本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Clarify 进行公平性、模型可解释性和偏见检测 SageMaker
您可以使用 Amazon SageMaker Clarify 来了解公平性和模型的可解释性,并解释和检测模型中的偏差。您可以配置 Clari SageMaker fy 处理作业来计算偏差指标和特征归因,并生成模型可解释性报告。 SageMaker Claride 处理任务是使用专门的 Clarif SageMaker y 容器镜像实现的。下一页介绍了 Cl SageMaker arify 的工作原理以及如何开始分析。
什么是机器学习预测的公平性和模型可解释性?
机器学习 (ML) 模型有助于在金融服务、医疗保健、教育和人力资源等领域做出决策。策略制定者、监管者和倡导者提高了对人工智能和数据驱动系统带来的道德和策略挑战的认识。Ama SageMaker zon Clarify 可以帮助您了解您的机器学习模型做出特定预测的原因,以及这种偏见是否会影响训练或推理期间的预测。 SageMaker Clarify 还提供了可以帮助您构建偏见更少、更易于理解的机器学习模型的工具。 SageMaker Clarify 还可以生成模型治理报告,您可以将其提供给风险和合规团队以及外部监管机构。使用 C SageMaker larify,您可以执行以下操作:
-
检测模型预测中的偏差并帮助解释。
-
识别预训练数据中的偏差类型。
-
识别训练后数据中的偏差类型,这些偏差可能在训练过程中或模型投入生产时出现。
SageMaker Clarify 有助于解释您的模型如何使用特征归因进行预测。它还可以监控正在生产的推理模型,以发现偏差和功能归因漂移。这些信息可以在以下方面为您提供帮助:
-
监管 - 策略制定者和其他监管者可能会担心使用 ML 模型输出的决策会产生歧视性影响。例如,人工智能模型可能会编码偏见并影响自动决策。
-
