本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
教程:使用 Amazon Ingestion 将数据提取到集合中 OpenSearch
本教程向您展示如何使用 Amazon OpenSearch Ingestion 配置简单管道并将数据提取到 Ama OpenSearch zon Serverless 集合中。管道是 OpenSearch Ingestion 配置和管理的资源。您可以使用管道筛选、丰富、转换、标准化和聚合数据,以便在 S OpenSearch ervice 中进行下游分析和可视化。
有关演示如何将数据提取到已配置的 OpenSearch 服务域的教程,请参阅。教程:使用 Amazon Ingestion 将数据提取到域中 OpenSearch
在本教程中,您将完成以下步骤:
在本教程中,您将创建以下资源:
-
管道将写入的名为
ingestion-collection的集合 -
名为
ingestion-pipeline-serverless的管道
所需的权限
要完成此教程,您的用户或角色必须已经附加基于身份的策略,并且具有以下最低权限。这些权限允许您创建管道角色和附加策略(iam:Create* 和 iam:Attach*)、创建或修改集合(aoss:*)以及使用管道(osis:*)。
此外,还需要多个 IAM 权限才能自动创建管道角色并将其传递给 OpenSearch Ingestion,这样它就可以向集合写入数据。
步骤 1:创建收藏夹
首先,创建集合,将数据摄取到其中。将集合命名为 ingestion-collection。
-
导航到亚马逊 OpenSearch 服务控制台,网址为https://console.aws.amazon.com/aos/home
。 -
选择左侧导航窗格中的集合,然后选择创建集合。
-
在 “无服务器生成” 字段中,选择 “切换到经典版”。
-
将集合命名为 ingestion-collection。
-
对于安全,选择标准创建。
-
在网络访问设置下,将访问类型更改为公有。
-
所有其他设置保留为默认值,然后选择 Next(下一步)。
-
现在,配置集合的数据访问策略。取消选择自动匹配访问策略设置。
-
对于定义方法,选择 JSON,然后将下面的策略粘贴到编辑器中。此策略具有两个作用:
-
允许管道角色写入集合。
-
允许从集合中读取。稍后,在将一些示例数据摄取到管道后,查询集合,以确保数据已成功摄取并写入索引。
[ { "Rules": [ { "Resource": [ "index/ingestion-collection/*" ], "Permission": [ "aoss:CreateIndex", "aoss:UpdateIndex", "aoss:DescribeIndex", "aoss:ReadDocument", "aoss:WriteDocument" ], "ResourceType": "index" } ], "Principal": [ "arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole", "arn:aws:iam::your-account-id:role/Admin" ], "Description": "Rule 1" } ]
-
-
修改
Principal元素以包含您的 Amazon Web Services 账户 ID。对于第二个主体,指定用户或角色,供您稍后用于查询集合。 -
选择下一步。将访问策略命名为 pipeline-collection-access,然后再次选择下一步。
-
查看集合配置并选择 Submit(提交)。
步骤 2:创建管道
现在您已拥有集合,即可创建管道。
创建管道
-
在亚马逊 OpenSearch 服务控制台中,从左侧导航窗格中选择 Pipelin es。
-
选择 Create pipeline(创建管道)。
-
