本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon 监控 OpenSearch 集群指标 CloudWatch
亚马逊 OpenSearch 服务会将您的域名中的数据发布到亚马逊 CloudWatch。 CloudWatch 允许您以一组有序的时间序列数据(称为指标)的形式检索有关这些数据点的统计信息。 OpenSearch 服务以 60 秒为间隔向 CloudWatch 发送大多数指标。如果您使用通用型 EBS 卷或磁性 EBS 卷,则 EBS 卷指标将仅每五分钟更新一次。所有累积性指标(例如 ThreadpoolWriteRejected、ThreadpoolSearchRejected)都在内存中,并且会丢失状态。在节点丢弃、节点反弹、节点更换和 blue/green 部署期间,指标将重置。有关亚马逊的更多信息 CloudWatch,请参阅亚马逊 CloudWatch 用户指南。
OpenSearch 服务控制台根据来自的原始数据显示一系列图表 CloudWatch。根据您的需求,您可能更喜欢在中查看集群数据, CloudWatch 而不是在控制台中查看图表。该服务会将指标存档两周,然后再丢弃。这些指标不收取额外费用,但创建仪表板和警报 CloudWatch 仍会收费。有关更多信息,请参阅 Amazon CloudWatch 定价
OpenSearch 服务将以下指标发布到 CloudWatch:
在中查看指标 CloudWatch
CloudWatch 指标首先按服务命名空间分组,然后按每个命名空间内的各种维度组合进行分组。
使用 CloudWatch 控制台查看指标
-
打开 CloudWatch 控制台,网址为https://console.aws.amazon.com/cloudwatch/
。 -
在左侧导航窗格中,找到 Metrics(指标),然后选择 All metrics(所有指标)。选择 E S 命名空间。
-
选择维度以查看相应指标。单个节点的指标位于
ClientId, DomainName, NodeId维度中。集群指标位于Per-Domain, Per-Client Metrics维度中。某些节点指标在集群级别进行聚合,因此包含在这两个维度中。分区指标位于ClientId, DomainName, NodeId, ShardRole维度中。
要查看指标列表,请使用 Amazon CLI
运行如下命令:
aws cloudwatch list-metrics --namespace "AWS/ES"
在 S OpenSearch ervice 中解释健康图表
要在 S OpenSearch ervice 中查看指标,请使用集群运行状况和实例运行状况选项卡。实例运行状况选项卡使用方框图一目了然地了解每个 OpenSearch节点的运行状况:
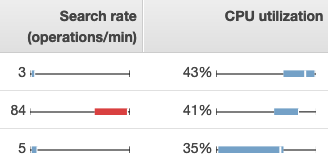
-
每个彩色框显示指定时间段内节点的值范围。
-
蓝框表示与其他节点一致的值。红框表示异常值。
-
每个框中的白线显示节点的当前值。
-
每个框两侧的“细线”显示该时间段内所有节点的最小值和最大值。
如果对您的域进行配置更改,则 Cluster health (集群运行状况) 和 Instance health (实例运行状况) 选项卡中各个实例的列表的大小通常会在短时间内增长一倍,然后再恢复为正确数量。有关此行为的说明,请参阅在 Amazon OpenSearch 服务中进行配置更改。
集群指标
Amazon OpenSearch 服务为集群提供以下指标。
| 指标 | 说明 |
|---|---|
ClusterStatus.green |
值为 1 指示将所有索引分片分配给集群中的节点。 相关统计数据:Maximum |
ClusterStatus.yellow |
值为 1 指示将所有索引的主要分片分配给集群中的节点,但是至少有一个索引的分片副本不是如此。有关更多信息,请参阅 黄色集群状态。 相关统计数据:Maximum |
ClusterStatus.red |
值为 1 指示至少一个索引的主分片和副本分片未分配给集群中的节点。有关更多信息,请参阅 红色集群状态。 相关统计数据:Maximum |
Shards.active |
活动主分区和副本分区的总数。 相关统计数据:最大值、总计 |
Shards.unassigned |
未分配给集群中节点的分区数。 相关统计数据:最大值、总计 |
Shards.delayedUnassigned |
其节点分配因超时设置已延迟的分区数。 相关统计数据:最大值、总计 |
Shards.activePrimary |
活动主分区数。 相关统计数据:最大值、总计 |
Shards.initializing |
正在初始化的分区数。 相关统计数据:总计 |
Shards.relocating |
正在重新定位的分区数。 相关统计数据:总计 |
Nodes |
OpenSearch 服务集群中的节点数量,包括专用主节点和温节点。有关更多信息,请参阅 在 Amazon OpenSearch 服务中进行配置更改。 相关统计数据:Maximum |
SearchableDocuments |
跨集群中所有数据节点的可搜索文档的总数。 相关统计数据:最小值、最大值、平均值 |
DeletedDocuments |
跨集群的所有数据节点已标记为删除的文档总数。这些文档不再出现在搜索结果中, OpenSearch 只会在段合并期间从磁盘中删除已删除的文档。此指标在提出删除请求后会增加,在分段合并后会减少。 相关统计数据:最小值、最大值、平均值 |
CPUUtilization |
集群中数据节点的 CPU 利用率百分比。最大值显示 CPU 利用率最高的节点。平均值表示集群中的所有节点。此指标也可用于单独的节点。 相关统计数据:Maximum、Average |
FreeStorageSpace |
集群中各数据节点的可用空间。 OpenSearch 服务控制台以 GiB 为单位显示此值。Amazon CloudWatch 控制台以 MiB 为单位显示它。 注意
相关统计数据:Minimum、Maximum、Average、Sum |
ClusterUsedSpace |
集群的已使用空间总量。您必须保留一分钟的时间来获取准确值。 OpenSearch 服务控制台以 GiB 为单位显示此值。Amazon CloudWatch 控制台以 MiB 为单位显示它。 相关统计数据:Minimum、Maximum |
ClusterIndexWritesBlocked |
指示您的集群是接受还是阻止传入的写入请求。值为 0 表示集群接受请求。值为 1 表示阻止请求。 一些常见的因素包括: 相关统计数据:Maximum |
JVMMemoryPressure |
用于集群中所有数据节点的 Java 堆的最大百分比。 OpenSearch 服务将实例内存的一半用于 Java 堆,堆大小不超过 32 GiB。您最多可以将实例的 RAM 垂直扩展至 64GiB,此时可以通过添加实例水平扩展。请参阅Amazon OpenSearch 服务的推荐 CloudWatch 警报。 相关统计数据:Maximum 注意在服务软件 R20220323 中更改了此指标的逻辑。有关更多信息,请参阅版本注释。 |
OldGenJVMMemoryPressure |
集群中所有数据节点上用于“上一代”的 Java 堆的最大百分比。此指标也在节点级别获取。 相关统计数据:Maximum |
AutomatedSnapshotFailure |
集群的失败的自动快照的数量。值 相关统计数据:Minimum、Maximum |
CPUCreditBalance |