商业:监管领域可能需要对 ML 模型如何进行预测做出可靠的解释。对于依赖可靠性、安全性和合规性的行业来说,模型的可解释性可能尤为重要。这些领域包括金融服务、人力资源、医疗保健和自动运输。例如,贷款应用程序可能需要向贷款人员、预测人员和客户解释 ML 模型是如何做出某些预测的。
-
数据科学:当数据科学家和 ML 工程师能够确定模型是否根据噪声或无关功能进行推断时,他们就能调试和改进 ML 模型。他们还可以了解其模型的局限性以及模型可能遇到的故障模式。
有关展示如何为欺诈性汽车索赔设计和构建完整的机器学习模型的博客文章,该模型将Clarify集成 SageMaker 到 SageMaker 人工智能管道中,请查看架构师并通过以下方式构建完整的机器学习生命周期 Amazon:端到端的Amazon SageMaker AI
评估 ML 生命周期中公平性和可解释性的最佳做法
公平是一个过程:偏见和公平的概念取决于它们的应用。偏差的测量和偏差指标的选择可能受社会、法律和其他非技术因素的影响。要成功采用具有公平意识的多边借贷方法,就必须在主要利益相关方之间达成共识并开展合作。这些可能包括产品、政策、法律、工程、 AI/ML 团队、最终用户和社区。
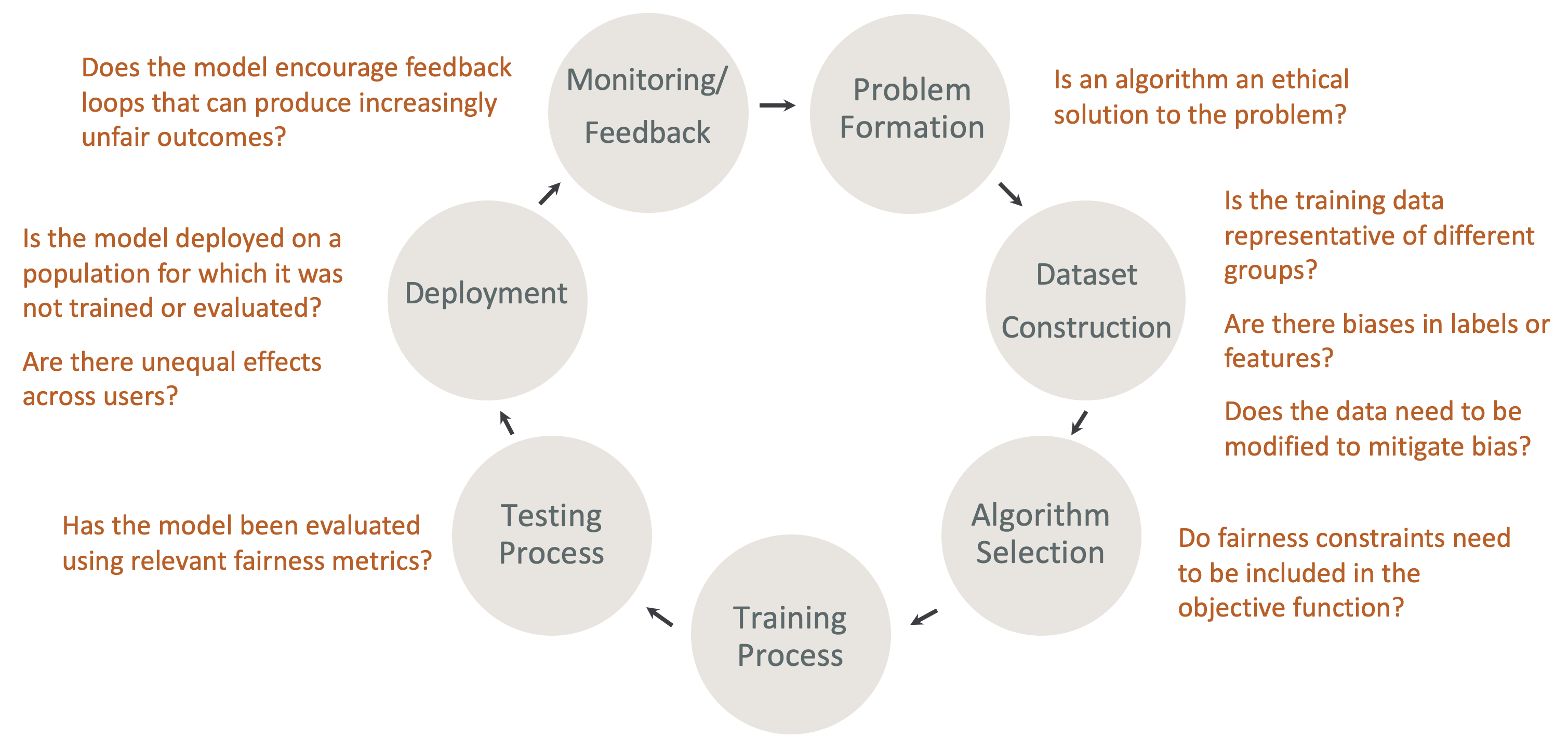
在人工智能生命周期中设计公平性和可解释性:在人工智能生命周期的每个阶段都要考虑公平性和可解释性。这些阶段包括问题形成、数据集构建、算法选择、模型训练过程、测试过程、部署以及监控和反馈。重要的是要有正确的工具来进行这种分析。我们建议在 ML 生命周期内提出以下问题:
-
这种模式是否会鼓励产生越来越不公平结果的反馈循环?
-
算法是解决问题的道德方案吗?
-
训练数据是否代表不同群体?
-
标签或功能是否存在偏见?
-
是否需要修改数据以减少偏差?
-
目标函数中是否需要包含公平约束条件?
-
是否使用相关的公平性指标对模型进行了评估?
-
对不同用户的影响是否不平等?
-
是否在未经训练或评估的人群中部署了模型?
