本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Fine-tune 基础模型
您可以通过 Amazon SageMaker Canvas 访问的基础模型可以帮助您完成一系列通用任务。但是,如果您有特定的使用场景,并希望根据自己的数据自定义响应,则可以对基础模型进行微调。
要对基础模型进行微调,您需要提供一个由示例提示和模型响应组成的数据集。然后,根据数据训练基础模型。最后,经过微调的基础模型能够为您提供更具体的响应。
下面列出了可以在 Canvas 中进行微调的基础模型:
Titan Express
Falcon-7B
Falcon-7B-Instruct
Falcon-40B-Instruct
Falcon-40B
Flan-T5-Large
Flan-T5-Xl
Flan-T5-Xxl
MPT-7B
MPT-7B-Instruct
在微调模型时,您可以在 Canvas 应用程序中获取每个基础模型的更多详细信息。有关更多信息,请参阅 Fine-tune 该模型。
本主题介绍了如何在 Canvas 中微调基础模型。
开始前的准备工作
在微调基础模型之前,请确保您拥有 Canvas 中 Ready-to-use 模型的权限以及与 Amazon Bedrock 有信任关系的 Amazon Identity and Access Management 执行角色,这允许 Amazon Bedrock 在微调基础模型的同时担任您的角色。
在设置或编辑您的 Amazon SageMaker AI 域时,您必须 1) 打开 Canvas Ready-to-use 模型配置权限,以及 2) 创建或指定 Amazon Bedrock 角色,这是 A SageMaker I 与亚马逊 Bedrock 建立信任关系的 IAM 执行角色。有关配置这些设置的更多信息,请参阅 设置 Amazon C SageMaker anvas 的先决条件。
如果您希望使用自己的 IAM 执行角色(而不是让 A SageMaker I 代表您创建一个),则可以手动配置 Amazon Bedrock 角色。有关配置 IAM 执行角色与 Amazon Bedrock 信任关系的更多信息,请参阅 授予用户在 Canvas 中使用 Amazon Bedrock 和生成式人工智能功能的权限。
您还必须拥有格式化的数据集,用于微调大型语言模型(LLM)。以下是数据集的要求列表:
-
数据集必须是表格形式,至少包含两列文本数据:一列输入数据(包含对模型的示例提示)和一列输出数据(包含来自模型的示例响应)。
以下是示例:
Input Output 您的配送条款是什么?
我们为所有 50 美元以上的订单提供免费送货服务。50 美元以下的订单运费为 5.99 美元。
如何退货?
如需退货,请访问我们的退货中心并按照说明操作。您必须提供订单号和退货原因。
我的产品遇到了问题。我该怎么办?
请联系我们的客户支持团队,我们很乐意帮助您解决问题。
-
我们建议数据集至少包含 100 个文本对(输入和输出项目的对应行)。这样可以确保基础模型有足够的数据进行微调,并提高其响应的准确性。
-
每个输入和输出项最多包含 512 个字符。在微调基础模型时,任何较长的字符都会缩减到 512 个字符。
在微调 Amazon Bedrock 模型时,您必须遵守 Amazon Bedrock 配额。有关更多信息,请参阅《Amazon Bedrock 用户指南》中的模型自定义配额。