集群中的数据节点可用的剩余 CPU 积分。一个 CPU 信用提供一个完整 CPU 核心性能一分钟。有关更多信息,请参阅 Amazon EC2 开发人员指南中的 CPU 组。此指标仅对 T2 实例类型有效。 相关统计数据:Minimum |
OpenSearchDashboardsHealthyNodes |
OpenSearch 仪表板的运行状况检查。如果最小值、最大值和平均值都等于 1,则控制面板运行正常。如果您有 10 个节点,最大值为 1,最小值为 0,平均值为 0.7,则意味着 7 个节点 (70%) 运行正常,3 个节点 (30%) 运行状况不佳。 相关统计数据:最小值、最大值、平均值 |
OpensearchDashboardsReportingFailedRequestSysErrCount |
由于服务器问题或功能限制而失败的生成 OpenSearch 仪表板报告的请求数。 相关统计数据:总计 |
OpensearchDashboardsReportingFailedRequestUserErrCount |
由于客户端问题而失败的生成 OpenSearch 仪表板报告的请求数。 相关统计数据:总计 |
OpensearchDashboardsReportingRequestCount |
生成 OpenSearch 控制面板报告的请求总数。 相关统计数据:总计 |
OpensearchDashboardsReportingSuccessCount |
成功请求生成 OpenSearch 仪表板报告的次数。 相关统计数据:总计 |
KMSKeyError |
值为 1 表示用于加密静态数据的密 Amazon KMS 钥已被禁用。要将域还原为正常操作,请重新启用该密钥。控制台仅对该加密静态数据的域显示此指标。 相关统计数据:Minimum、Maximum |
KMSKeyInaccessible |
值为 1 表示用于加密静态数据的 Amazon KMS 密钥已被删除或撤销其对 Serv OpenSearch ice 的授权。您无法恢复处于此状态的域。但如果您具有手动快照,则可以使用它将该域的数据迁移到新域。控制台仅对该加密静态数据的域显示此指标。 相关统计数据:Minimum、Maximum |
InvalidHostHeaderRequests |
向 OpenSearch 集群发出的包含无效(或缺失)主机标头的 HTTP 请求数。有效的请求包括域主机名作为主机标头值。 OpenSearch 对于没有限制性访问策略的公共访问域,Service 会拒绝无效请求。我们建议对所有域应用限制性访问策略。 如果您看到此指标的较大值,请确认您的 OpenSearch 客户端在其请求中包含域主机名(例如,而不是其 IP 地址)。 相关统计数据:总计 |
OpenSearchRequests (previously
ElasticsearchRequests) |
向 OpenSearch 集群发出的请求数。 相关统计数据:总计 |
TLSNegotiationError |
客户端和域端点之间失败的 TLS 握手尝试次数。当客户端尝试使用不支持的 TLS 版本或密码套件进行连接时,该指标会增加。 相关统计数据:总计 |
2xx, 3xx, 4xx, 5xx |
导致指定的 HTTP 响应代码(2xx、3xx、4xx、5xx)的对域的请求数。 相关统计数据:总计 |
ThroughputThrottle |
指示磁盘是否受到节流。当 有关实例吞吐量的更多信息,请参阅 Amazon EBS 优化的实例。有关卷吞吐量的信息,请参阅 Amazon EBS 卷类型 相关统计数据:Minimum、Maximum |
IopsThrottle |
表示域上的每秒 input/output 操作数 (IOPS) 是否已受到限制。当数据节点的 IOPS 违反数据节点上 EBS 卷或 EC2 实例的最大允许限制时,就会发生节流。 有关实例 IOPS 的信息,请参阅 Amazon EBS 优化的实例。有关卷 IOPS 的信息,请参阅 Amazon EBS 卷类型 相关统计数据:Minimum、Maximum |
HighSwapUsage |
值为 1 表示页面错误引起的交换可能会在特定时间段内导致底层磁盘使用量激增。 相关统计数据:Maximum |
专用主节点指标
Amazon OpenSearch 服务为专用主节点提供以下指标。
| 指标 | 说明 |
|---|---|
MasterCPUUtilization |
专用主节点使用的 CPU 资源的最大百分比。建议在此指标达到 60% 时增加实例类型的大小。 相关统计数据:Maximum |
MasterFreeStorageSpace |
此指标不相关,可以被忽略。该服务不使用主节点作为数据节点。 |
MasterJVMMemoryPressure |
用于集群中所有专用主节点的 Java 堆的最大百分比。建议在此指标达到 85% 时迁移到更大的实例类型。 相关统计数据:Maximum 注意在服务软件 R20220323 中更改了此指标的逻辑。有关更多信息,请参阅版本注释。 |
MasterOldGenJVMMemoryPressure |
每个主节点上用于“上一代”的 Java 堆的最大百分比。 相关统计数据:Maximum |
MasterCPUCreditBalance |
集群中专用主节点可用的剩余 CPU 积分。一个 CPU 信用提供一个完整 CPU 核心性能一分钟。有关更多信息,请参阅 Amazon EC2 开发人员指南中的 CPU 组。此指标仅对 T2 实例类型有效。 相关统计数据:Minimum |
MasterReachableFromNode |
失败意味着无法从源节点访问主节点。它们通常是网络连接问题或 Amazon 依赖问题造成的。 相关统计数据:Maximum |
MasterSysMemoryUtilization |
使用中的主节点内存的百分比。 相关统计数据:Maximum |
专用协调器节点指标
Amazon S OpenSearch ervice 为专用协调器节点提供以下指标。
| 指标 | 说明 |
|---|---|
CoordinatorCPUUtilization |
专用协调器节点使用的 CPU 资源的最大百分比。建议在此指标达到 80% 时增加实例类型的大小。 相关统计数据:Maximum |
CoordinatorJVMMemoryPressure |
用于集群中所有专用协调器节点的 Java 堆的最大百分比。建议在此指标达到 85% 时迁移到更大的实例类型。 相关统计数据:Maximum |
CoordinatorOldGenJVMMemoryPressure |
每个主节点上用于“上一代”的 Java 堆的最大百分比。 相关统计数据:Maximum |
CoordinatorSysMemoryUtilization |
使用中的协调器节点内存的百分比。 相关统计数据:Maximum |
CoordinatorFreeStorageSpace |
该指标指示服务未将协调器节点作为数据节点使用。 |
EBS 卷指标
Amazon OpenSearch 服务为 EBS 卷提供了以下指标。
| 指标 | 说明 |
|---|---|
ReadLatency |
EBS 卷上读取操作的延迟(以秒为单位)。此指标也可用于单独的节点。 相关统计数据:最小值、最大值、平均值 |
WriteLatency |
EBS 卷上写入操作的延迟(以秒为单位)。此指标也可用于单独的节点。 相关统计数据:最小值、最大值、平均值 |
ReadThroughput |
EBS 卷上读取操作的吞吐量(以字节/秒为单位)。此指标也可用于单独的节点。 相关统计数据:最小值、最大值、平均值 |
ReadThroughputMicroBursting |