SageMaker 人工智能解释和偏见文档指南
在训练模型之前和之后,数据中都可能出现偏差并对其进行测量。 SageMaker Clarify 可以为训练后的模型预测以及部署到生产环境的模型提供解释。 SageMaker Clarify 还可以监控生产中的模型的基线解释性归因是否存在任何偏差,并在需要时计算基线。使用 SageMaker Clarify 解释和检测偏见的文档结构如下:
-
有关设置偏差和可解释性处理任务的信息,请参阅 配置 Clari SageMaker fy 处理 Job。
-
有关在用于训练模型之前检测预处理数据偏差的信息,请参阅 Pre-training 数据偏差。
-
有关检测训练后数据和模型偏差的信息,请参阅 Post-training 数据和模型偏差。
-
有关解释训练后模型预测的模型无关功能归因方法的信息,请参阅 模型可解释性。
-
有关监测功能贡献偏离模型训练期间建立的基线的信息,请参阅 生产中模型的功能归属漂移。
-
有关监测正在生产的基线漂移模型的信息,请参阅 生产中模型的偏压飘移。
-
有关从 SageMaker AI 终端节点实时获取解释的信息,请参阅使用 Clarify 进行在线解释 SageMaker。
SageMaker 澄清处理任务的工作原理
您可以使用 Cl SageMaker arify 来分析数据集和模型的可解释性和偏差。Cl SageMaker arify 处理任务使用 Cl SageMaker arify 处理容器与包含您的输入数据集的 Amazon S3 存储桶进行交互。您还可以使用 Cl SageMaker arify 来分析部署到 A SageMaker I 推理端点的客户模型。
下图显示了 Clari SageMaker fy 处理任务如何与您的输入数据交互,也可以与客户模型进行交互。这种交互取决于所执行的特定分析类型。Cl SageMaker arify 处理容器从 S3 存储桶获取用于分析的输入数据集和配置。对于某些分析类型,包括特征分析,Clar SageMaker ify 处理容器必须向模型容器发送请求。然后,它从模型容器发送的响应中检索模型预测。之后,Clari SageMaker fy 处理容器进行计算并将分析结果保存到 S3 存储桶中。
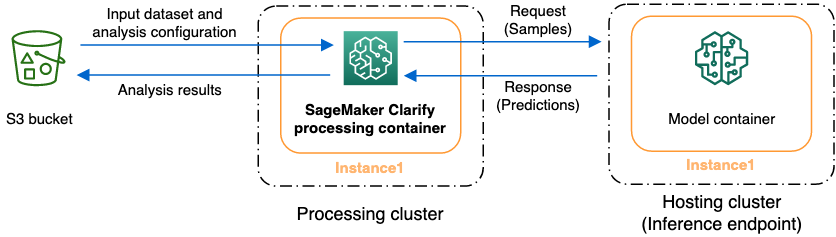
您可以在机器学习工作流程生命周期的多个阶段运行 Clarify 处理作业。 SageMaker SageMaker Clarify 可以帮助您计算以下分析类型:
-
Pre-training 偏见指标。这些指标可以帮助您了解数据中的偏差,从而解决偏差问题,并在更公平的数据集上训练模型。有关预训练偏差指标的信息,请参阅 Pre-training 偏见指标。要运行一项作业以分析训练前偏差指标,必须向 分析配置文件 提供数据集和 JSON 分析配置文件。
-
Post-training 偏见指标。这些指标可帮助您了解算法、超参数选择引入的任何偏差,或流程早期不明显的任何偏差。有关训练后偏差指标的更多信息,请参阅Post-training 数据和模型偏差指标。 SageMaker 除了数据和标签之外,Clarify 还使用模型预测来识别偏差。要运行一项作业以分析训练后偏差指标,必须提供数据集和 JSON 分析配置文件。配置应包括模型或端点名称。
-
Shapley 值,它可以帮助您了解功能对模型预测结果的影响。有关 Shapley 值的更多信息,请参阅 使用 Shapley 值的特征归因。此特征需要经过训练的模型。
-
局部依存图 (PDP),它可以帮助您了解如果改变一个功能的值,预测的目标变量会发生多大变化。有关 PDP 的更多信息,请参阅 部分依赖图 (PDP) 分析。该功能需要训练有素的模型。
SageMaker Clarify 需要模型预测来计算训练后的偏差指标和特征归因。您可以提供端点,否则 C SageMaker larify 将使用您的模型名称(也称为影子端点)创建一个临时端点。计算完成后, SageMaker Clarify 容器会删除影子端点。简而言之,Clari SageMaker fy 容器完成了以下步骤:
