本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Neptun CloudWatch e 指标
注意
只有当指标的值不为零时,Amazon Neptune CloudWatch 才会向其发送这些指标。
对于所有 Neptune 指标,聚合粒度为 5 分钟。
Neptun CloudWatch e 指标
下表列出了 Neptune 支持的 CloudWatch 指标。
注意
每当服务器重启时,无论是维护、重启还是从崩溃中恢复,所有累积指标都会重置为零。
| 指标 | 说明 | Time Interval | 实例统计 |
|---|---|---|---|
|
为支持 Neptune 数据库集群的备份保留期而使用的备份存储总量(以字节为单位)。包含在 |
||
|
缓冲区缓存提供的请求的百分比。此指标可用于诊断查询延迟,因为缓存未命中会导致严重的延迟。如果缓存命中率低于 99.9%,请考虑升级实例类型以在内存中缓存更多数据。 |
1 minute |
average |
|
对于只读副本,从主实例中复制更新时的滞后总量 (以毫秒为单位)。 |
1 minute |
average |
|
数据库集群中主实例和每个 Neptune 数据库实例之间的最大滞后量(以毫秒为单位)。 |
1 minute |
max/min |
|
数据库集群中主实例和每个 Neptune 数据库实例之间的最小滞后量(以毫秒为单位)。 |
1 minute |
max/min |
|
实例累积的 CPU 积分数,每隔 5 分钟报告一次。您可以使用此指标来确定数据库实例在给定的速率下可以突增至超出其基准性能水平的时长。 |
5 分钟 |
average |
|
在指定时段内消耗的 CPU 积分数,每隔 5 分钟报告一次。此指标标识物理 CPU 在处理虚拟 CPU 分配给数据库实例的指令时所花费的时间。 |
5 分钟 |
average |
|
在 |
5 分钟 |
average |
|
未由获得的 CPU 信用支付并且会产生额外费用的已花费超额信用数。 |
5 分钟 |
average |
|
CPU 使用百分率。 |
1 minute |
average/P99 |
|
实例运行时间长度 (以秒为单位)。 |
1 分钟 |
average |
|
随机存取内存的可用量 (以字节为单位)。 |
1 分钟 |
average |
|
Neptune 全局数据库中从主数据库传输 Amazon Web Services 区域 到辅助 Amazon Web Services 区域 数据库的重做日志数据的字节数。 |
1 分钟 |
average |
|
从全局数据库的主卷复制到辅助数据库 Amazon Web Services 区域 中的群集卷的写入 I/O 操作数 Amazon Web Services 区域。 Neptune 全球数据库中每个数据库集群的账单计算使用 |
5 分钟 |
sum |
|
对于用户事务和系统事务,辅助集群落后于主集群的毫秒数。 |
1 分钟 |
average |
|
Gremlin 遍历中每秒的客户端错误数。 |
1 分钟 |
average |
|
Gremlin 遍历中每秒的服务器端错误数。 |
1 分钟 |
average |
|
每秒对 Gremlin 引擎的请求数。 |
1 分钟 |
average |
|
与 Neptune 的打开 WebSocket 连接数。 |
1 分钟 |
sum |
|
每秒来自加载程序请求的客户端错误数。 |
1 分钟 |
average |
|
每秒的加载程序请求数。 |
1 分钟 |
average |
|
每秒的加载程序服务器端错误数。 |
1 分钟 |
average |
|
在输入队列中等待执行的请求数。当请求超过最大队列容量时,Neptune 会开始限制请求。 |
1 分钟 |
sum |
|
仅适用于 Neptune 无服务器数据库实例或数据库集群。在实例级别,报告按相关实例当前使用的 Neptune 容量单位 (NCU) 数量除以集群的最大 NCU 容量设置计算得出的百分比。NCU 或 Neptune 容量单位由 2GiB 的内存 (RAM) 以及相关的虚拟处理器容量 (vCPU) 和网络组成。 在集群级别, |
||
|
Neptune 数据库集群中每个实例从客户端接收的传入网络吞吐量,以每秒字节数为单位。此吞吐量不 包括数据库集群中的实例与集群卷之间的网络流量。 |
1 分钟 |
average |
|
Neptune 数据库集群中每个实例从客户端接收和发送到客户端的网络吞吐量(以每秒字节数为单位)。此吞吐量不 包括数据库集群中的实例与集群卷之间的网络流量。 |