考虑微爆 相关统计数据:最小值、最大值、平均值 |
WriteThroughput |
EBS 卷上写入操作的吞吐量(以字节/秒为单位)。此指标也可用于单独的节点。 相关统计数据:最小值、最大值、平均值 |
WriteThroughputMicroBursting |
考虑微爆 相关统计数据:最小值、最大值、平均值 |
DiskQueueDepth |
EBS 卷的待处理输入和输出 (I/O) 请求数。 相关统计数据:最小值、最大值、平均值 |
ReadIOPS |
每秒对 EBS 卷进行读取操作的输入和输出 (I/O) 操作数。此指标也可用于单独的节点。 相关统计数据:最小值、最大值、平均值 |
ReadIOPSMicroBursting |
考虑微爆 相关统计数据:最小值、最大值、平均值 |
WriteIOPS |
每秒对 EBS 卷进行写入操作的输入和输出 (I/O) 操作数。此指标也可用于单独的节点。 相关统计数据:最小值、最大值、平均值 |
WriteIOPSMicroBursting |
考虑微爆 相关统计数据:最小值、最大值、平均值 |
BurstBalance |
EBS 卷在突发存储桶中剩余的输入和输出 (I/O) 积分的百分比。值为 100 表示该卷积累的积分数量已达最大数量。如果此百分比低于 70%,请参阅 EBS 可爆发容量余额低。对于具有 gp3 卷类型的域以及具有卷大小超过 1000 GiB 的 gp2 卷的域,突增余额保持在 0。 相关统计数据:最小值、最大值、平均值 |
VolumeStalledIOcheck |
EBS 卷的状态,用于确定卷何时受损。该指标是一个二进制值,根据 EBS 卷能否完成输入和输出操作返回 0(通过)或 1(失败)状态。 相关统计数据:最小值、最大值、平均值 |
实例指标
Amazon OpenSearch 服务为域中的每个实例提供以下指标。 OpenSearch 服务还会汇总这些实例指标,以深入了解集群的整体运行状况。您可以使用控制台中的 Sample Count(样本数)统计数据验证此行为。请注意,下表中的每个指标对于节点 和 集群都有相关的统计数据。
重要
Elasticsearch 的不同版本使用不同的线程池来处理对 _index API 的调用。Elasticsearch 1.5 和 2.3 使用索引线程池。Elasticsearch 5 x、6.0 和 6.2 使用批量线程池。 OpenSearch 而 Elasticsearch 6.3 及更高版本则使用写线程池。目前, OpenSearch 服务控制台不包含批量线程池的图表。
使用 GET _cluster/settings?include_defaults=true 来检查集群的线程池和队列大小。
| 指标 | 说明 |
|---|---|
FetchLatency |
节点中所有分片提取操作所用的总时间差(以毫秒为单位),介于 N 分钟和(N-1)分钟之间。 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
FetchRate |
数据节点上所有分片每分钟进行的分片提取操作总数。 相关节点统计数据:Average 相关集群统计数据:Average、Maximum、Sum |
ScrollTotal |
数据节点上所有分片每分钟进行的分片滚动操作总数。 相关节点统计数据:Average、Maximum 相关集群统计数据:Average、Maximum、Sum |
ScrollCurrent |
当前正在运行的分片滚动操作数量。 相关节点统计数据:Average、Maximum 相关集群统计数据:Average、Maximum、Sum |
OpenContexts |
打开的搜索上下文数量。 相关节点统计数据:Average、Maximum 相关集群统计数据:Average、Maximum、Sum |
ThreadCount |
该 OpenSearch 进程当前正在使用的线程总数。 相关节点统计数据:Average、Maximum 相关集群统计数据:Average、Maximum、Sum |
ShardReactivateCount |
从空闲状态激活所有分片的总次数。 相关节点统计数据:Sum、Maximum 相关集群统计数据:Sum、Maximum |
ConcurrentSearchRate |
数据节点上所有分片每分钟使用并发分段搜索的搜索请求总数。对 相关节点统计数据:Average 相关集群统计数据:Average、Maximum、Sum |
ConcurrentSearchLatency |
在分钟 N 到 minute () 之间的节点中使用并发分段搜索进行的所有搜索所得的总时间差,以毫秒为单位。N-1 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
IndexingLatency |
节点中所有索引操作所用的总时间差,以毫秒为单位,介于分钟 N 和 minute () 之间。N-1 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
IndexingRate |
每分钟的索引操作数。对 相关节点统计数据:Average 相关集群统计数据:Average、Maximum、Sum |
SearchLatency |
节点中所有搜索的总时间差,以毫秒为单位,介于分钟 N 和 minute () 之间。N-1 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
SearchRate |
数据节点上所有分片的每分钟搜索请求总数。对 相关节点统计数据:Average 相关集群统计数据:Average、Maximum、Sum |
SegmentCount |
数据节点上的分段数。您拥有的区段越多,每次搜索所需的时间就越长。 OpenSearch 偶尔会将较小的片段合并为一个较大的片段。 相关节点统计数据:最大值、平均值 相关集群统计数据:Sum、Maximum、Average |
SysMemoryUtilization |
使用中的实例内存的百分比。此指标的值较高是正常的,通常不表示集群存在问题。有关潜在性能和稳定性问题的更好指示,请参阅 相关节点统计数据:Minimum、Maximum、Average 相关集群统计数据:Minimum、Maximum、Average |
JVMGCYoungCollectionCount |
“年轻代”垃圾回收的运行次数。大量不断增长的运行数对于集群操作来说是正常的。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
JVMGCYoungCollectionTime |
集群执行“年轻代”垃圾回收所花费的时间,以毫秒为单位。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
JVMGCOldCollectionCount |
“年老代”垃圾回收的运行次数。在具有足够资源的集群中,此数字应保持很小并且不会频繁增长。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
JVMGCOldCollectionTime |
集群执行“年老代”垃圾回收所花费的时间,以毫秒为单位。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
OpenSearchDashboardsConcurrentConnections |
与 OpenSearch仪表板的活跃并发连接数。如果此数字始终很高,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