有关 Canvas 中一般数据集要求和限制的更多信息,请参阅 创建数据集。
Fine-tune 基础模型
您可以在 Canvas 应用程序中使用以下方法对基础模型进行微调:
-
在与基础模型的生成、提取和汇总内容聊天中,选择Fine-tune 模型图标 (
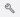 )。
)。 -
在与基础模型聊天时,如果你已经重新生成了两次或更多次响应,那么 Canvas 会为你提供Fine-tune 建模选项。以下界面截图显示了这种情况。

-
在我的模型页面上,您可以通过选择新建模型,然后选择Fine-tune 基础模型来创建新模型。
-
在Ready-to-use 模型主页上,您可以选择创建自己的模型,然后在创建新模型对话框中,选择Fine-tune 基础模型。
-
在 Data Wrangler 选项卡中浏览数据集时,您可以选择一个数据集,然后选择创建模型。然后,选择Fine-tune 基础模型。
开始微调模型后,请执行以下操作:
选择数据集。
在微调模型的选择选项卡中,您可以选择要训练基础模型的数据。
选择现有数据集或创建符合 开始前的准备工作 部分所列要求的新数据集。有关如何创建数据集的更多信息,请参阅 创建数据集。
选择或创建数据集后,如果准备继续,请选择选择数据集。
Fine-tune 该模型
选择数据后,您就可以开始训练和微调模型了。
在“Fine-tune”选项卡中,进行以下操作:
(可选)选择了解有关我们的基础模型的更多信息,以获取有关每个模型的更多信息,帮助您决定部署哪个或哪些基础模型。
对于最多选择 3 个基础模型,打开下拉菜单并勾选最多 3 个基础模型(最多 2 个 JumpStart 模型和 1 个 Amazon Bedrock 模型),您想在训练作业中对其进行微调。通过微调多个基础模型,您可以比较它们的性能,并最终选择最适合您的使用场景的模型作为默认模型。有关默认模型的更多信息,请参阅 在模型排行榜中查看候选模型。
对于选择输入列,请在数据集中选择包含示例模型提示的文本数据列。
对于选择输出列,请在数据集中选择包含示例模型响应的文本数据列。
-
(可选)要配置训练作业的高级设置,请选择配置模型。有关高级模型构建设置的更多信息,请参阅 高级模型构建配置。
在弹出的配置模型窗口中,执行以下操作:
对于超参数,您可以为所选的每个模型调整历时计数、批次大小、学习率和学习率预热步骤。有关这些参数的更多信息,请参阅 JumpStart 文档中的超参数部分。
对于数据拆分,您可以指定数据在训练集和验证集之间的分割百分比。
对于最大作业运行时间,您可以设置 Canvas 运行构建作业的最大时间。此功能仅适用于 JumpStart 基础模型。
配置完设置后,选择保存。
选择Fine-tune开始训练您选择的基础模型。
微调作业开始后,您就可以离开此页面。当模型在我的模型页面上显示为就绪时,它就可以使用了,您现在可以分析微调后的基础模型的性能。
分析微调后的基础模型
在微调后的基础模型的分析选项卡上,您可以看到模型的性能。
此页面上的概述选项卡会显示复杂度和损失分数,以及可视化模型在训练过程中随时间推移而不断改进情况的分析结果。下面的截图显示了概述选项卡。
在此页面上,您可以看到以下可视化效果:
复杂度曲线衡量模型预测序列中下一个单词的效果,或模型输出的语法程度。理想情况下,随着模型在训练过程中不断改进,分数也会随之降低,并形成一条随时间推移而降低并趋于平缓的曲线。
