)的如下所示的应用程序内部架构。
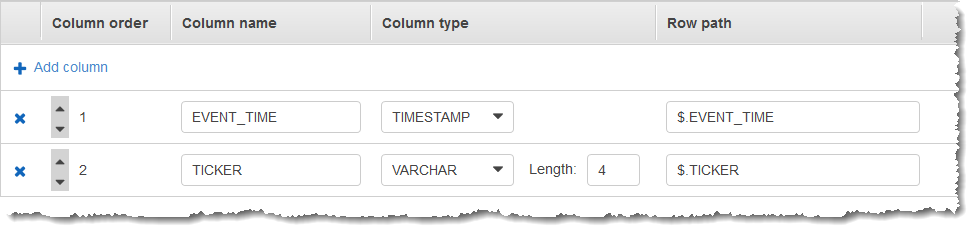
您使用应用程序代码以及 COUNT 函数以创建数据的窗口式聚合。然后,将结果数据插入另一个应用程序内部流,如下面的屏幕截图所示:
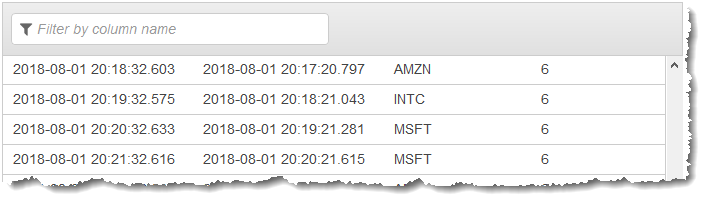
在以下过程中,您创建一个 Kinesis Data Analytics 应用程序,它在基于 EVENT_TIME 和 TICKER 的交错窗口中聚合输入流中的值。
步骤 1:创建 Kinesis 数据流
创建一个 Amazon Kinesis Data Stream 并填充记录,如下所示:
登录 Amazon Web Services 管理控制台 并在 /kinesis 上打开 Kinesis 控制台。https://console.aws.amazon.com
-
在导航窗格中,选择 数据流。
-
选择 创建 Kinesis 流,然后创建具有一个分片的流。有关更多信息,请参阅 Amazon Kinesis Data Streams 开发人员指南中的创建流。
-
要在生产环境中将记录写入到 Kinesis 数据流,我们建议您使用 Kinesis 创建器库或 Kinesis 数据流 API。为简单起见,此示例使用以下 Python 脚本以便生成记录。运行此代码以填充示例股票代码记录。这段简单代码在一分钟时间中连续地将一组六个记录与相同的随机
EVENT_TIME和股票代码符号一起写入流中。让脚本保持运行,以便可以在后面的步骤中生成应用程序架构。import datetime import json import random import time import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): event_time = datetime.datetime.utcnow() - datetime.timedelta(seconds=10) return { "EVENT_TIME": event_time.isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), } def generate(stream_name, kinesis_client): while True: data = get_data() # Send six records, ten seconds apart, with the same event time and ticker for _ in range(6): print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey", ) time.sleep(10) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
步骤 2:创建 Kinesis Data Analytics 应用程序
创建一个 Kinesis Data Analytics 应用程序,如下所示:
在 /kinesisanalytics 上打开适用于 Apache Flink 的托管服务控制台。 https://console.aws.amazon.com
-
选择 创建应用程序,键入应用程序名称,然后选择 创建应用程序。
-
在应用程序详细信息页面上,选择 连接流数据,以连接到源。
-
在 连接到源 页面上,执行以下操作:
-
选择在上一部分中创建的流。
-
选择 发现架构。等待控制台显示推断的架构和为创建的应用程序内部流推断架构所使用的示例记录。推断的架构有两列。
-
选择 编辑架构。将 EVENT_TIME 列的 列类型 更改为
TIMESTAMP。 -
选择 保存架构并更新流示例。在控制台保存架构后,选择 退出。
-
选择 保存并继续。
-
-
在应用程序详细信息页面上,选择 转到 SQL编辑器。要启动应用程序,请在显示的对话框中选择 是,启动应用程序。
-
在 SQL 编辑器中编写应用程序代码并确认结果如下所示:
-
复制下面的应用程序代码并将其粘贴到编辑器中。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( event_time TIMESTAMP, ticker_symbol VARCHAR(4), ticker_count INTEGER); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM EVENT_TIME, TICKER, COUNT(TICKER) AS ticker_count FROM "SOURCE_SQL_STREAM_001" WINDOWED BY STAGGER ( PARTITION BY TICKER, EVENT_TIME RANGE INTERVAL '1' MINUTE); -
选择 保存并运行 SQL。
在 实时分析 选项卡上,可以查看应用程序已创建的所有应用程序内部流并验证数据。
-