OpenSearchDashboardsHealthyNode |
单个 OpenSearch 仪表板节点的运行状况检查。值为 1 表示行为正常。值为 0 表示无法访问控制面板。 相关节点统计数据:最小值 相关集群统计数据:Minimum、Maximum、Average |
OpenSearchDashboardsHeapTotal |
分配给 OpenSearch 仪表板的堆内存量,以 MiB 为单位。不同的 EC2 实例类型可能会影响精确的内存分配。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
OpenSearchDashboardsHeapUsed |
OpenSearch 仪表板使用的绝对堆内存量,以 MiB 为单位。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
OpenSearchDashboardsHeapUtilization |
OpenSearch仪表板使用的可用堆内存的最大百分比。如果此值超过 80%,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Minimum、Maximum、Average |
OpenSearchDashboardsOS1MinuteLoad |
OpenSearch 仪表板一分钟 CPU 平均负载。理想情况下,CPU 负载应保持在 1.00 以下。虽然临时峰值很好,但如果此指标始终高于 1.00,我们建议增加实例类型的大小。 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
OpenSearchDashboardsRequestTotal |
向 OpenSearch 控制面板发出的 HTTP 请求总数。如果您的系统速度较慢,或者您看到大量的控制面板请求,请考虑增加实例类型的大小。 相关节点统计数据:总计 相关集群统计数据:Sum |
OpenSearchDashboardsResponseTimesMaxInMillis |
OpenSearch 仪表板响应请求所需的最大时间(以毫秒为单位)。如果请求一直花费很长时间才能返回结果,请考虑增加实例类型的大小。 相关节点统计数据:Maximum 相关集群统计数据:最大值、平均值 |
SearchTaskCancelled |
协调器节点取消的次数。 相关节点统计数据:总计 相关集群统计数据:Sum |
SearchShardTaskCancelled |
数据节点取消的次数。 相关节点统计数据:总计 相关集群统计数据:Sum |
ThreadpoolForce_mergeQueue |
强制合并线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
ThreadpoolForce_mergeRejected |
强制合并线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
ThreadpoolForce_mergeThreads |
强制合并线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolIndexQueue |
索引线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。索引队列的最大大小为 200。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
ThreadpoolIndexRejected |
索引线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
ThreadpoolIndexThreads |
索引线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolSearchQueue |
搜索线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。搜索队列的最大大小为 1000。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
ThreadpoolSearchRejected |
搜索线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
ThreadpoolSearchThreads |
搜索线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
Threadpoolsql-workerQueue |
SQL 搜索线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
Threadpoolsql-workerRejected |
SQL 搜索线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
Threadpoolsql-workerThreads |
SQL 搜索线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolBulkQueue |
批量线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
ThreadpoolBulkRejected |
批量线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
ThreadpoolBulkThreads |
批量线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolIndexSearcherQueue |
索引搜索器线程池中已排队的任务数。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
ThreadpoolIndexSearcherRejected |
索引搜索器线程池中已拒绝的任务数。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
ThreadpoolIndexSearcherThreads |
索引搜索器线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolWriteThreads |
写入线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolWriteQueue |
写入线程池中的排队任务数。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
ThreadpoolWriteRejected |
写入线程池中的已拒绝任务数。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum 注意由于在 7.1 版本中,默认写入队列大小从 200 增加到 10000,因此该指标不再是服务拒绝的唯一指标。 OpenSearch 使用 |
CoordinatingWriteRejected |
自上次启动 OpenSearch 服务进程以来,由于索引压力,协调节点上发生的拒绝总数。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum 此指标在版本 7.1 及更高版本中可用。 |
PrimaryWriteRejected |