1 分钟 |
average |
|
Neptune 数据库集群中每个实例发送到客户端的传出网络吞吐量(以每秒字节数为单位)。此吞吐量不 包括数据库集群中的实例与集群卷之间的网络流量。 |
1 分钟 |
average |
NumIndexDeletesPerSec |
从单个索引中删除的次数。从每个索引中删除的次数是单独计算的。这包括在查询遇到错误时可能会被回滚的删除次数。 | 1 分钟 |
average |
NumIndexInsertsPerSec |
单个索引的插入次数。对每个索引的插入次数是单独计算的。这包括在查询遇到错误时可能会被回滚的插入次数。 | 1 分钟 |
average |
NumIndexReadsPerSec |
从任何索引扫描的语句数量。任何访问模式都从搜索索引开始,然后读取所有匹配的语句。此指标的增加可能会导致查询延迟或 CPU 使用率的增加。 | 1 分钟 |
average |
|
每秒排队的请求数。 |
||
|
Gremlin 结果缓存命中次数。 |
1 分钟 |
sum |
|
Gremlin 结果缓存未命中次数。 |
1 分钟 |
sum |
|
每秒成功提交的事务数。 |
1 分钟 |
sum |
|
每秒在服务器上打开的事务数。 |
1 分钟 |
sum |
|
对于写入查询,指的是由于错误每秒在服务器上回滚的事务数。对于只读查询,此指标等于每秒完成的只读事务数。 |
1 分钟 |
sum |
NumUndoPagesPurged |
该指标表明清除的批次数。该指标用于指示清除进度。对于读取器实例,该值为 0,该指标仅适用于写入器实例。 |
1 分钟 |
sum |
|
每秒向 openCypher 引擎发出的请求数(包括 HTTPS 和 Bolt)。 |
1 分钟 |
average |
|
打开的到 Neptune 的 Bolt 连接数。 |
1 分钟 |
sum |
|
Gremlin 结果缓存中所有缓存项目的估计总大小(以字节为单位)。 |
1 分钟 |
sum |
|
Gremlin 结果缓存中的项目数。 |
1 分钟 |
sum |
|
Gremlin 结果缓存中缓存的最旧项目的时间戳。 |
1 分钟 |
sum |
|
Gremlin 结果缓存中缓存的最新项目的时间戳。 |
||
|
作为实例级指标, 在集群级, |
||
|
Neptune 数据库集群的所有快照在其备份保留期之外消耗的备份存储总量(以字节为单位)。包含在 |
1 分钟 |
sum |
|
SPARQL 查询中每秒的客户端错误数。 |
1 分钟 |
average |
|
每秒对 SPARQL 引擎的请求数。 |
1 分钟 |
average |
|
每秒 SPARQL 服务器错误数。 |
1 分钟 |
average |
|
自服务器启动以来扫描 DFE 统计数据的语句总数。 每次触发统计数据计算时,这个数字都会增加,但当没有进行计算时,它会保持静态。因此,如果您将它绘制成一段时间内的曲线,您可以分辨出计算何时发生,什么时候没有: 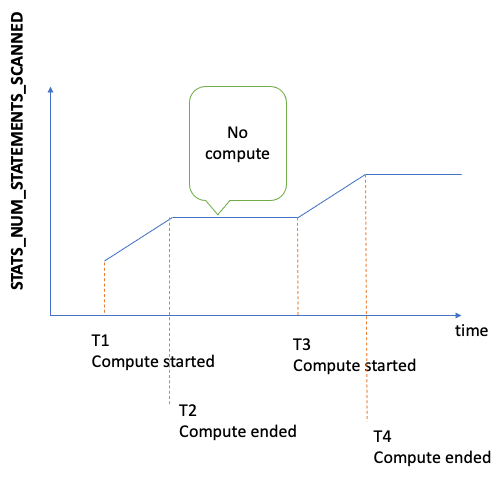
通过查看指标增加期间图形的斜率,您还可以判断计算的速度有多快。 如果没有这样的指标,则意味着您的数据库集群上的统计数据特征已禁用,或者您正在运行的引擎版本没有统计数据特征。如果指标值为零,则表示未进行统计数据计算。 |
1 分钟 |
sum |
|
Neptune 数据库集群中每个实例从存储子系统接收的网络吞吐量。 |
1 分钟 |
average |
StorageNetworkThroughput |
Neptune 数据库集群中每个实例从存储子系统接收以及发送到存储子系统的网络吞吐量。 | 1 分钟 |
average |
|
Neptune 数据库集群中每个实例发送到存储子系统的网络吞吐量。 |
1 分钟 |
average |
|
已使用的交换空间量。 |
1 分钟 |
sum |
|
附属到 Neptune 数据库实例的本地存储上的读写 IOPS 数量。此指标表示计数,每秒测量一次。 |
||
|
与 Neptune 数据库实例关联的本地存储的传入或传出数据量。此指标表示字节数,每秒测量一次。 |
||
|
给定 Neptune 数据库集群的计费备份存储总量(以字节为单位)。包含由 |
1 天 |
sum |
|
每秒从所有源到服务器的请求的总数。 |
1 分钟 |
average |
|
每秒因客户端问题而导致错误的请求的总数。 |
1 分钟 |
average |
|
每秒因内部故障而在服务器端出错的请求的总数。 |
1 分钟 |
average |
|
