本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Neptune 中的数据库克隆
使用数据库克隆,可以快速而经济高效地在 Amazon Neptune 中创建您的所有数据库的克隆。克隆数据库在首次创建时只需要很少的额外空间。数据库克隆使用写入时复制协议。在源数据库或克隆数据库上的数据发生变化时会复制数据。您可以多次克隆同一数据库集群。还可以基于其他克隆来创建更多克隆。有关写入时复制协议在 Neptune 存储上下文中的工作原理的更多信息,请参阅写入时复制。
您可以在很多情况下使用数据库克隆,特别是在您不希望影响生产环境时,例如:
测试并评估更改的影响,例如架构更改或参数组更改。
执行工作负载密集型操作,例如导出数据或运行分析查询。
在非生产环境中为进行开发或测试创建生产数据库集群的副本。
使用 Amazon Web Services 管理控制台创建数据库集群的克隆
登录 Amazon 管理控制台并通过以下网址打开 Amazon Neptune 控制台:https://console.aws.amazon.com/neptune/home
。 在导航窗格中,选择 Instances (实例)。选择要创建克隆的数据库集群的主实例。
选择 Instance actions (实例操作),然后选择 Create clone (创建克隆)。
-
在 Create Clone (创建克隆) 页面上,输入克隆数据库集群的主实例名称作为 DB instance identifier (数据库实例标识符)。
如果需要,配置克隆数据库集群的任何其他设置。有关不同的数据库集群设置的信息,请参阅使用控制台启动。
选择 Create Clone 启动克隆数据库集群。
使用 Amazon CLI创建数据库集群的克隆
-
调用 Neptune restore-db-cluster-to-point-in-time Amazon CLI 命令并提供以下值:
--source-db-cluster-identifier– 要创建克隆的源数据库集群的名称。--db-cluster-identifier– 克隆数据库集群的名称。--restore-type copy-on-write–copy-on-write值指示应创建克隆数据库集群。--use-latest-restorable-time– 它指定应使用最新的可恢复备份时间。
注意
restore-db-cluster-to-point-in-time Amazon CLI 命令仅克隆数据库集群,而不克隆该数据库集群的数据库实例。
以下 Linux/UNIX 示例从
source-db-cluster-id数据库集群创建一个克隆并将该克隆命名为db-clone-cluster-id。aws neptune restore-db-cluster-to-point-in-time \ --region us-east-1 \ --source-db-cluster-identifier source-db-cluster-id \ --db-cluster-identifier db-clone-cluster-id \ --restore-type copy-on-write \ --use-latest-restorable-time如果将
\行尾转义字符替换为 Windows 上的^等效字符,则该示例也适用于 Windows:aws neptune restore-db-cluster-to-point-in-time ^ --region us-east-1 ^ --source-db-cluster-identifier source-db-cluster-id ^ --db-cluster-identifier db-clone-cluster-id ^ --restore-type copy-on-write ^ --use-latest-restorable-time
限制
Neptune 中的数据库克隆具有以下限制:
不能跨 Amazon 区域创建克隆数据库。克隆数据库必须在与源数据库相同的区域中创建。
克隆的数据库始终使用从中克隆的源数据库所用 Neptune 引擎版本的最新补丁。即使源数据库尚未升级到该补丁版本也是如此。不过,引擎版本本身不会改变。
目前,Neptune 数据库集群的每个副本最多只能有 15 个克隆,包括基于其它克隆的克隆。达到该限制后,必须制作数据库的另一个副本,而不是克隆它。但是,如果您制作一个新副本,它也可以有多达 15 个克隆。
目前不支持跨账户数据库克隆。
您可以为克隆提供不同的 Virtual Private Cloud (VPC)。不过,在这些 VPC 中的子网必须映射到同一组可用区。
数据库克隆的写入时复制协议
以下场景说明了写入时复制协议的工作原理。
克隆之前的 Neptune 数据库
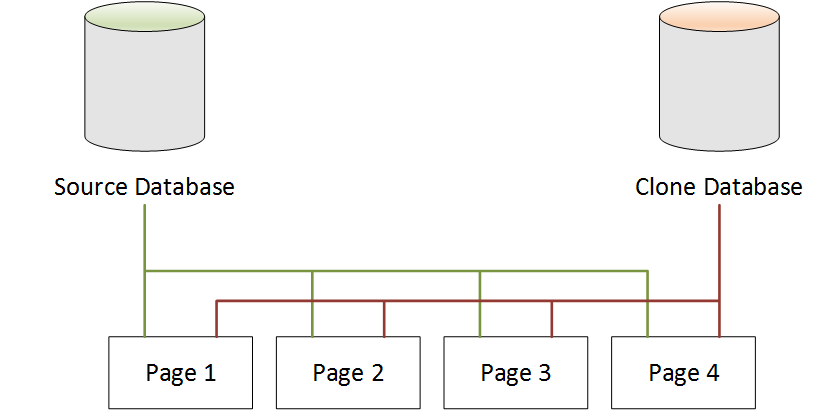
源数据库中的数据以页的形式存储。在下图中,源数据库有四个页面。

克隆之后的 Neptune 数据库
如下图所示,在克隆数据库之后,源数据库中没有更改。源数据库和克隆数据库均指向相同的四个页面。没有物理复制任何页面,因此无需额外的存储。
当对源数据库进行更改时
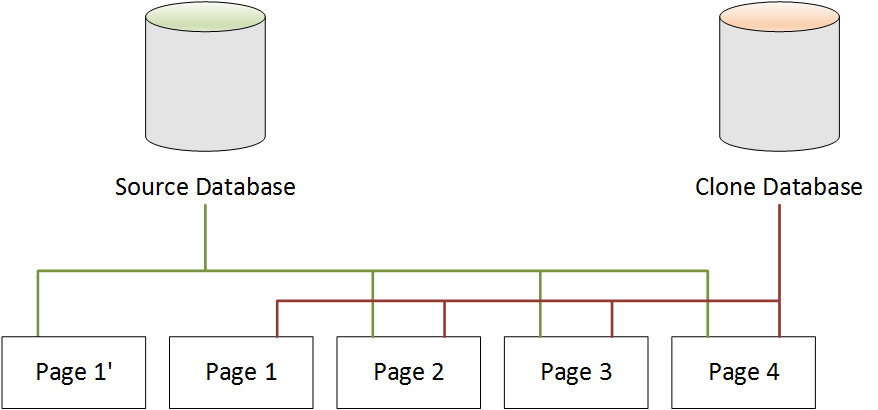
在下面的示例中,源数据库对 Page
1 中的数据进行了更改。它使用额外的存储创建名为 Page 1 的新页,而不是写入原始 Page 1'。源数据库现在指向新 Page 1',也指向Page 2、Page 3 和 Page 4。克隆数据库继续指向 Page 1 到 Page 4。
当对克隆数据库进行更改时
在下图中,克隆数据库还进行了一项更改,这次是在 Page 4 中。使用额外的存储创建名为 Page 4 的新页,而不是写入原始 Page 4'。源数据库继续指向 Page 1',以及 Page 2 到 Page 4,但克隆数据库现在指向 Page 1 到 Page 3,以及 Page 4'。
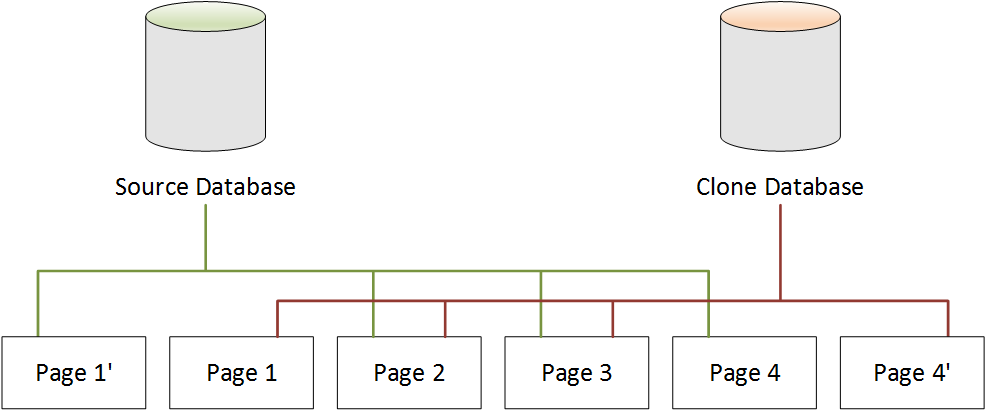
如第二种情况中所示,在数据库克隆之后,创建克隆时无需额外的存储。不过,如第三和第四种情况所示,源数据库和克隆数据库中发生更改之后,将仅创建更改的页面。随着时间推移,当源数据库和克隆数据库上出现了更多更改时,逐渐需要更多存储来捕获和存储更改。
删除源数据库
删除源数据库不会影响与其关联的克隆数据库。克隆数据库继续指向以前由源数据库拥有的页面。