自上次启动 OpenSearch 服务进程以来,由于索引压力,主分片上发生的拒绝总数。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum 此指标在版本 7.1 及更高版本中可用。 |
ReplicaWriteRejected |
自上次启动 OpenSearch 服务进程以来,由于索引压力,副本分片上发生的拒绝总数。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum 此指标在版本 7.1 及更高版本中可用。 |
WorkloadManagementEnabled |
指示工作负载管理功能是否已启用。值为 1 表示已启用,值为 0 表示 相关节点统计数据:Maximum、Minimum 相关集群统计数据:Average、Sum 此指标在版本 7.1 及更高版本中可用。 |
SoftQueryGroupCount |
域中软模式下的查询组数量。 相关节点统计数据:Average、Maximum 相关集群统计数据:Average、Maximum、Sum 此指标在版本 7.1 及更高版本中可用。 |
EnforcedQueryGroupCount |
域中强制模式下的查询组数量。 相关节点统计数据:Average、Maximum 相关集群统计数据:Average、Maximum、Sum 此指标在版本 7.1 及更高版本中可用。 |
温暖指标
Amazon OpenSearch 服务为Multi-tier 存储架构提供了以下指标 UltraWarm
注意
与热索引相关的指标仅适用于 Multi-tier 存储架构
| 指标 | 说明 |
|---|---|
WarmIndexingLatency
|
热节点中所有索引操作在分钟 N 和 minute () 之间的总时间差,以毫秒为单位。N-1 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
WarmIndexingRate
|
每分钟在 warm 上执行的索引操作数。对 相关节点统计数据:Average 相关集群统计数据:Average、Maximum、Sum |
WarmThreadpoolIndexingQueue
|
索引线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。索引队列的最大大小为 200。 相关节点统计数据:Maximum 相关集群统计数据:Average、Maximum、Sum |
WarmThreadpoolIndexingRejected
|
索引线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
WarmThreadpoolIndexingThreads
|
索引线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
WarmCPUUtilization |
集群中温节点的 CPU 使用率百分比。最大值显示 CPU 利用率最高的节点。平均值表示集群中的所有温节点。此指标也适用于单个温节点。 相关统计数据:Maximum、Average |
WarmFreeStorageSpace |
以 MiB 为单位的可用温存储空间量。由于 Warm 使用 Amazon S3 而不是连接的磁盘, 相关统计数据:总计 |
WarmSearchableDocuments |
跨集群中所有温索引的可搜索文档总数。您必须保留一分钟的时间来获取准确值。 相关统计数据:总计 |
WarmSearchLatency
|
在 N 分钟和分钟 () 之间,在 Warm 中所有搜索所得的总时间差,以毫秒为单位。N-1 相关节点统计数据:Average 相关集群统计数据:Average、Maximum |
WarmSearchRate
|
温节点上所有分片每分钟搜索请求的总数。对 相关节点统计数据:Average 相关集群统计数据:Average、Maximum、Sum |
WarmStorageSpaceUtilization |
集群使用的温存储空间总量。 相关统计数据:Maximum |
HotStorageSpaceUtilization
|
集群使用的热存储空间总量。 相关统计数据:Maximum |
WarmSysMemoryUtilization |
使用中的温节点内存的百分比。 相关统计数据:Maximum |
HotToWarmMigrationQueueSize
|
当前等待从热存储迁移到温存储的索引数。 相关统计数据:Maximum |
WarmToHotMigrationQueueSize
|
当前等待从温存储迁移到热存储的索引数。 相关统计数据:Maximum |
HotToWarmMigrationFailureCount
|
从热迁移到温迁移失败的总数。此指标仅适用于 UltraWarm 节点。 相关统计数据:总计 |
HotToWarmMigrationForceMergeLatency
|
迁移过程的强制合并阶段的平均延迟时间。如果此阶段持续时间过长,请考虑增加。此指标仅适用于 UltraWarm 节点。 相关统计数据:Average |
HotToWarmMigrationSnapshotLatency
|
迁移过程快照阶段的平均延迟时间。如果此阶段始终花费太长时间,请确保分区的大小适当,并在整个集群中分布。此指标仅适用于 UltraWarm 节点。 相关统计数据:Average |
HotToWarmMigrationProcessingLatency
|
成功从热迁移到温迁移的平均延迟时间,不包括队列中花费的时间。此值是完成迁移过程的强制合并、快照和分区重新定位阶段所需的时间总和。此指标仅适用于 UltraWarm 节点。 相关统计数据:Average |
HotToWarmMigrationSuccessCount
|
成功从热迁移到温迁移的总数。 相关统计数据:总计 |
HotToWarmMigrationSuccessLatency
|
成功从热迁移到温迁移的平均延迟时间,包括在队列中花费的时间。 相关统计数据:Average |
WarmThreadpoolSearchThreads |
热搜索话题池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Average、Sum |
WarmThreadpoolSearchRejected |
热搜索线程池中被拒绝的任务数。如果这个数字持续增长,可以考虑添加更多 Warm 节点。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
WarmThreadpoolSearchQueue |
热搜索线程池中排队的任务数。如果队列大小一直很高,可以考虑添加更多 Warm 节点。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
WarmJVMMemoryPressure |
用于 Warm 节点的 Java 堆的最大百分比。 相关统计数据:Maximum 注意在服务软件 R20220323 中更改了此指标的逻辑。有关更多信息,请参阅版本注释。 |
WarmOldGenJVMMemoryPressure |
每个 Warm 节点用于 “旧一代” 的 Java 堆的最大百分比。 相关统计数据:Maximum |
WarmJVMGCYoungCollectionCount |
“年轻一代” 垃圾收集在 Warm 节点上运行的次数。大量不断增长的运行数对于集群操作来说是正常的。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
WarmJVMGCYoungCollectionTime |