选择空白管道,然后选择选择蓝图。
-
在本教程中,我们将创建使用 HTTP 源
插件的简单管道。插件接受 JSON 数组格式的日志数据。我们将指定一个 OpenSearch Serverless 集合作为接收器,并将所有数据提取到索引中。 my_logs在源菜单中,选择 HTTP。对于路径,输入 /logs。
-
在本教程中,为简单起见,我们将配置管道的公共访问权限。对于源网络选项,选择公共访问。有关配置 VPC 访问权限的更多信息,请参阅 为 Amazon OpenSearch Ingestion 管道配置 VPC 访问权限。
-
选择下一步。
-
对于处理器,输入日期并选择添加。
-
启用自收到之时起。将所有其他设置保留为默认值。
-
选择下一步。
-
配置接收器详细信息。对于OpenSearch 资源类型,选择集合(无服务器)。然后选择您在上一节中创建的 OpenSearch 服务集合。
将网络策略名称保留为默认值。在索引名称中,输入 my_logs。 OpenSearch 如果该索引尚不存在,Ingestion 会自动在集合中创建该索引。
-
选择下一步。
-
将管道命名为 ingestion-pipeline-serverless。将容量设置保留为默认值。
-
对于管道角色,选择创建和使用新的服务角色。管道角色为管道提供所需权限,使其能够向集合接收器写入数据并从基于拉取的源读取数据。选择此选项即表示您允许 OpenSearch Ingestion 为您创建角色,而不是在 IAM 中手动创建角色。有关更多信息,请参阅 在 Amazon OpenSearch Ingestion 中设置角色和用户。
-
对于服务角色名称后缀,请输入PipelineRole。在 IAM 中,角色采用的格式为
arn:aws:iam::。your-account-id:role/OpenSearchIngestion-PipelineRole -
选择下一步。检查您的管道配置,然后选择创建管道。管道需要 5-10 分钟才能变为活动状态。
步骤 3:摄取一些示例数据
当管道状态为 Active 时,您可以开始将数据摄取到管道。您必须使用 Signature 版本 4 对向管道发出的所有 HTTP 请求进行签名。使用诸如 Postman
注意
签署请求的主体必须具有 osis:Ingest IAM 权限。
首先,从管道设置页面获取摄取 URL:
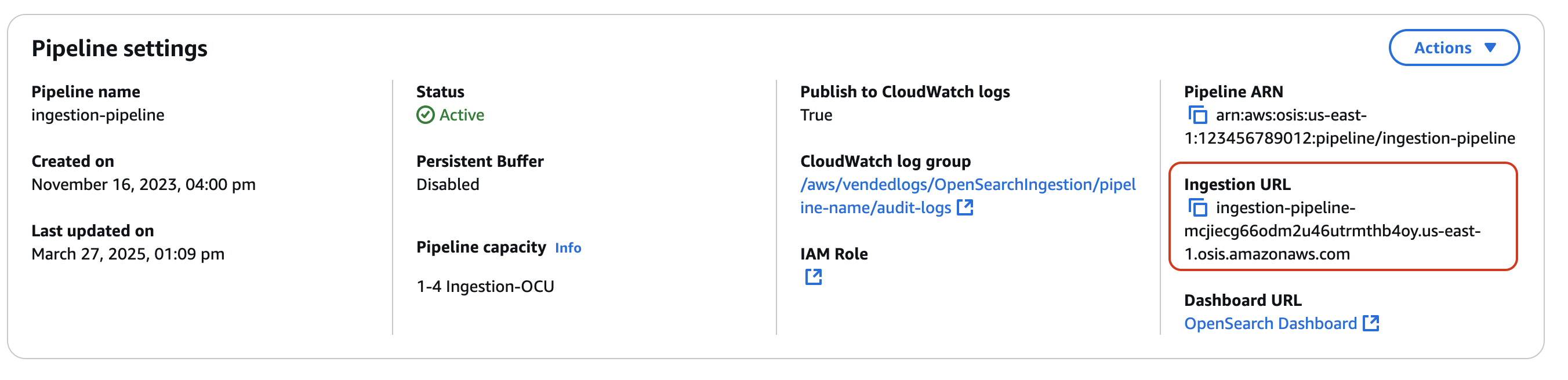
然后,将一些示例数据发送至摄取路径。以下示例请求使用 awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
您现在会看到 200 OK 响应。
现在,查询 my_logs 索引,确保成功摄取日志条目:
awscurl --service aoss --regionus-east-1\ -X GET \ https://collection-id.us-east-1.aoss.amazonaws.com/my_logs/_search | json_pp
示例响应:
{ "took":348, "timed_out":false, "_shards":{ "total":0, "successful":0, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"my_logs", "_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2023-04-26T05:22:16.204Z" } } ] } }
相关资源
本教程介绍了一个通过 HTTP 摄取单个文档的简单用例。在生产场景中,您将配置客户端应用程序(例如 Fluent Bit、Kubernetes 或 Collect OpenTelemetry or)以将数据发送到一个或多个管道。您的管道可能比本教程展示的简单示例复杂得多。
要开始配置您的客户端并摄取数据,请参阅以下资源: