经过仔细考虑,我们决定停用适用于 SQL 应用程序的 Amazon Kinesis Data Analytics:
1. 从 2025年9月1日起,我们将不再为适用于SQL应用程序的Amazon Kinesis Data Analytics Data Analytics提供任何错误修复,因为鉴于即将停产,我们对其的支持将有限。
2. 从 2025 年 10 月 15 日起,您将无法为 SQL 应用程序创建新的 Kinesis Data Analytics。
3. 从 2026 年 1 月 27 日起,我们将删除您的应用程序。您将无法启动或操作 Amazon Kinesis Data Analytics for SQL 应用程序。从那时起,将不再提供对 Amazon Kinesis Data Analytics for SQL 的支持。有关更多信息,请参阅 Amazon Kinesis Data Analytics for SQL 应用程序停用。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon Kinesis Data Analytics for SQL 应用程序:工作原理
注意
2023 年 9 月 12 日之后,如果您尚未使用 Kinesis Data Analytics for SQL,则将无法使用 Kinesis Data Firehose 作为来源创建新应用程序。有关更多信息,请参阅限制。
应用程序是可以在您的账户中创建的 Amazon Kinesis Data Analytics 中的主要资源。您可以使用 Amazon Web Services 管理控制台 或 Kinesis Data Analytics API 创建和管理应用程序。Kinesis Data Analytics 提供 API 操作以管理应用程序。有关 API 操作的列表,请参阅操作。
Kinesis Data Analytics 应用程序持续实时读取和处理流数据。您可以使用 SQL 编写应用程序代码来处理传入的流数据并生成输出。然后,Kinesis Data Analytics 会将输出写入到配置的目标中。以下示意图说明典型的应用程序架构。
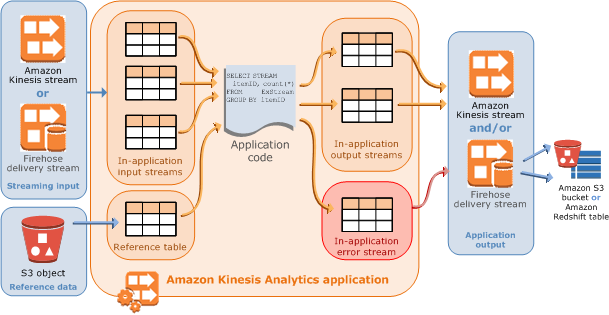
每个应用程序都有名称、描述、版本 ID 和状态。Amazon Kinesis Data Analytics 会在您首次创建应用程序时分配一个版本 ID。在您更新任何应用程序配置时,此版本 ID 会更新。例如,如果您添加输入配置,添加或删除引用数据源,添加或删除输出配置,或者更新应用程序代码,Kinesis Data Analytics 都会更新当前的应用程序版本 ID。另外,Kinesis Data Analytics 也会维护应用程序的创建和上次更新时间戳。
除了这些基本属性外,每个应用程序还包括:
-
Input - 应用程序的流式传输源。您可以选择 Kinesis 数据流或 Firehose 数据传输流作为流式传输源。在输入配置中,您可以将流式传输源映射到应用程序内部输入流。应用程序内部流类似于可以对其执行
SELECT和INSERT SQL操作的连续更新表。在您的应用程序代码中,可以创建其他应用程序内部流来存储中间查询结果。您可以选择将单个流式传输源分区到多个应用程序内部输入流以提高吞吐量。有关更多信息,请参阅限制和配置应用程序输入。
Amazon Kinesis Data Analytics 在每个应用程序流中提供一个名为 时间戳和 ROWTIME 列 的时间戳列。您可以在基于时间的窗口式查询中使用该列。有关更多信息,请参阅 窗口式查询。
您可以选择配置引用数据源,以便丰富您在应用程序中的输入数据流。这会生成应用程序内部引用表。您必须将引用数据存储为 S3 存储桶中的对象。在应用程序启动时,Amazon Kinesis Data Analytics 会读取 Amazon S3 对象并创建应用程序内部表。有关更多信息,请参阅 配置应用程序输入。
-
应用程序代码 - 处理输入和生成输出的一系列 SQL 语句。您可以针对应用程序内部流和引用表编写 SQL 语句。您还可以编写 JOIN 查询以组合来自这两个源的数据。
有关 Kinesis Data Analytics 支持的 SQL 语言元素的信息,请参阅 Amazon Kinesis Data Analytics SQL 参考。
在采用最简单的形式时,应用程序代码可以是单个 SQL 语句,它从流式输入中选择并将结果插入到流式输出中。它还可以是一系列 SQL 语句,将一个 SQL 语句的输出馈送到下一个 SQL 语句的输入。此外,您可以编写应用程序代码以将输入流拆分为多个流。然后,您可以应用其他查询来处理这些流。有关更多信息,请参阅 应用程序代码。
-
输出 - 在应用程序代码中,查询结果将保存到应用程序内部流中。在您的应用程序代码中,您可以创建一个或多个应用程序内部流保存中间结果。然后,您可以选择配置应用程序输出以在应用程序内部流中永久保存数据,而这些应用程序内部流将应用程序输出(也称为应用程序内部输出流)保存到外部目标中。外部目标可以是 Firehose 传输流或 Kinesis 数据流。请注意有关这两种目标的以下信息:
-
您可以配置 Firehose 传输流以将结果写入亚马逊 S3、亚马逊 Redshift 或 OpenSearch 亚马逊服务(服务OpenSearch )。
-
您也可以将应用程序输出写入到自定义目标,而不是 Amazon S3 或 Amazon Redshift。为此,请指定一个 Kinesis 数据流以作为输出配置中的目标。然后,您可以配置 Amazon Lambda 为轮询流并调用您的 Lambda 函数。您的 Lambda 函数代码接收流数据以作为输入。在您的 Lambda 函数代码中,您可以将传入数据写入到自定义目标中。有关更多信息,请参阅Amazon Lambda 与亚马逊 Kinesis Data Analytics 配合使用。
有关更多信息,请参阅 配置应用程序输出。
-
此外,请注意以下情况:
-
Amazon Kinesis Data Analytics 需要具有相应的权限,以从流式传输源中读取记录并将应用程序输出写入到外部目标中。您可以使用 IAM 角色以授予这些权限。
-
Kinesis Data Analytics 自动为每个应用程序提供应用程序内部错误流。如果您的应用程序在处理某些记录时出现问题(例如由于类型不匹配或者到达延迟),记录将写入错误流。您可以配置应用程序输出,以指示 Kinesis Data Analytics 将错误流数据永久保存到外部目标以进行进一步的评估。有关更多信息,请参阅 错误处理。
-
Amazon Kinesis Data Analytics 确保您的应用程序输出记录写入到配置的目标中。它“至少一次”使用处理和传输模型,即使在您遇到应用程序中断的情况下也是如此。有关更多信息,请参阅 将应用程序输出永久保存到外部目标的传输模型。