集群在 Warm 节点上执行 “年轻一代” 垃圾收集所花费的时间,以毫秒为单位。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
WarmJVMGCOldCollectionCount |
“旧一代” 垃圾收集在 Warm 节点上运行的次数。在具有足够资源的集群中,此数字应保持很小并且不会频繁增长。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
WarmConcurrentSearchRate |
使用每分钟并发分段搜索的温节点上所有分片的搜索请求总数。对 相关节点统计数据:Average 相关集群统计数据:Sum、Maximum、Average |
WarmConcurrentSearchLatency |
在 Warm 节点中使用并发分段搜索进行的所有搜索所得的总时间差,以毫秒为单位,介于分钟 N 和 minute () 之间。N-1 相关节点统计数据:Average 相关集群统计数据:最大值、平均值 |
WarmThreadpoolIndexSearcherQueue |
热索引搜索器线程池中排队的任务数。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Maximum、Average |
WarmThreadpoolIndexSearcherRejected |
热索引搜索器线程池中被拒绝的任务数。 相关节点统计数据:Maximum 相关集群统计数据:Sum |
WarmThreadpoolIndexSearcherThreads |
热索引搜索器线程池的大小。 相关节点统计数据:Maximum 相关集群统计数据:Sum、Average |
冷存储指标
Amazon OpenSearch 服务提供以下冷存储指标。
| 指标 | 说明 |
|---|---|
ColdStorageSpaceUtilization
|
集群使用的冷存储空间总量,以 MiB 为单位。 相关统计数据:最大值 |
ColdToWarmMigrationFailureCount |
从冷到温迁移失败的总数。 相关统计数据:总计 |
ColdToWarmMigrationLatency |
成功完成冷到温迁移所需的时间量。 相关统计数据:Average |
ColdToWarmMigrationQueueSize |
当前等待从冷存储迁移到温存储的索引数。 相关统计数据:Maximum |
ColdToWarmMigrationSuccessCount
|
成功从冷到温迁移的总数。 相关统计数据:总计 |
WarmToColdMigrationFailureCount
|
从温到冷迁移失败的总数。 相关统计数据:总计 |
WarmToColdMigrationLatency |
成功完成温到冷迁移的时间量。 相关统计数据:Average |
WarmToColdMigrationQueueSize |
当前等待从温存储迁移到冷存储的索引数。 相关统计数据:Maximum |
WarmToColdMigrationSuccessCount |
成功从温到冷迁移的总数。 相关统计数据:总计 |
OpenSearch 优化实例 (OR1) 指标
亚马逊 OpenSearch 服务为 OR1 实例提供以下指标。
| 指标 | 说明 |
|---|---|
RemoteStorageUsedSpace
|
集群使用的 Amazon S3 空间总量(单位为 MiB)。 相关统计数据:总计 |
RemoteStorageWriteRejected |
由于远程存储和复制压力而在主分片上被拒绝的请求总数。这是从上次启动 OpenSearch 服务进程开始计算的。 相关统计数据:总计 |
ReplicationLagMaxTime |
副本分片相比主分片的滞后时间大小(以毫秒为单位)。 相关统计数据:Maximum |
提醒指标
Amazon OpenSearch 服务提供以下警报指标。
| 指标 | 说明 |
|---|---|
AlertingDegraded |
值为 1 表示警报索引为红色,或一个或多个节点未按计划运行。值为 0 表示行为正常。 相关统计数据:Maximum |
AlertingIndexExists |
值为 1 表示 相关统计数据:Maximum |
AlertingIndexStatus.green |
索引的运行状况。值为 1 表示绿色。值为 0 表示索引不存在或不是绿色。 相关统计数据:Maximum |
AlertingIndexStatus.red |
索引的运行状况。值为 1 表示红色。值为 0 表示索引不存在或不是红色。 相关统计数据:Maximum |
AlertingIndexStatus.yellow |
索引的运行状况。值为 1 表示黄色。值为 0 表示索引不存在或不是黄色。 相关统计数据:Maximum |
AlertingNodesNotOnSchedule |
值为 1 表示某些作业未按计划运行。值为 0 表示所有警报作业都按计划运行(或警报作业不存在)。检查 OpenSearch 服务控制台或 相关统计数据:Maximum |
AlertingNodesOnSchedule |
值为 1 表示所有警报作业都按计划运行(或警报作业不存在)。值为 0 表示某些作业未按计划运行。 相关统计数据:Maximum |
AlertingScheduledJobEnabled |
值为 1 表示 相关统计数据:Maximum |
异常检测指标
Amazon OpenSearch 服务提供以下异常检测指标。
| 指标 | 说明 |
|---|---|
ADPluginUnhealthy |
值为 1 表示异常检测插件无法正常工作,或者因为故障次数太多,或者因为它使用了一个红色的索引。值为 0 表示插件正按预期工作。 相关统计数据:Maximum |
ADExecuteRequestCount |
检测异常的请求数。 相关统计数据:总计 |
ADExecuteFailureCount
|
检测异常的失败请求数。 相关统计数据:总计 |
ADHCExecuteFailureCount |
检测高基数探测器异常的失败请求数。 相关统计数据:总计 |
ADHCExecuteRequestCount |
检测高基数探测器异常的请求数。 相关统计数据:总计 |
ADAnomalyResultsIndexStatusIndexExists |
值为 1 表示 相关统计数据:Maximum |
ADAnomalyResultsIndexStatus.red |
值为 1 表示 相关统计数据:Maximum |
ADAnomalyDetectorsIndexStatusIndexExists |
值为 1 表示 相关统计数据:Maximum |
ADAnomalyDetectorsIndexStatus.red |
值为 1 表示 相关统计数据:Maximum |
ADModelsCheckpointIndexStatusIndexExists |
值为 1 表示 相关统计数据:Maximum |
ADModelsCheckpointIndexStatus.red |
值为 1 表示 相关统计数据:Maximum |
异步搜索指标
Amazon OpenSearch 服务为异步搜索提供了以下指标。
异步搜索协调器节点统计数据(每个协调器节点)
| 指标 | 说明 |
|---|---|
AsynchronousSearchSubmissionRate |
过去 1 分钟内提交的异步搜索数。 |
AsynchronousSearchInitializedRate |
过去 1 分钟内初始化的异步搜索数。 |