撤消日志列表中撤消日志的计数。 撤消日志包含已提交事务的记录,当所有活动的事务都比提交时间更晚时,这些已提交事务就会过期。过期的记录会定期清除。删除操作记录的清除时间可能比其它类型事务的记录要长。 清除完全由数据库集群的写入器实例完成,因此清除速率取决于写入器实例类型。如果数据库集群中的 此外,如果您要从早于的版本升级到引擎版本 |
1 分钟 |
sum |
|
集群卷的剩余可用空间,以字节为单位。随着集群卷增长,此值会减小。如果它达到零,集群报告空间不足错误。 如果您想检测您的 Neptune 数据库集群是否接近其大小限制,则监控此值更简单、更可靠。 此指标仅由写入器实例报告。为避免故障转移期间出现中断,请使用群集级别维度 ()。 |
1 分钟 |
average |
|
分配给 Neptune 数据库集群的总存储量(以字节为单位)。这是要计费的存储量。它是在数据库集群存在期间的任何时间点分配给该集群的最大存储量,而不是您当前使用的存储量(请参阅Neptune 存储账单)。 |
5 分钟 |
sum |
|
按集群卷计费的读取 I/O 操作总数,报告间隔为 5 分钟。计费读取操作数是在集群卷级别计算的,从 Neptune 数据库集群中的所有实例聚合而来,然后每隔 5 分钟报告一次。 |
5 分钟 |
sum |
VolumeWriteIOPs |
向集群卷写入磁盘的 I/O 操作总数,每隔 5 分钟报告一次。 |
5 分钟 |
sum |
CloudWatch Neptune 中现已弃用的指标
以下 Neptune 指标现在已弃用。它们仍然受支持,但随着新的更好指标出现,将来可能会被淘汰。
指标 |
说明 |
|---|---|
|
Gremlin 终端节点每秒的 HTTP 1xx 响应的数量。 我们建议您改用新的 |
|
Gremlin 终端节点每秒的 HTTP 2xx 响应的数量。 我们建议您改用新的 |
|
Gremlin 终端节点每秒的 HTTP 4xx 错误的数量。 我们建议您改用新的 |
|
Gremlin 终端节点每秒的 HTTP 5xx 错误的数量。 我们建议您改用新的 |
|
Gremlin 遍历中的错误数量。 |
|
对 Gremlin 引擎的请求数。 |
|
每秒成功 WebSocket 连接到 Gremlin 端点的次数。 |
|
每秒 Gremlin 端点上的 WebSocket 客户端错误数。 |
|
每秒 Gremlin 端点上的 WebSocket 服务器错误数。 |
|
当前可用的潜在 WebSocket 连接数。 |
|
终端节点每秒的 HTTP 100 响应的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 101 响应的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 1xx 响应的数量。 |
|
终端节点每秒的 HTTP 200 响应的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 2xx 响应的数量。 |
|
终端节点每秒的 HTTP 400 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 403 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 405 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 413 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 429 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 4xx 错误的数量。 |
|
终端节点每秒的 HTTP 500 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 501 错误的数量。 我们建议您改用新的 |
|
终端节点每秒的 HTTP 5xx 错误的数量。 |
|
来自加载程序请求的错误数。 |
|
加载程序请求数。 |
|
SPARQL 终端节点每秒的 HTTP 1xx 响应的数量。 我们建议您改用新的 |
|
SPARQL 终端节点每秒的 HTTP 2xx 响应的数量。 我们建议您改用新的 |
|
SPARQL 终端节点每秒的 HTTP 4xx 错误的数量。 我们建议您改用新的 |
|
SPARQL 终端节点每秒的 HTTP 5xx 错误的数量。 我们建议您改用新的 |
|
SPARQL 查询中的错误数。 |
|
对 SPARQL 引擎的请求数。 |
|
来自状态终端节点的错误数。 |
|
对状态终端节点的请求数。 |