-
验证输入和参数。
-
创建影子端点(如果提供了模型名称)。
-
将输入数据集加载到数据框中。
-
如有必要,从端点获取模型预测。
-
计算偏差指标和特征归因。
-
删除影子端点。
-
生成分析结果。
Cl SageMaker arify 处理作业完成后,分析结果将保存在您在作业的处理输出参数中指定的输出位置。这些结果包括 JSON 文件(其中包含偏差指标和全局特征归因)、可视化报告以及用于局部特征归因的其他文件。您可以从输出位置下载结果并进行查看。
有关偏见指标、可解释性以及如何解释这些指标的更多信息,请参阅了解 Ama SageMaker zon Clarify 如何帮助检测偏见
示例笔记本
以下各节包含笔记本,可帮助您开始使用 C SageMaker larify,将其用于特殊任务(包括分布式作业中的任务)以及计算机视觉。
开始使用
以下示例笔记本展示了如何使用 Clar SageMaker ify 开始执行可解释性和模型偏差任务。这些任务包括创建处理作业、训练机器学习 (ML) 模型和监控模型预测:
-
使用 Ama SageMaker zon Clarify 进行可解释性和偏见检测
— 使用 SageMaker Clarify 创建处理任务来检测偏见并解释模型预测。 -
监控偏见漂移和特征归因偏差 Amazon C SageMaker larif
y — 使用 Amazon SageMaker 模型监视器监控偏差和特征归因随时间推移而发生的偏差漂移。 -
如何将 JSON 行格式的数据集读
入 Clarif SageMaker y 处理作业。 -
缓解偏差,训练另一个无偏模型,然后将其放入模型注册表中
— 使用合成少数派 Over-sampling技术 (SMOTE) 和 SageMaker Clarify 来缓解偏差,训练另一个模型,然后将新模型放入模型注册表中。该示例笔记本还展示了如何将新模型构件(包括数据、代码和模型元数据)放入模型注册表。本笔记本是该系列文章的一部分,该系列展示了如何将 Clarify 集成 SageMaker 到 A rchitect 中描述 SageMaker 的人工智能管道中,并通过 Amazon博客文章构建完整的机器学习生命周期 。
特殊情况
以下笔记本向您展示了如何使用 Clari SageMaker fy 来处理特殊情况,包括在您自己的容器内以及执行自然语言处理任务:
-
使用 SageMaker Clarify(自带容器)实现公平性和可解释性 — 构建自己的模型和容器
,这些模型和容器可以与 SageMaker Clarify 集成,以衡量偏差并生成可解释性分析报告。本示例笔记本还介绍了关键术语,并向您展示了如何通过 SageMaker Studio Classic 访问报告。 -
Clarify Spark 分布式处理的公平性和可解释性
— 使用分布式处理来运行 Clarify 作业,该作业可测量数据集的训练前偏差和模型的训练后偏差。 SageMaker SageMaker 本示例笔记本还向您展示了如何获取模型输出中输入特征重要性的解释,以及如何通过 SageMaker Studio Classic 访问可解释性分析报告。 -
使用 Clarif@@ y 进行 SageMaker 可解释性——部分依赖图 (PDP)
— 使用 Clarif SageMaker y 生成 PDP 并访问模型可解释性报告。 -
使用 C SageMaker larify 自然语言处理 (NLP) 可解释性解释文本情感分析
— 使用 Clarify 进行 SageMaker 文本情感分析。
这些笔记本电脑已经过验证,可以在亚马逊 SageMaker Studio Classic 中运行。如果您需要了解如何在 Studio Classic 中打开笔记本,请参阅 创建或打开 Amazon SageMaker Studio 经典笔记本电脑。如果系统提示您选择内核,请选择 Python 3 (Data Science)。