AsynchronousSearchRunningCurrent |
当前正在运行的异步搜索数。 |
AsynchronousSearchCompletionRate |
过去 1 分钟内成功完成的异步搜索数。 |
AsynchronousSearchFailureRate |
最后一分钟内完成和失败的异步搜索数。 |
AsynchronousSearchPersistRate |
过去 1 分钟内持续存在的异步搜索数。 |
AsynchronousSearchPersistFailedRate |
最后一分钟内失败的异步搜索数。 |
AsynchronousSearchRejected |
自节点启动时间以来拒绝的异步搜索总数。 |
AsynchronousSearchCancelled |
自节点启动时间以来取消的异步搜索总数。 |
AsynchronousSearchMaxRunningTime |
最后一分钟内节点上运行时间最长的异步搜索的持续时间。 |
异步搜索集群统计数据
| 指标 | 说明 |
|---|---|
AsynchronousSearchStoreHealth |
最后一分钟持久化索引 (RED/non-RED) 中存储的运行状况。 |
AsynchronousSearchStoreSize |
过去 1 分钟内跨所有分区的系统索引大小。 |
AsynchronousSearchStoredResponseCount |
过去 1 分钟内系统索引中存储的响应数。 |
Auto-Tune 指标
Amazon OpenSearch 服务提供以下指标Auto-Tune。
| 指标 | 说明 |
|---|---|
AutoTuneChangesHistoryHeapSize |
堆大小调整值的更改历史记录(以 MiB 为单位)。 |
AutoTuneChangesHistoryJVMYoungGenArgs |
JVM YongGen 参数的更改历史记录。 |
AutoTuneFailed |
一个布尔值,用于指示 Auto-Tune 更改是否失败。 |
AutoTuneSucceeded |
一个布尔值,用于指示 Auto-Tune 更改是否成功。 |
AutoTuneValue |
无中断更改的队列更改历史记录(计数)和缓存调整更改历史记录(以 MiB 为单位)。 |
Multi-AZ 使用待机指标
Amazon OpenSearch 服务为待机模式Multi-AZ 提供了以下指标。
Node-level 活动可用区中数据节点的指标
| 指标 | 说明 |
|---|---|
CPUUtilization |
集群中数据节点的 CPU 利用率百分比。最大值显示 CPU 利用率最高的节点。平均值表示集群中的所有节点。此指标也可用于单独的节点。 |
FreeStorageSpace |
集群中各数据节点的可用空间。 OpenSearch 服务控制台以 GiB 为单位显示此值。Amazon CloudWatch 控制台以 MiB 为单位显示它。 |
JVMMemoryPressure |
用于集群中所有数据节点的 Java 堆的最大百分比。 OpenSearch 服务将实例内存的一半用于 Java 堆,堆大小不超过 32 GiB。您最多可以将实例的 RAM 垂直扩展至 64GiB,此时可以通过添加实例水平扩展。请参阅Amazon OpenSearch 服务的推荐 CloudWatch 警报。 |
SysMemoryUtilization |
使用中的实例内存的百分比。此指标的值较高是正常的,通常不表示集群存在问题。有关潜在性能和稳定性问题的更好指示,请参阅 JVMMemoryPressure 指标。 |
IndexingLatency |
节点中所有索引操作所用的总时间差,以毫秒为单位,介于分钟 N 和 minute () 之间。N-1 |
IndexingRate |
每分钟的索引操作数。 |
SearchLatency |
节点中所有搜索的总时间差,以毫秒为单位,介于分钟 N 和 minute () 之间。N-1 |
SearchRate |
数据节点上所有分片的每分钟搜索请求总数。 |
ThreadpoolSearchQueue |
搜索线程池中的排队任务数。如果队列大小一直很大,请考虑扩展您的集群。搜索队列的最大大小为 1000。 |
ThreadpoolWriteQueue |
写入线程池中的排队任务数。 |
ThreadpoolSearchRejected |
搜索线程池中的已拒绝任务数。如果此数字持续增长,请考虑扩展您的集群。 |
ThreadpoolWriteRejected |
写入线程池中的已拒绝任务数。 |
Cluster-level 活跃可用区中集群的指标
| 指标 | 说明 |
|---|---|
DataNodes |
活动分片和备用分片的总数。 |
DataNodesShards.active |
活动主分区和副本分区的总数。 |
DataNodesShards.unassigned |
未分配给集群中节点的分区数。 |
DataNodesShards.initializing |
正在初始化的分区数。 |
DataNodesShards.relocating |
正在重新定位的分区数。 |
可用区轮换指标
如果是 ActiveReads.,则该区处于活动状态。如果是 Availability-Zone = 1ActiveReads.,则该区处于待机状态。Availability-Zone =
0
时间点指标
亚马逊 OpenSearch 服务为时间点 (PIT) 搜索提供以下指标。
PIT 协调器节点统计数据(每个协调器节点)
| 指标 | 说明 |
|---|---|
CurrentPointInTime |
节点中活动 PIT 搜索上下文的数量。 |
TotalPointInTime |
自节点启动时间以来过期的 PIT 搜索上下文数量。 |
AvgPointInTimeAliveTime |
自节点启动时间以来 PIT 搜索上下文保持活动状态的平均时间。 |
HasActivePointInTime |
值为 1 表示自节点启动时间以来节点上活动的 PIT 上下文。值 0 表示没有。 |
HasUsedPointInTime |
值为 1 表示自节点启动时间以来节点上过期的 PIT 上下文。值 0 表示没有。 |
SQL 指标
亚马逊 OpenSearch 服务为 SQL 支持提供了以下指标。
| 指标 | 说明 |
|---|---|
SQLFailedRequestCountByCusErr |
由于客户端问题而失败的对 相关统计数据:总计 |
SQLFailedRequestCountBySysErr |
由于服务器问题或功能限制而失败的对 相关统计数据:总计 |
SQLRequestCount |
对 相关统计数据:总计 |
SQLDefaultCursorRequestCount |
类似于 相关统计数据:总计 |
SQLUnhealthy |
值为 1 表示 SQL 插件将返回 5xx 响应代码或将无效的查询 DSL 传递到 OpenSearch 来响应特定请求。其他请求将继续成功。值为 0 表示最近未失败。如果您看到持续值为 1,请排查您的客户端对插件发出的请求的问题。 相关统计数据:Maximum |
k-NN 指标
亚马逊 OpenSearch 服务包含 k 最近邻 (k-nn) 插件的以下指标。
| 指标 | 说明 |
|---|---|
KNNCacheCapacityReached |
Per-node 衡量是否已达到缓存容量的指标。此指标仅与近似 k-NN 搜索相关。 相关统计数据:Maximum |
KNNCircuitBreakerTriggered |
Per-cluster 断路器是否被触发的指标。如果任何节点返回 相关统计数据:Maximum |