损失曲线量化了正确输出与模型预测输出之间的差异。如果损失曲线随着时间的推移逐渐减小并趋于平缓,则表明模型准确预测的能力正在提高。
高级指标选项卡会显示模型的超参数和其他指标。类似下面的界面截图:
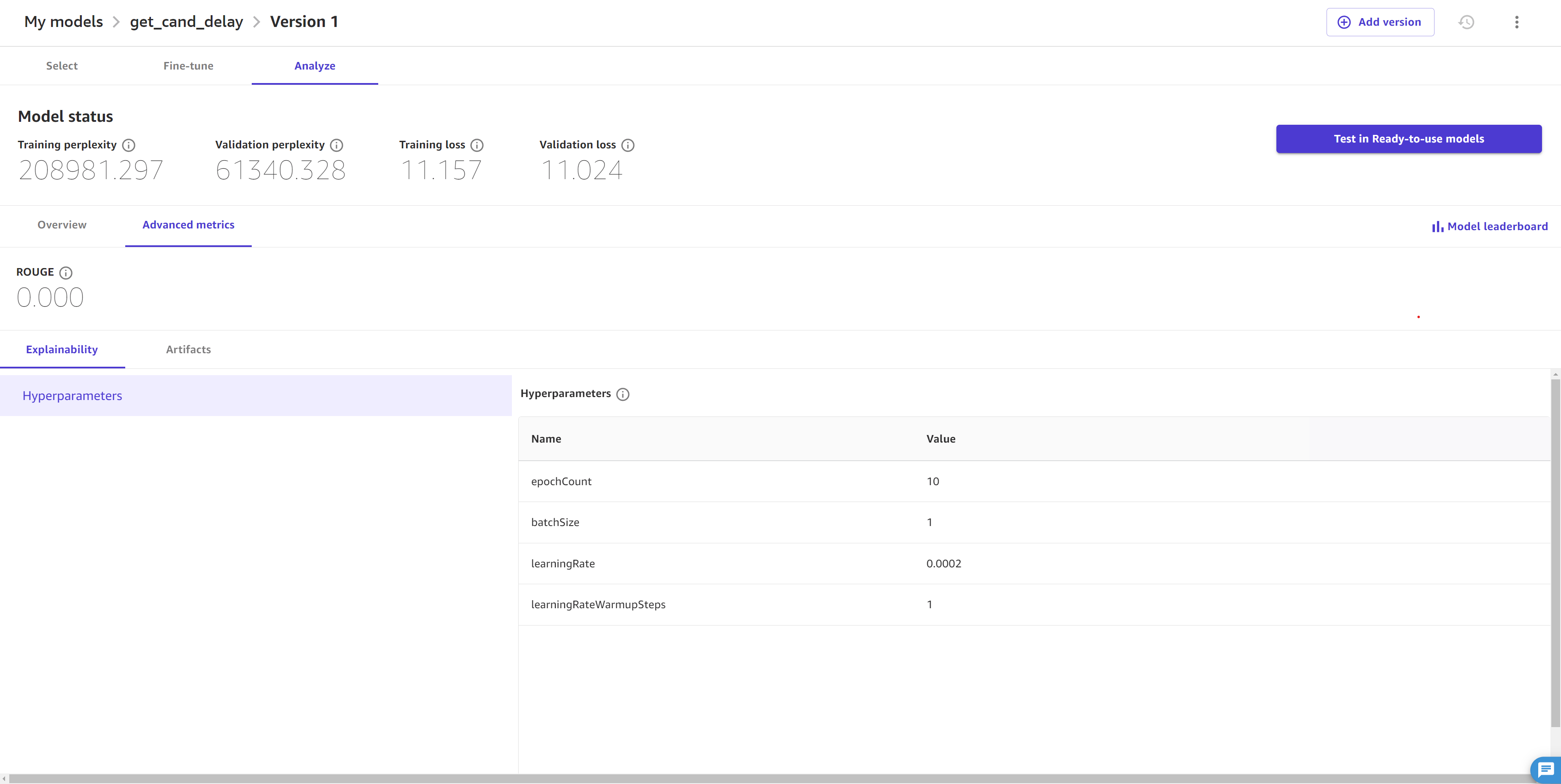
高级指标选项卡包含以下信息:
-
可解释性部分包含超参数,这些参数是在作业前设置的值,用于指导模型的微调。如果您没有在 Fine-tune 该模型 部分的模型高级设置中指定自定义超参数,则 Canvas 会为您选择默认超参数。
对于 JumpStart 模型,您还可以查看高级指标 ROUGE(Gisting 评估的Recall-Oriented 未完成研究)
,它评估模型生成的摘要的质量。它衡量的是模型总结段落要点的能力。 构件部分为您提供了微调作业期间生成的构件链接。您可以访问保存在 Amazon S3 中的训练和验证数据,以及模型评测报告的链接(要了解更多信息,请参阅以下段落)。
要获得更多模型评估见解,您可以下载使用 Clari SageMaker f y 生成的报告,该功能可以帮助您检测模型和数据中的偏差。首先,在页面底部选择生成评估报告,生成报告。生成报告后,您可以选择下载报告或返回构件部分下载完整报告。
您还可以访问 Jupyter Notebook,了解如何用 Python 代码复制微调作业。您可以利用它来复制或对微调作业进行编程更改,或者深入了解 Canvas 如何微调模型。要了解有关模型笔记本以及如何访问它们的更多信息,请参阅 下载模型笔记本。
有关如何解释微调后的基础模型分析选项卡中信息的更多信息,请参阅主题 模型评测。
在分析了概述和高级指标选项卡后,您还可以选择打开模型排行榜,它将显示构建过程中训练的基础模型列表。损失分数最低的模型被认为是性能最好的模型,并被选为默认模型,也就是您在分析选项卡中看到的分析模型。您只能测试和部署默认模型。有关模型排行榜以及如何更改默认模型的更多信息,请参阅 在模型排行榜中查看候选模型。
测试聊天中微调后的基础模型
在分析了微调后的基础模型的性能后,您可能想对其进行测试,或将其响应与基础模型进行比较。您可以通过生成、提取和总结内容功能测试聊天中微调后的基础模型。
选择以下方法之一,与微调后的模型开始聊天:
在微调模型的分析选项卡上,选择在 Ready-to-use 基础模型中测试。
在画布Ready-to-use 模型页面上,选择生成、提取和汇总内容。然后,选择新建聊天,然后选择要测试的模型版本。
模型会在聊天中启动,您可以像任何与其他基础模型一样与它互动。您可以在聊天中添加更多模型,并比较它们的输出结果。有关聊天功能的更多信息,请参阅 C SageMaker anvas 中的生成式 AI 基础模型。
运行微调后的基础模型
在 Canvas 中对模型进行微调后,您可以执行以下操作:
将模型注册到模型注册中心, SageMaker 以便集成到您的组织的 mLOPs 流程中。有关更多信息,请参阅 在 SageMaker AI 模型注册表中注册模型版本。
将模型部署到 A SageMaker I 终端节点,然后从您的应用程序或网站向模型发送请求以获取预测(或推断)。有关更多信息,请参阅 将模型部署到端点。
重要
您只能注册和部署 JumpStart 基于微调的基础模型,而不能注册和部署基于 Amazon Bedrock 的模型。