KNNEvictionCount |
Per-node 由于内存限制或空闲时间而被从缓存中移出的图形数量的指标。不计入由于索引删除而发生的显式移出。此指标仅与近似 k-NN 搜索相关。 相关统计数据:总计 |
KNNGraphIndexErrors |
Per-node 指标,用于将文档 相关统计数据:总计 |
KNNGraphIndexRequests |
Per-node 指标,用于向图表中添加文档 相关统计数据:总计 |
KNNGraphMemoryUsage |
Per-node 当前缓存大小(内存中所有图形的总大小)的指标,以千字节为单位。此指标仅与近似 k-NN 搜索相关。 相关统计数据:Average |
KNNGraphQueryErrors |
Per-node 产生错误的图形查询数量的指标。 相关统计数据:总计 |
KNNGraphQueryRequests |
Per-node 图表查询次数的指标。 相关统计数据:总计 |
KNNHitCount |
Per-node 缓存命中次数的衡量指标。当用户查询已加载到内存中的图形时,会发生缓存命中。此指标仅与近似 k-NN 搜索相关。 相关统计数据:总计 |
KNNLoadExceptionCount |
Per-node 衡量在尝试将图形加载到缓存中时发生异常的次数的指标。此指标仅与近似 k-NN 搜索相关。 相关统计数据:总计 |
KNNLoadSuccessCount |
Per-node 衡量插件成功将图表加载到缓存中的次数的指标。此指标仅与近似 k-NN 搜索相关。 相关统计数据:总计 |
KNNMissCount |
Per-node 缓存未命中次数的衡量指标。当用户查询尚未加载到内存中的图形时,会发生缓存未命中。此指标仅与近似 k-NN 搜索相关。 相关统计数据:总计 |
KNNQueryRequests |
Per-node k-nn 插件收到的查询请求数量的指标。 相关统计数据:总计 |
KNNRemoteBuildEnabled |
指定是否启用该功能的二进制值。 相关统计数据:二进制 |
KNNRemoteIndexBuildFailureCount |
构建失败的总数。 相关统计数据:总计 |
KNNRemoteIndexBuildSuccessCount |
成功构建的总数。 相关统计数据:总计 |
KNNScriptCompilationErrors |
Per-node 脚本编译期间错误数量的指标。此统计数据仅与 k-NN 分数脚本搜索相关。 相关统计数据:总计 |
KNNScriptCompilations |
Per-node k-nn 脚本编译次数的指标。此值通常应为 1 或 0,但是如果包含已编译脚本的缓存已填充,k-NN 脚本可能会重新编译。此统计数据仅与 k-NN 分数脚本搜索相关。 相关统计数据:总计 |
KNNScriptQueryErrors |
Per-node 脚本查询期间的错误数量指标。此统计数据仅与 k-NN 分数脚本搜索相关。 相关统计数据:总计 |
KNNScriptQueryRequests |
Per-node 脚本查询总数的指标。此统计数据仅与 k-NN 分数脚本搜索相关。 相关统计数据:总计 |
KNNTotalLoadTime |
k-NN 将图形加载到缓存中所花费的时间(以纳秒为单位)。此指标仅与近似 k-NN 搜索相关。 相关统计数据:总计 |
VectorIndexBuildAccelerationOCU |
用于加速向量索引的 OpenSearch 计算单元 (OCU) 的数量。 相关统计数据:总计 |
Cross-cluster 搜索指标
Amazon OpenSearch 服务为跨集群搜索提供了以下指标。
源域指标
| 指标 | 维度 | 说明 |
|---|---|---|
CrossClusterOutboundConnections |
|
连接的节点数。如果响应中包含一个或多个跳过的域,则可使用此指标跟踪任何运行状况不佳的连接。如果此数值降至 0,则连接运行状况不佳。 |
CrossClusterOutboundRequests |
|
发送到目标域的搜索请求数。用于检查跨集群搜索请求的负载是否使您的域名不堪重负,将该指标中的任何峰值与任何 JVM/CPU峰值相关联。 |
目标域指标
| 指标 | 维度 | 说明 |
|---|---|---|
CrossClusterInboundRequests |
|
从源域接收的传入连接请求数。 |
添加 CloudWatch 警报,以防您意外断开连接。有关创建警报的步骤,请参阅基于静态阈值创建 CloudWatch警报。
Cross-cluster 复制指标
Amazon OpenSearch 服务为跨集群复制提供了以下指标。
| 指标 | 说明 |
|---|---|
ReplicationRate |
每秒复制操作的平均速率。该指标与 |
LeaderCheckPoint |
对于某个特定连接,涵盖所有复制索引的领导者索引检查点值的和。您可以使用此指标来度量复制延迟。 |
FollowerCheckPoint |
对于某个特定连接,涵盖所有复制索引的跟随者索引检查点值的和。您可以使用此指标来度量复制延迟。 |
ReplicationNumSyncingIndices |
复制状态为 |
ReplicationNumBootstrappingIndices |
复制状态为 |
ReplicationNumPausedIndices |
复制状态为 |
ReplicationNumFailedIndices |
复制状态为 |
|
|
关注者域上的复制传输请求数。传输请求是内部请求,每次调用复制 API 操作时都会发生。当关注者域轮询领导者域的变更时,也会发生这些请求。 |
|
|
领导者域上的复制传输请求数。传输请求是内部请求,每次调用复制 API 操作时都会发生。 |
AutoFollowNumSuccessStartReplication |
特定连接的复制规则已成功创建的跟随者索引的数量。 |
AutoFollowNumFailedStartReplication |
存在匹配模式时,复制规则未能创建的跟随者索引的数量。出现此问题的原因可能是远程集群上的网络问题或安全问题(即关联的角色不具有启动复制的权限)。 |
AutoFollowLeaderCallFailure |
从跟随者索引到领导者索引的提取新数据的查询是否有任何失败。值为 |
学习排名指标
Amazon OpenSearch 服务为学习排名提供了以下指标。
| 指标 | 说明 |
|---|---|
LTRRequestTotalCount |
排名请求的总计数。 |
LTRRequestErrorCount |
不成功请求的总计数。 |
LTRStatus.red |
跟踪运行插件所需的索引之一是否为红色。 |
LTRMemoryUsage |
插件使用的总内存。 |
LTRFeatureMemoryUsageInBytes |
学习排名功能字段使用的内存量(以字节为单位)。 |
LTRFeaturesetMemoryUsageInBytes |
所有学习排名功能集使用的内存量(以字节为单位)。 |
LTRModelMemoryUsageInBytes |
所有学习排名模型使用的内存量(以字节为单位)。 |
管道处理语言指标
Amazon OpenSearch 服务为管道处理语言提供了以下指标。
| 指标 | 说明 |
|---|---|
PPLFailedRequestCountByCusErr |
由于客户端问题而失败的对 |
PPLFailedRequestCountBySysErr |
由于服务器问题或功能限制而失败的对 |
PPLRequestCount |
对 |